初学Python的时候,就写过一篇利用Python的第三方库进行好友头像拼接,itchat itchat库初探--微信好友全头像的拼接,最近又研究了下itchat和matplotlib,目前实现了对微信好友头像、性别、区域、个性签名的采集及展示。
本文就来详细介绍一下这个库的用法和一些核心逻辑实现。
1.微信登录
- 三行代码实现登录,为了避免我们频繁扫描二维码登录,这里我们加入
hotReload=True
import itchat
itchat.auto_login(hotReload=True)
itchat.dump_login_status()
- 好友信息获取
we_friend = itchat.get_friends(update=True)[:]
这里的we_friend是好友的信息的列表,每一个好友字典的 key 如下表
| key | 备注 |
|---|---|
| UserName | 微信系统内的用户编码标识 |
| NickName | 好友昵称 |
| Sex | 性别 |
| Province | 省份 |
| City | 城市 |
| HeadImgUrl | 微信系统内的头像URL |
| RemarkName | 好友的备注名 |
| Signature | 个性签名 |
有了key对应的值,我们就好处理了。
2.好友性别
这里顺便提一下:如果sex=1则代表男性,sex=2代表女性
total = len(we_friend[1:])
for fri_info in we_friend[1:]:
sex = fri_info['sex']
# 如果sex=1 代表男性 sex=2代表女性
if sex == 1:
man += 1
elif sex == 2:
woman += 1
else:
other += 1
统计出男生、女生的以及总人数后,占比自然而然就出来了,为了更好的展示男女比例,我们以饼图展示。
- 绘制饼图
man_ratio = int(man)/total * 100
woman_ratio = int(woman)/total * 100
other_ratio = int(other)/total * 100
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.figure(figsize=(5, 5)) # 绘制的图片为正圆
sex_li = ['男', '女', '其他']
radius = [0.01, 0.01, 0.01] # 设定各项距离圆心n个半径
colors = ['red', 'yellowgreen', 'lightskyblue']
proportion = [man_ratio, woman_ratio, other_ratio]
plt.pie(proportion, explode=radius, labels=sex_li, colors=colors, autopct='%.2f%%') # 绘制饼图
# 加入图例 loc = 'upper right' 位于右上角 bbox_to_anchor=[0.5, 0.5] # 外边距 上边 右边 borderaxespad = 0.3图例的内边距
plt.legend(loc="upper right", fontsize=10, bbox_to_anchor=(1.1, 1.1), borderaxespad=0.3)
# 绘制标题
plt.title('微信好友性别比例')
# 展示
plt.show()
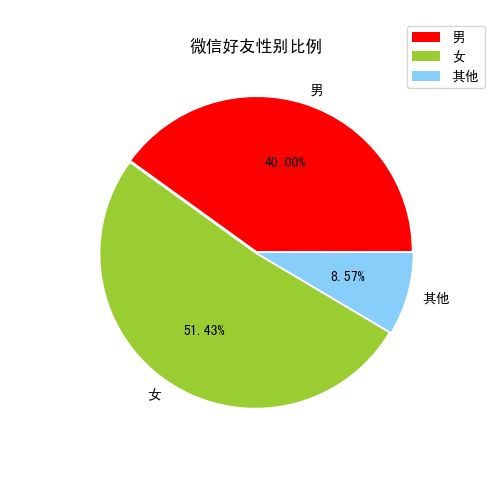
作为一个码农、程序猿,还能有这么多女性好友实属不易啊。敏感的我,看了这个比例深深地感觉到了不安,(此图女朋友不可见)另外,怎么还有一些未知生物的存在...
友情提醒:matplotlib中文乱码这个问题一直存在,这里记录下如何解决matplotlib中文乱码
- 准备好想要使用的中文字体,这里我用的是SimHei,附下载地址:中文字体下载
- 找到matplotlib的文件位置
import matplotlib
print(matplotlib.matplotlib_fname()) # 查看路径
进入上方打印的路径
把刚才下载的字体文件解压放入
/usr/local/lib/python3.5/dist-packages/matplotlib/mpl-data/fonts/ttf目录返回上级目录,修改matplotlibrc文件,取消相关注释,并在
font.serif加入刚才下载的字体
font.family : sans-serif
font.serif : SimHei, DejaVu Serif, Bitstream Vera Serif, New Century Schoolbook, Century Schoolbook L, Utopia, ITC Bookman, Bookman, Nimbus Roman No9 L, Times New Roman, Times, Palatino, Charter, serif
- 删除matplotlib缓存。
在terminal中:cd ~/.cache/matplotlib
把.cache下面的matplotlib文件夹删除。
$ rm -rf matplotlib
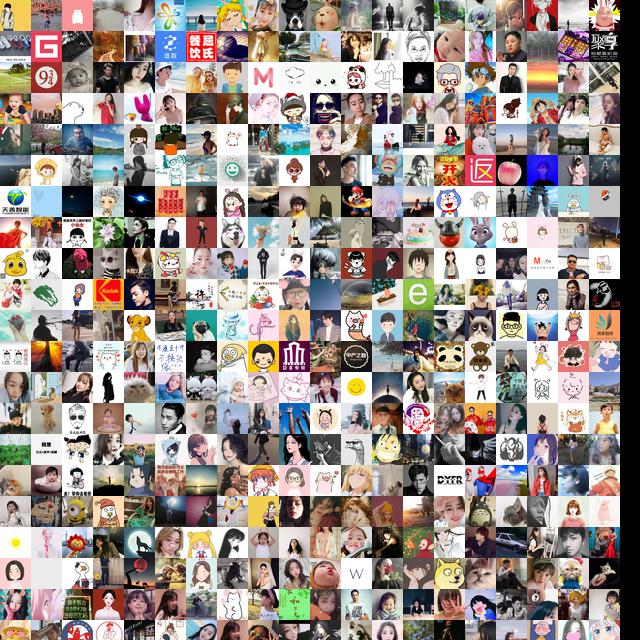
3.微信好友头像
这里其实看过我之前文章的应该知道,其实头像的拼接主要分为两部分
- 1.采集所有好友头像保存本地,
import os
num = 0
pwd_path = os.path.abspath(os.path.dirname(os.getcwd()))
desc_photos = os.path.join(pwd_path, 'res/photos')
for i in friends:
img = itchat.get_head_img(userName=i["UserName"])
file_image = open(desc_photos + "/" + str(num) + ".jpg", 'wb')
file_image.write(img)
file_image.close()
num += 1
- 2.对所有头像进行拼接
ls = os.listdir(desc_photos)
each_size = int(math.sqrt(float(640 * 640) / len(ls))) # 算出每张图片的大小多少合适
lines = int(640 / each_size)
image = Image.new('RGBA', (640, 640)) # 创建640*640px的大图
x = 0
y = 0
for i in range(0, len(ls) + 1):
try:
img = Image.open(desc_photos + "/" + str(i) + ".jpg")
except IOError:
print("Error")
else:
img = img.resize((each_size, each_size), Image.ANTIALIAS)
image.paste(img, (x * each_size, y * each_size)) # 粘贴位置
x += 1
if x == lines: # 换行
x = 0
y += 1
image.save(desc_full + "/好友头像拼接图.jpg")
密集恐惧症患者请忽略!!!
4.微信好友地区分布
-- 获取区域及城市
prov_dict, city_dict = {}, {}
for fri_info in we_friend[1:]:
prov = fri_info['province']
city = fri_info['city']
if prov and prov not in prov_dict.keys():
prov_dict[prov] = 1
elif prov:
prov_dict[prov] += 1
if city and city not in city_dict.keys():
city_dict[city] = 1
elif city:
city_dict[city] += 1
由于城市太多,我们取好友数量排名前十的城市及区域进行展示,感兴趣的可以稍微改下代码,就可以展示所有区域人数。
排序这里我用了Python的sorted()函数,列表的每个元素都为二维元组,key参数传入了一个lambda函数,其x就代表列表里的每一个元素,然后分别利用索引返回元素内的第一个和第二个元素,这就代表了sorted()函数利用哪一个元素进行排列。而reverse决定是正序还是倒序,默认为False。
# 区域Top10
prov_dict_top10 = sorted(prov_dict.items(), key=lambda x: x[1], reverse=True)[0:10]
# 城市Top10
city_dict_top10 = sorted(city_dict.items(), key=lambda y: y[1], reverse=True)[0:10]
- 区域、城市柱形图展示,由于思路代码是一致的,所以这里只展示区域的代码
prov_nm, prov_num = [], [] # 省会名 + 数量
for prov_data in prov_dict_top10:
prov_nm.append(prov_data[0])
prov_num.append(prov_data[1])
pwd_path = os.path.abspath(os.path.dirname(os.getcwd()))
desc_full = os.path.join(pwd_path, 'res')
colors = ['#00FFFF', '#7FFFD4', '#F08080', '#90EE90', '#AFEEEE',
'#98FB98', '#B0E0E6', '#00FF7F', '#FFFF00', '#9ACD32']
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
index = range(len(prov_num))
plt.bar(index, prov_num, color=colors, width=0.5, align='center')
plt.xticks(range(len(prov_nm)), prov_nm) # 横坐轴标签
for x, y in enumerate(prov_num):
# 在柱子上方1.2处标注值
plt.text(x, y + 1.2, '%s' % y, ha='center', fontsize=10)
plt.ylabel('省会好友人数') # 设置纵坐标标签
prov_title = '微信好友区域Top10'
plt.title(prov_title) # 设置标题
plt.savefig(desc_full + '/微信好友区域Top10') # 保存图片
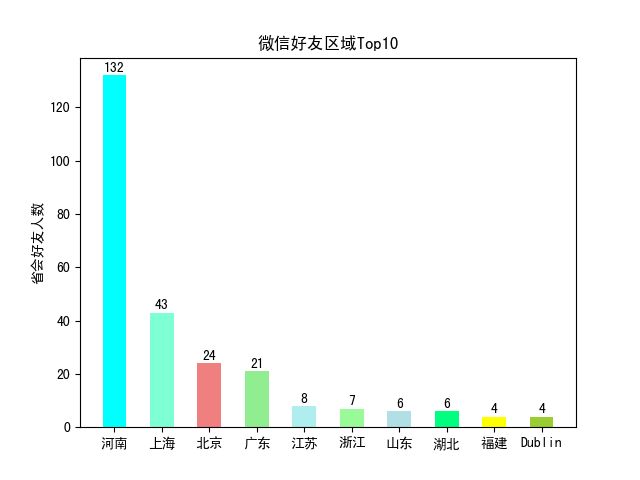
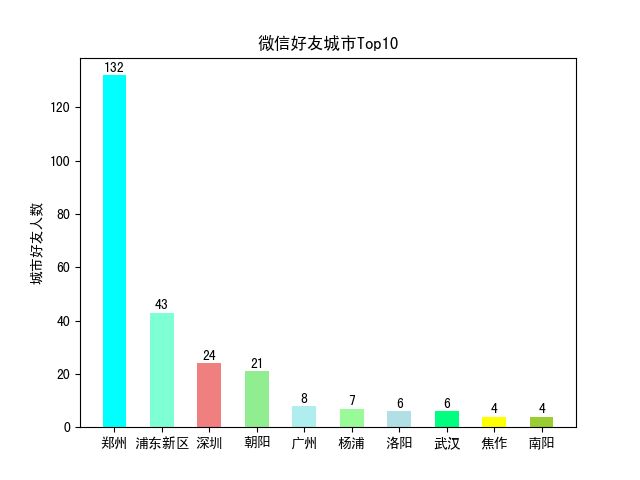
通过柱形图展示,可以清晰看到我的好友主要分布在河南和上海,借此不难推测出我的工作地址以及户籍所在地。
5.微信好友个性签名情感分析及词云图展示
这里使用了常用的中文分词库jieba,词云图的背景采用了萌萌大小猪佩奇(´๑•_•๑)
- 分词
sign_li = []
rule = re.compile("1f\d+\w*|[<>/=]") # 定义正则规则
for fri_info in we_friend[1:]:
signature = fri_info['signature']
if signature:
sign_deal = signature.replace('\n', '').replace('\t', '').replace(' ', '')\
.replace("span", "").replace("class", "").replace("emoji", "")
sign = rule.sub("", sign_deal)
sign_li.append(sign)
- 制作词云图
pwd_path = os.path.abspath(os.path.dirname(os.getcwd()))
conf_path = os.path.join(pwd_path, 'conf/')
comment_txt = ''
back_img = plt.imread(conf_path + '/peiqi.jpg')
cloud = WordCloud(font_path=conf_path + '/simhei.ttf', # 若是有中文的话,这句代码必须添加,不然会出现方框,不出现汉字
background_color="white", # 背景颜色
max_words=5000, # 词云显示的最大词数
mask=back_img, # 设置背景图片
max_font_size=100, # 字体最大值
random_state=42,
width=360, height=591, margin=2, # 设置图片默认的大小,但是如果使用背景图片的话,保存的图片大小将会按照其大小保存,margin为词语边缘距离
)
for li in comment:
comment_txt += ' '.join(jieba.cut(li, cut_all=False))
wc = cloud.generate(comment_txt)
image_colors = ImageColorGenerator(back_img)
plt.figure("wordc")
plt.imshow(wc.recolor(color_func=image_colors))
wc.to_file(res_full + '好友个性签名词云图.png')

最初,只想做一个简单的词云图,但是看到这个词云图中梦想、努力、专注、尊重、希望这个几个词以后,感觉到我的好友生活态度还是蛮积极向上的,就想不如再做一个简单的情感分析,说干就干。
sentimentslist = []
for li in comment:
if len(li) > 0:
s = SnowNLP(li)
print(li, s.sentiments)
sentimentslist.append(s.sentiments)
fig1 = plt.figure("sentiment")
plt.hist(sentimentslist, bins=np.arange(0, 1, 0.02))
plt.savefig(res_full + '好友签名情感分析')
plt.show()
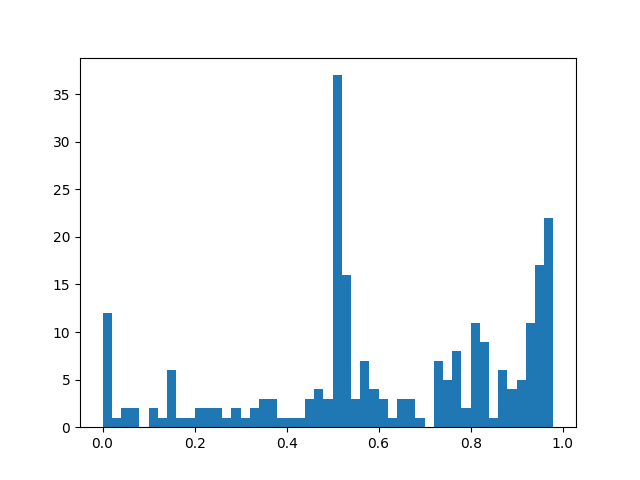
从图中可以看出,正向情感要远远多于负向情感的数据,积极乐观的人往往都在一个圈子,果然是物以类聚,人以群分啊。
完整代码以上传Github,期待您的Star。
如果你觉得我的文章还可以,可以关注我的微信公众号:Python攻城狮
