Oracle数据库中SQL语句用法
Copyright © 2019 Linyer. All Rights Reserved
目录
- 第1章:编写基本的SQL SELECT语句
- 基本SELECT语句
- 选择特定列
- 算术运算符
- 列名别名
- 连接运算符
- 文字字符串
- 重复行
- 第2章:限制和排序数据
- 限制选定的行
- 字符串和日期
- 比较条件
- 运算符比较
- 其他比较
- between...and...
- in(set)
- like
- is null
- 逻辑条件
- ORDER BY子句
- 第3章:单行函数
- 大小写处理函数
- 字符处理函数
- 数字函数
- 处理日期
- 日期函数
- 函数转换
- TO_CHAR处理日期
- TO_CHAR 处理数字
- 常规函数
- NVL 函数
- NVL2 函数
- NULLIF 函数
- COALESCE函数
- 条件表达式
- CASE 表达式
- DECODE 表达式
- 第4章:显示多个表中的数据
- 等值联结
- 非等值联结
- 外联结
- 自联结
- 交叉联结
- 自然联结
- USING子句联结
- ON子句联结
- OUTER JOIN联结
- 第5章:使用分组函数聚集数据
- AVG 和 SUM 函数
- MIN 和 MAX 函数
- COUNT函数
- STDDEV 和 VARIANCE 函数
- 分组函数和空值
- 创建数据组
- GROUP BY 子句语法
- 使用 HAVING 子句来限制组
- 嵌套分组函数
- 第6章 子查询
- 单行子查询
- 多行子查询
- IN 运算符
- ANY 运算符
- ALL 运算符
- 子查询中的空值
- 第7章 使用iSQL*Plus产生可读的输出
- 替代变亮
- & 替代变量
- 指定 字符 和 日期值
- 指定列名、表达式和文本
- 定义替代变量
- DEFINE 和 UNDEFINE 命令
- 使用 DEFINE 命令 处理 & 替代变量
- 使用 && 替代变量
- 使用 VERIFY 命令
- 自定义 iSQL*Plus 环境
- SET 命令变量
- COLUMN 命令
- BREAK 命令
- TTITLE 和 BTITLE 命令
- 创建脚本文件以便运行报表
- 第8章 处理数据
- 向表中添加新行:INSERT 语句
- 插入新行
- 插入带有空值的行
- 插入特殊值
- 插入特定日期
- 创建脚本
- 从其它表中复制行
- 更改表中的数据:UPDATE 语句
- 更新表中的行
- 用子查询更新两个列
- 根据另一个表更新行
- 从表中删除行:DELETE 语句
- 从表中删除行
- 根据另一个表删除行
- 在 INSERT 语句中使用子查询
- 在 DML 语句中使用 WITH CHECK OPTION 关键字
- 显式默认功能:DEFAULT 语句
- DEFAULT 用于 INSERT 语句
- DEFAULT 用于 UPDATE 语句
- 合并行:MERGE 语句
- 数据库事务处理
- 显式事务处理
- COMMIT 和 ROLLBACK 语句
- 隐式事务处理
- COMMIT 或 ROLLBAC 操作之前数据的状态
- COMMIT操作之后数据的状态
- 提交数据
- ROLLBACK 操作之后数据的状态
- 语句级别回退
- 读一致性
- 锁定
- 隐式锁定
本教程使用 Oracle 示例 数据库
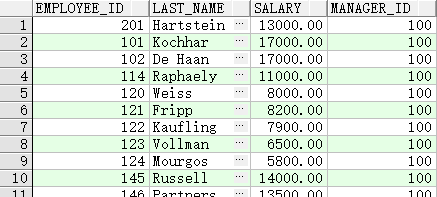
第1章:编写基本的SQL SELECT语句
基本SELECT语句
- SELCECT确定处理哪个列
- FROM确定处理哪个表
选择 departments 表中所有列
select * from departments;
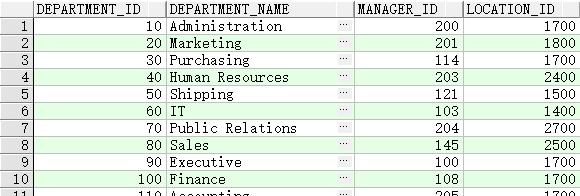
选择特定列
选择 departments 表中 department_id,location_id 两列
SELECT department_id, location_id
FROM departments;
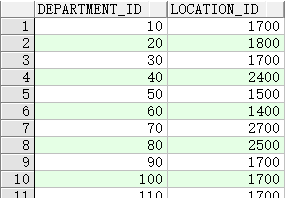
SQL语句不区分大小写
可以为一行也可为多行
算术运算符
- 算术运算符有 +加 -减 *乘 /除
所有员工薪水加 300
SELECT last_name, salary, salary + 300
FROM employees;
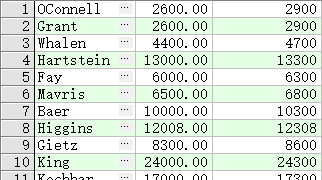
- 优先排序 * / + -
-
- 运算符优先顺序
SELECT last_name, salary, 12*salary+100
FROM employees;
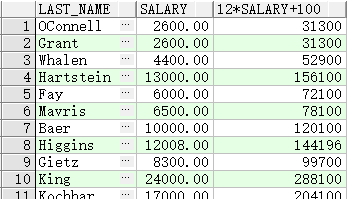
-
- 使用括号
SELECT last_name, salary, 12*(salary+100)
FROM employees;
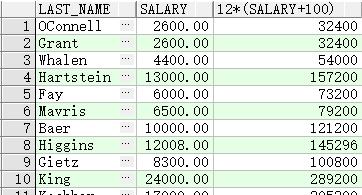
- 如果算术表达式中的任一列值为空,则结果为空
列名别名
- AS 可写可不写
-
- 不区分大小写
SELECT last_name AS name, commission_pct comm
FROM employees;
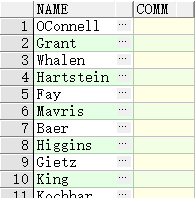
-
- 区分大小写,需加上双引号
SELECT last_name "Name", salary*12 "Annual Salary"
FROM employees;
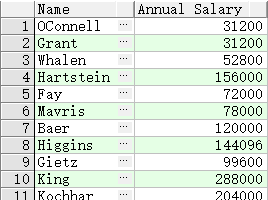
SQL语句中只有这里用双引号,其余都用单引号
连接运算符
- 将列或字符串连接到其他列,用
||表示
SELECT last_name||job_id AS "Employees"
FROM employees;
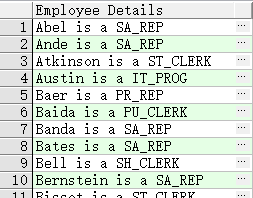
文字字符串
- 字符,数字,日期
- 日期,字符文字值 必须包含在单引号中
SELECT last_name ||' is a '||job_id
AS "Employee Details"
FROM employees;
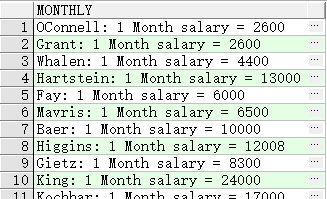
SELECT last_name ||': 1 Month salary = '||salary Monthly
FROM employees;
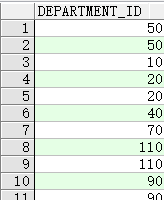
重复行
- 查询默认显示所有行,包括重复行
SELECT department_id
FROM employees;
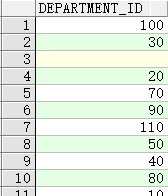
DISTINCT即distinct关键字可消除重复行
SELECT distinct department_id
FROM employees;
第2章:限制和排序数据
限制选定的行
- WHERE 子句可以比较列,文字值,算术表达式或函数的值。
查询 department_id = 90 的员工
SELECT employee_id, last_name, job_id, department_id
FROM employees
WHERE department_id = 90 ;

字符串和日期
- 字符串和日起值包含在单引号中
- 字符值区分大小写,日起值区分格式,默认格式为 DD-MON-RR
查询 last_name 为 Whalen 的员工
SELECT last_name, job_id, department_id
FROM employees
WHERE last_name = 'Whalen';
![]()
名字大写后,不返回结果
SELECT last_name, job_id, department_id
FROM employees
WHERE last_name = 'WHALEN';
比较条件
运算符比较
- = 等于 >大于 >=大于等于 <小于 <=小于等于 <>或!=或^=不等于
在 WHERE 子句中 不 能使用别名
查询薪水小于等于 3000 的员工的 last_name 和 salary
SELECT last_name, salary
FROM employees
WHERE salary <= 3000;
其他比较
-
- between…and… –>介于俩值之间(包括俩值)
-
- in(set)–> 与列表的任一值匹配
-
- like –>与某个字符模式匹配
-
- is null–>为空值
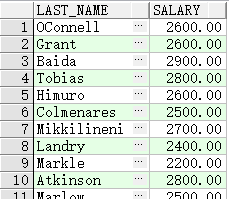
between…and…
查询薪水位于 2500 和 3500 的员工
SELECT last_name, salary
FROM employees
WHERE salary between 2500 and 3500;
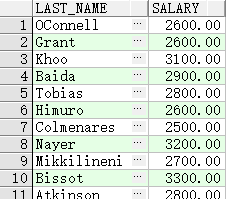
in(set)
查询 manager_id 为 100,101,201 的员工
SELECT employee_id, last_name, salary, manager_id
FROM employees
WHERE manager_id IN (100, 101, 201);
查询 last_name 为 Hartstein 和 Vargas 的员工
SELECT employee_id, manager_id, department_id
FROM employees
WHERE last_name IN ('Hartstein', 'Vargas');

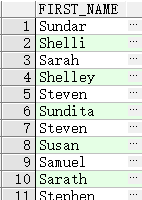
like
- % 代表 0 或 许多字符
- _ 代表 一个字符
查询 first_name 首字母为 S 的员工
SELECT first_name
FROM employees
WHERE first_name LIKE 'S%';
查询 2005 年进入公司的员工
SELECT last_name, hire_date
FROM employees
WHERE hire_date LIKE '%05';
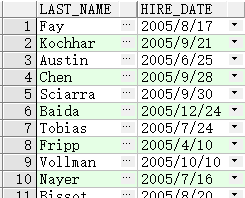
查询 last_name 第二个字母为 o 的员工
SELECT last_name
FROM employees
WHERE last_name LIKE '_o%';
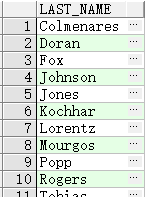
- 查询 % 和 _ 本身需要
ESCAPE即escape条件来转码
查询 job_id 包含 SA_ 的员工
SELECT employee_id, last_name, job_id
FROM employees
WHERE job_id LIKE '%SA\_%' escape '\';
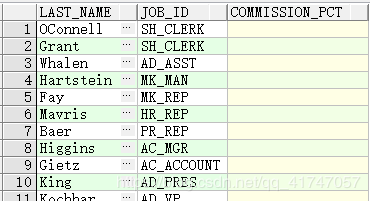
is null
查询空值
SELECT last_name, manager_id
FROM employees
WHERE manager_id IS NULL;
![]()
SELECT last_name, job_id, commission_pct
FROM employees
WHERE commission_pct IS NULL;
逻辑条件
- AND 与
- OR 或
- NOT 非
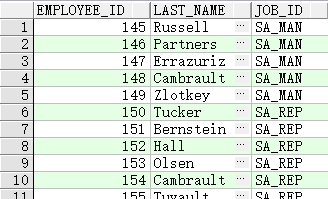
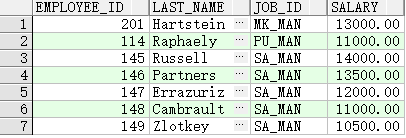
查询薪水大于等于 10000 并且 job_id 中包含 MAN 的员工
SELECT employee_id, last_name, job_id, salary
FROM employees
WHERE salary >=10000
AND job_id LIKE '%MAN%';
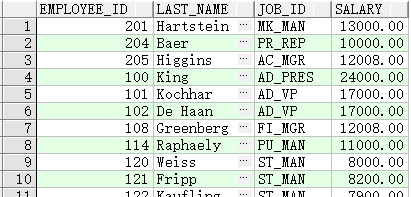
查询薪水大于等于 10000 或者 job_id 中包含 MAN 的员工
SELECT employee_id, last_name, job_id, salary
FROM employees
WHERE salary >= 10000
OR job_id LIKE '%MAN%';
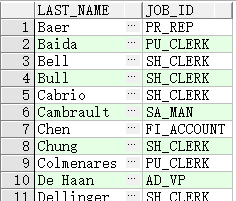
查询 job_id 不为 IT_PROG,ST_CLERK,SA_REP 的员工
SELECT last_name, job_id
FROM employees
WHERE job_id
NOT IN ('IT_PROG', 'ST_CLERK', 'SA_REP');
可以混合使用
... WHERE job_id NOT IN ('AC_ACCOUNT', 'AD_VP')
... WHERE salary NOT BETWEEN 10000 AND 15000
... WHERE last_name NOT LIKE '%A%'
... WHERE commission_pct IS NOT NULL
- 优先顺序
1.算术运算符
2.连接运算符
3.比较运算符
4.is [not] null,like,[not] in
5.[not] between
6.NOT逻辑条件
7.AND逻辑条件
8.OR逻辑条件
括号可改变优先级
先 AND 后 OR
SELECT last_name, job_id, salary
FROM employees
WHERE job_id = 'SA_REP'
OR job_id = 'AD_PRES'
AND salary > 15000;
- 使用括号后,强制改变优先级
先 OR 后 AND
SELECT last_name, job_id, salary
FROM employees
WHERE (job_id = 'SA_REP'
OR job_id = 'AD_PRES')
AND salary > 15000;
ORDER BY子句
- 使用
ORDER BY子句可对行进行排序- ASC 升序,默认
- DESC降序
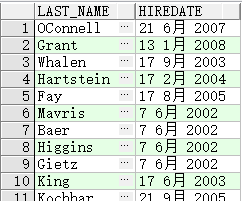
按 hire_date 升序排列
SELECT last_name, job_id, department_id, hire_date
FROM employees
ORDER BY hire_date ;
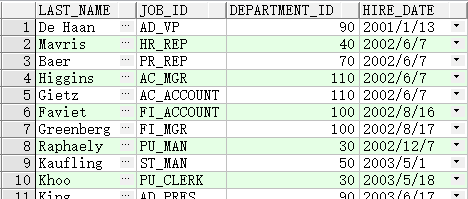
按 hire_date 降序排列
SELECT last_name, job_id, department_id, hire_date
FROM employees
ORDER BY hire_date DESC ;
空值 在 升序 中 最后 显示,在 降序 中 最先 显示
- 按别名排序
SELECT employee_id, last_name, salary*12 annsal
FROM employees
ORDER BY annsal;
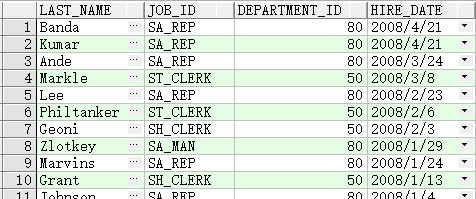
- 按多个列排序
先按部门排序,再按每个部门薪水降序排序
SELECT last_name, department_id, salary
FROM employees
ORDER BY department_id, salary DESC;
即使该列 不 在SELECT列表中,仍可按该列排序
第3章:单行函数
大小写处理函数
- 三种大小写处理函数用法
LOWER(‘SQL Course’)–>sql course
UPPER(‘SQL Course’)–>SQL COURSE
INITCAP(‘SQL Course’)–>Sql Course
- LOWER:
lower将所有字母转换为小写 - UPPER:
upper将所有字母转换为小写 - INICAP:
inicap将所有字母转换为首字母大写,其余小写
查询员工的 小写 last_name
SELECT employee_id, last_name, department_id
FROM employees
WHERE lower(last_name) = 'higgins';
![]()
查询员工的 首字母大写,其余小写 last_name
SELECT employee_id, upper(last_name), department_id
FROM employees
WHERE inicap(last_name) = 'Higgins';
字符处理函数
CONCAT(‘Hello’, ‘World’)–>HelloWorld
SUBSTR(‘HelloWorld’,1,5)–>Hello
LENGTH(‘HelloWorld’)–>10
INSTR(‘HelloWorld’, ‘W’)–>6
LPAD(salary,10,’#’)–>#####24000
RPAD(salary, 10, ‘#’)–>24000#####
TRIM(‘H’ FROM ‘HelloWorld’)–>elloWorld
- CONCAT:
concat将俩字符串连一起 - SUBSTR:
substr将指定起点终点之间字符串截出 - LENGTH:
length以数字显示字符串长度 - INSTR:
instr以数字显示指定字符位于字符串中的位置 - LPAD:
lpad按右对齐,在原字符串左边填充字符,并指定填充字符串加原字符串总长度 - RPAD:
rpad按左对齐,在原字符串右边填充字符,并指定填充字符串加原字符串总长度 - TRIM:
trim借去字符串中的头或尾的字符,或都截去
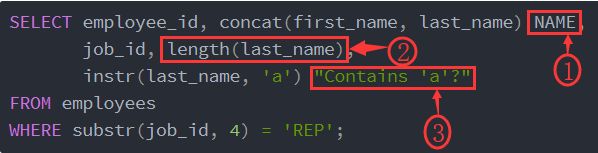
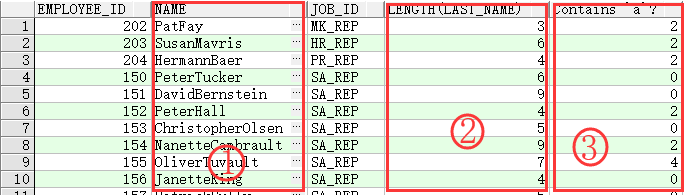
SELECT employee_id, concat(first_name, last_name) NAME,
job_id, length(last_name),
instr(last_name, 'a') "Contains 'a'?"
FROM employees
WHERE substr(job_id, 4) = 'REP';
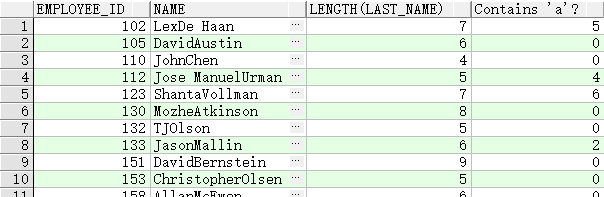
SELECT employee_id, concat(first_name, last_name) NAME,
LENGTH (last_name), instr(last_name, 'a') "Contains 'a'?"
FROM employees
WHERE substr(last_name, -1, 1) = 'n';
数字函数
ROUND(45.926, 2)–>45.93
TRUNC(45.926, 2)–>45.92
MOD(1600, 300)–>100
- ROUND:
round将值四舍五入到指定小数位 - TRUNC:
trunc将值阶断到指定小数位(不舍入) - MOD:
mod返回除法运算余数
处理日期
- 日期默认格式为 DD-MON-RR(如07-JUN-94)
- SYSDATE 函数,返回数据库服务器当前日期和时间
SELECT sysdate
FROM DUAL;
日期+数字结果为日期相当于向日期中添加天数
日期-数字结果为日期相当于向日期中减去天数
日期-日期结果为天数相当于从一个日期减另一个日期
日期+数字/24结果为日期相当于向日期中添加小时数
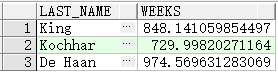
查询员工已雇佣周数
SELECT last_name, (SYSDATE-hire_date)/7 AS WEEKS
FROM employees
WHERE department_id = 90;
日期函数
MONTHS_BETWEEN (‘01-SEP-95’,‘11-JAN-94’)–>19.6774194
ADD_MONTHS (‘11-JAN-94’,6)–>‘11-JUL-94’
NEXT_DAY (‘01-SEP-95’,‘FRIDAY’)–>‘08-SEP-95’
LAST_DAY(‘01-FEB-95’)–>‘28-FEB-95’
假设SYSDATE为 25-JULY-95
ROUND(SYSDATE,‘MONTH’)–>01-AUG-95
ROUND(SYSDATE ,‘YEAR’)–>01-JAN-96
TRUNC(SYSDATE ,‘MONTH’)–>01-JUL-95
TRUNC(SYSDATE ,‘YEAR’)–>01-JAN-95
- MONTHS_BETWEEN:
months_between两个日期之间的月数 - ADD_MONTHS:
add_months将月份添加到日期当中 - NEXT_DAY:
next_day指定日期的下一天 - LAST_DAY:
last_day月份的最后一天 - ROUND:
round舍入日期 - TRUNC:
trunc截断日期
显示聘用日期不足36个月的所有员工的员工编号、聘用日期、聘用的月数、六个月的复查日期、聘用日期之后的第一个星期五和聘用当月的最后一天。
SELECT employee_id, hire_date,
months_between(SYSDATE, hire_date) TENURE,
add_months(hire_date, 6) REVIEW,
next_day(hire_date, 'FRIDAY'), last_day(hire_date)
FROM employees
WHERE months_between(sysdate, hire_date) < 36;
函数转换
-
隐式转换 = 自动转换
VARCHAR2或CHAR<自动互相转换>NUMBER
VARCHAR2或CHAR<自动互相转换>DATE -
显式转换 = 手动转换
TO_CHAR处理日期
to_char(date,'format_model')日期转指定样式
SELECT employee_id, to_char(hire_date, 'MM/YY') Month_Hired
FROM employees
WHERE last_name = 'Higgins';
![]()
-
日期格式样式:
YYYY用数字表示的完整年份
YEAR用字母拼写的年份
MM代表月份的两位数值
MONTH月份的全名
MON代表月份的三个字母缩写
DY代表星期几的三个字母缩写
DAY星期几的全名
DD用数字表示的月份中的某日 -
时间格式转换
HH24:MI:SS AM–> 15:45:32 PM -
添加字符串
DD “of” MONTH–> 12 of OCTOBER -
时间格式样式:
AM或PM正午指示符
A.M.或P.M带有句点的正午指示符
HH或HH12或HH24天中的小时,或小时(1-12),或小时(0-23),SS秒(0-59)
SSSSS午夜之后的秒数(0-86399)
查询所有员工的姓氏和聘用日期,聘用日期的显示样式为 “17June1987”
SELECT last_name,
to_char(hire_date, 'fmDD Month YYYY') AS HIREDATE
FROM employees;
此为中文版显示方法,在英文版中月份显示为 June 这样的月份
按 “Seventh of June 1994 12:00:00AM” 格式来显示日期
SELECT last_name,
to_char(hire_date,'fmDdspth "of" Month YYYY fmHH:MI:SS AM') HIREDATE
FROM employees;

TO_CHAR 处理数字
SELECT to_char(salary, '$99,999.00') SALARY
FROM employees
WHERE last_name = 'Ernst';
![]()
常规函数
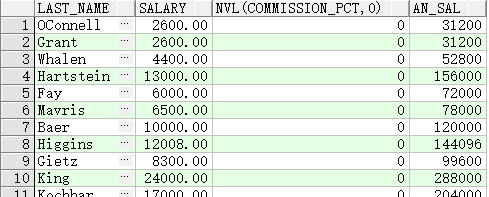
NVL 函数
NVL (expr1, expr2)- expr1是可能包含空值的源值或表达式
- expr2是转换空值的目标值
- 将空值转换为实际值
- 可以使用的数据类型为日期、字符和数字
- 数据类型必须匹配
SELECT last_name, salary, NVL(commission_pct, 0),
(salary*12) + (salary*12*NVL(commission_pct, 0)) AN_SAL
FROM employees;
NVL2 函数
NVL2(expr1, expr2, expr3)- expr1是可能包含空值的源值或表达式
- expr2expr1 不为空时返回的值
- expr3expr1 为空时返回的值
- NVL2函数会检查第一个表达式:
- 如果第一个表达式不为空,则NVL2函数会返回第二个表达式
- 如果第一个表达式为空,则返回第三个表达式
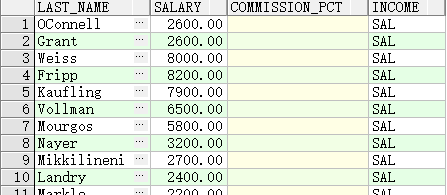
SELECT last_name, salary, commission_pct,
NVL2(commission_pct,
'SAL+COMM', 'SAL') income
FROM employees WHERE department_id IN (50, 80);
NULLIF 函数
NULLIF (expr1, expr2)- expr1是要与 expr2 比较的源值
- expr2是用来与 expr1 比较的源值(如果它不等于 expr1,则返回 expr1 )
- NULLIF 函数用于比较两个表达式:
- 如果它们相等,则函数返回空值
- 如果它们不相等,函数就会返回第一个表达式不能为第一个表达式指定 NULL
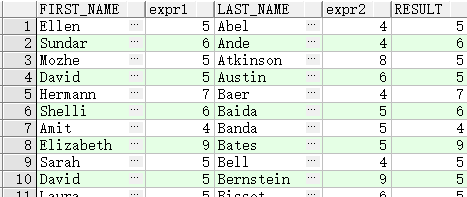
SELECT first_name, LENGTH(first_name) "expr1",
last_name, LENGTH(last_name) "expr2",
NULLIF(LENGTH(first_name), LENGTH(last_name)) result
FROM employees;
COALESCE函数
COALESCE (expr1, expr2, ... exprn)- expr1如果此表达式不为空,则返回它
- expr2如果第一个表达式为空,并且此表达式不为空,则返回它
- exprn如果前面的表达式都为空,则返回此表达式
- COALESCE 函数优于NVL函数之处在于:
COALESCE 函数可以使用多个备选值 - 如果第一个表达式不为空,则它返回该表达式;否则,将对余下的表达式执行 COALESCE 运算
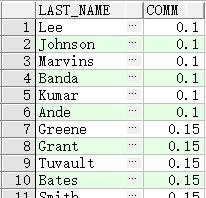
SELECT last_name,
COALESCE(commission_pct, salary, 10) comm
FROM employees
ORDER BY commission_pct;
条件表达式
CASE 表达式
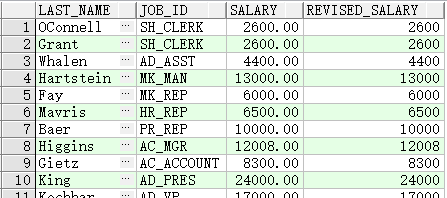
如果JOBID为ITPROG,则薪金增加10%;如果JOBID为STCLERK,薪金增加15%;如果JOBID为SAREP,薪金就增加20%。如果是其它职务角色,就不增加薪金
SELECT last_name, job_id, salary,
CASE job_id WHEN 'IT_PROG' THEN 1.10*salary
WHEN 'ST_CLERK' THEN 1.15*salary
WHEN 'SA_REP' THEN 1.20*salary
ELSE salary END "REVISED_SALARY"
FROM employees;
DECODE 表达式
上述语句等效于下述语句
SELECT last_name, job_id, salary,
DECODE(job_id, 'IT_PROG', 1.10*salary,
'ST_CLERK', 1.15*salary,
'SA_REP', 1.20*salary,
salary)
REVISED_SALARY
FROM employees;
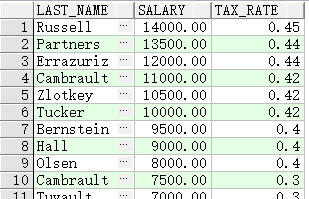
月薪范围(Monthly Salary Range)
$0.00-1999.99
$2,000.00-3,999.99
$4,000.00-5,999.99
$6,000.00-7,999.99
$8,000.00-9,999.99
$10,000.00-11,999.99
$12,200.00-13,999.99
$14,000.00或更高税率(Rate)
00%
09%
20%
30%
40%
42%
44%
45%
查询部门80中每位员工的适用税率
SELECT last_name, salary,
DECODE (TRUNC(salary/2000, 0),
0, 0.00,
1, 0.09,
2, 0.20,
3, 0.30,
4, 0.40,
5, 0.42,
6, 0.44,
0.45) TAX_RATE
FROM employees
WHERE department_id = 80;
第4章:显示多个表中的数据
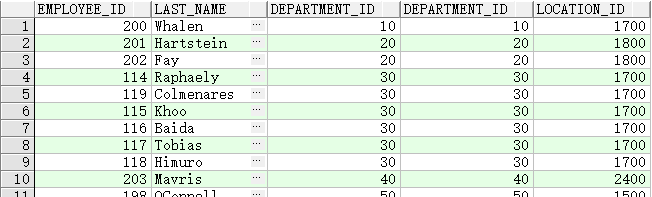
等值联结
SELECT employees.employee_id, employees.last_name, employees.department_id,
departments.department_id, departments.location_id
FROM employees, departments
WHERE employees.department_id = departments.department_id;
- 使用 AND 运算符
SELECT last_name, employees.department_id, department_name
FROM employees, departments
WHERE employees.department_id = departments.department_id
AND last_name = 'Matos';
![]()
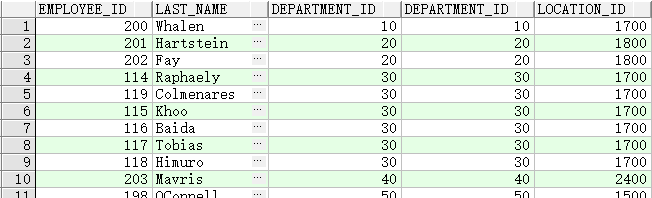
- 使用表别名
- 使用表别名可以简化查询
- 使用表前缀可以提高性能
SELECT e.employee_id, e.last_name, e.department_id,
d.department_id, d.location_id
FROM employees e , departments d
WHERE e.department_id = d.department_id;
非等值联结
SELECT e.last_name, e.salary, j.grade_level
FROM employees e, job_grades j
WHERE e.salary
BETWEEN j.lowest_sal AND j.highest_sal;
外联结
- 使用外联结还可以查看不满足联结条件的行
- 外联结运算符是加号 (+)
(+) 可位于 = 任意一侧,但不能两侧都有
SELECT table1.column, table2.column
FROM table1, table2
WHERE table1.column(+) = table2.column;
SELECT table1.column, table2.column
FROM table1, table2
WHERE table1.column = table2.column(+);
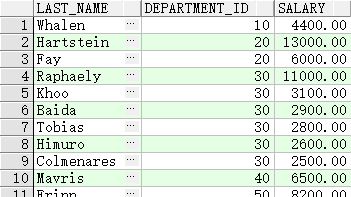
查询员工姓氏、部门标识以及部门名称
SELECT e.last_name, e.department_id, d.department_name
FROM employees e, departments d
WHERE e.department_id(+) = d.department_id ;
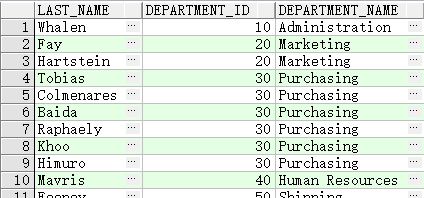
外联结运算符只能出现在表达式的一侧,即缺少信息的那一侧。它将从一个表中返回在另一个表中没有直接匹配的行。
包含外联结的条件不能使用 IN 运算符,也不能通过 OR 运算符链接到另一个条件。
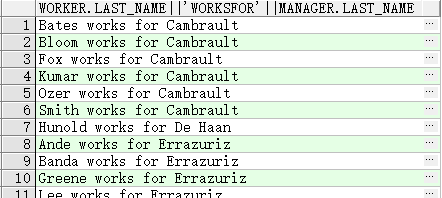
自联结
SELECT worker.last_name || ' works for '
|| manager.last_name
FROM employees worker, employees manager
WHERE worker.manager_id = manager.employee_id ;
交叉联结
- CROSS JOIN 子句可以生成两个表的交叉乘积
- 这与两个表之间的笛卡尔乘积是相同的
SELECT last_name, department_name
FROM employees
CROSS JOIN departments ;
等效于:
SELECT last_name, department_name
FROM employees, departments;
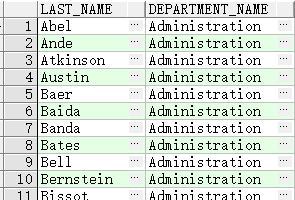
自然联结
- NATURAL JOIN 子句是以两个表中具有相同名称的所有列为基础的
- 它将选择两个表中那些在所有匹配的列中值相等的行
- 如果列具有相同的名称,但是数据类型不同,就会返回一个错误
两表的 location_id 相同,查询出 location_id 相同的行
SELECT department_id, department_name,
location_id, city
FROM departments
NATURAL JOIN locations ;
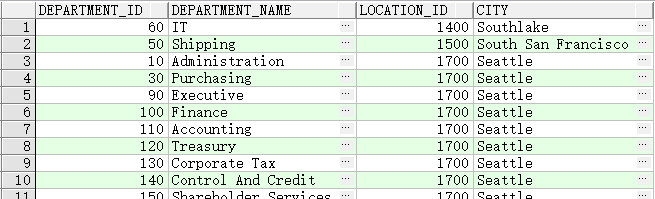
等效于:
SELECT department_id, department_name,
departments.location_id, city
FROM departments, locations
WHERE departments.location_id = locations.location_id;
查询限制 department_id 为 20 或 50 的行
SELECT department_id, department_name,
location_id, city
FROM departments
NATURAL JOIN locations
WHERE department_id IN (20, 50);

USING子句联结
SELECT l.city, d.department_name
FROM locations l JOIN departments d USING (location_id)
WHERE location_id = 1400;
![]()
SELECT e.employee_id, e.last_name, d.location_id
FROM employees e JOIN departments d
USING (department_id) ;
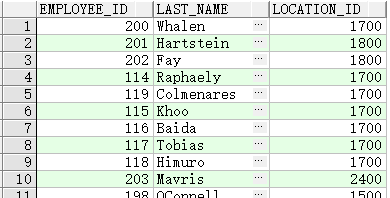
等效于:
SELECT employee_id, last_name,
employees.department_id, location_id
FROM employees, departments
WHERE employees.department_id = departments.department_id;
ON子句联结
SELECT e.employee_id, e.last_name, e.department_id,
d.department_id, d.location_id
FROM employees e JOIN departments d
ON (e.department_id = d.department_id);
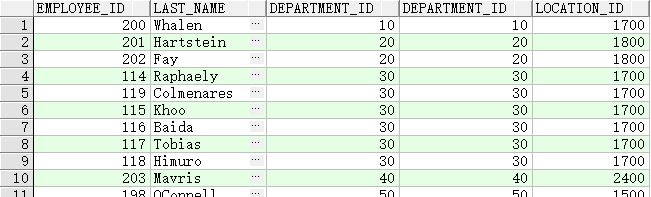
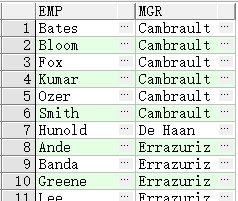
联结不同的列
SELECT e.last_name emp, m.last_name mgr
FROM employees e JOIN employees m
ON (e.manager_id = m.employee_id);
三向联结
SELECT employee_id, city, department_name
FROM employees e
JOIN departments d
ON d.department_id = e.department_id
JOIN locations l
ON d.location_id = l.location_id;
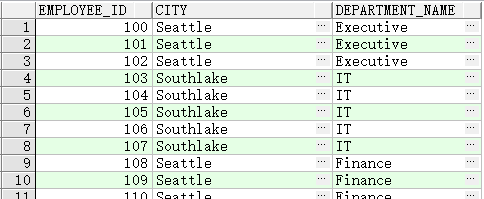
等效于:
SELECT employee_id, city, department_name
FROM employees, departments, locations
WHERE employees.department_id = departments.department_id
AND departments.location_id = locations.location_id;
OUTER JOIN联结
- LEFT OUTER JOIN 联结
SELECT e.last_name, e.department_id, d.department_name
FROM employees e
LEFT OUTER JOIN departments d
ON (e.department_id = d.department_id) ;
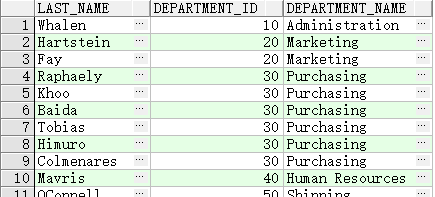
等效于:
SELECT e.last_name, e.department_id, d.department_name
FROM employees e, departments d
WHERE d.department_id (+) = e.department_id;
- RIGHT OUTER JOIN 联结
SELECT e.last_name, e.department_id, d.department_name
FROM employees e
RIGHT OUTER JOIN departments d
ON (e.department_id = d.department_id) ;
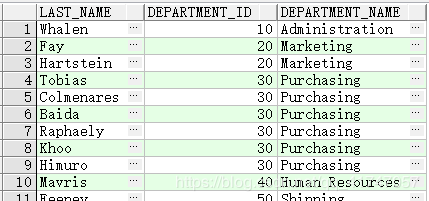
等效于:
SELECT e.last_name, e.department_id, d.department_name
FROM employees e, departments d
WHERE d.department_id = e.department_id (+);
- FULL OUTER JOIN 联结
SELECT e.last_name, e.department_id, d.department_name
FROM employees e
FULL OUTER JOIN departments d
ON (e.department_id = d.department_id) ;
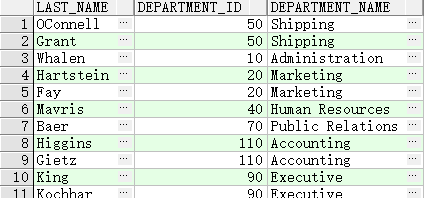
- 附加条件
SELECT e.employee_id, e.last_name, e.department_id,
d.department_id, d.location_id
FROM employees e JOIN departments d
ON (e.department_id = d.department_id)
AND e.manager_id = 149 ;
第5章:使用分组函数聚集数据
AVG 和 SUM 函数
- AVG 平均值,忽略空值
- SUM 总计值,忽略空值
SELECT AVG(salary), MAX(salary),
MIN(salary), SUM(salary)
FROM employees
WHERE job_id LIKE '%REP%';
![]()
MIN 和 MAX 函数
- MIN 最小值,忽略空值
- MAX 最大值,忽略空值
SELECT MIN(hire_date), MAX(hire_date)
FROM employees;
![]()
COUNT函数
- COUNT 函数有三种格式:
- COUNT( * ) 可以返回表中满足 SELECT 语句条件的行的数量,包括重复的行和任意列中含有空值的行;如果 SELECT 语句中包含 WHERE 子句,COUNT(*) 会返回满足 WHERE 子句中条件的行的数量
- COUNT(expr) 返回由 expr 标识的列中非空值的数量
- COUNT(DISTINCT expr) 返回由 expr 标识的列中不重复的、非空值的数量
返回表中行的数量
SELECT COUNT(*)
FROM employees
WHERE department_id = 50;
![]()
- COUNT(expr) 返回 expr 为非空值的行的数量
显示 EMPLOYEES 表中部门值的数量,不包括空值
SELECT COUNT(commission_pct)
FROM employees
WHERE department_id = 80;
![]()
- 使用 DISTINCT 关键字
- COUNT(DISTINCT expr) 返回 expr 的不重复的非空值的数量
显示 EMPLOYEES 表中不重复的部门值的数量
SELECT COUNT(DISTINCT department_id)
FROM employees;
![]()
STDDEV 和 VARIANCE 函数
- STDDEV 标准差,忽略空值
- VARIANCE 方差,忽略空值
分组函数和空值
- 分组函数会忽略列中的空值
SELECT AVG(commission_pct)
FROM employees;
![]()
- NVL 函数可以强制分组函数包含空值
SELECT AVG(NVL(commission_pct, 0))
FROM employees;
![]()
创建数据组
GROUP BY 子句语法
- 不能在 GROUP BY 子句中使用列别名
- 在默认情况下,行按照包含在 GROUP BY 列表中的列的升序来排列。可以通过 ORDER BY 子句来改变这种排序方式
查询不同部门的员工的平均薪水
SELECT department_id, AVG(salary)
FROM employees
GROUP BY department_id ;
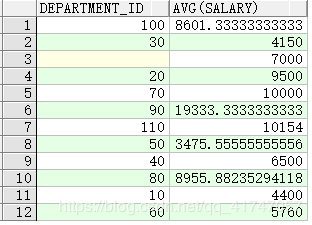
- GROUP BY 列不一定要出现在 SELECT 列表中
SELECT AVG(salary)
FROM employees
GROUP BY department_id ;
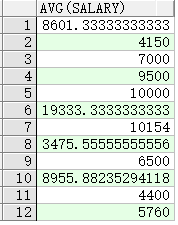
按平均薪水排序
SELECT department_id, AVG(salary)
FROM employees
GROUP BY department_id
ORDER BY AVG(salary);
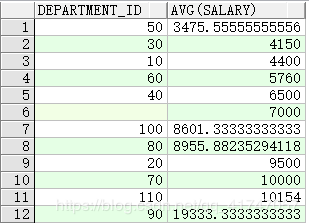
- SELECT 列表中 不是聚合函数 的任何列或表达式都 必须 在 GROUP BY 子句中
错误示例:
SELECT department_id, COUNT(last_name)
FROM employees;
纠正后:
SELECT department_id, count(last_name)
FROM employees
GROUP BY department_id;
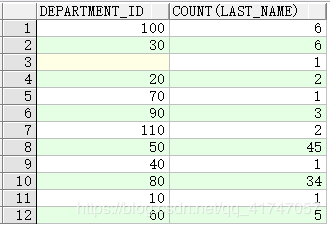
- 不能使用 WHERE 子句来限制组
- 可以使用 HAVING 子句来限制组
- 不能在 WHERE 子句中使用分组函数
错误示例:
SELECT department_id, AVG(salary)
FROM employees
WHERE AVG(salary) > 8000
GROUP BY department_id;
纠正后:
SELECT department_id, AVG(salary)
FROM employees
HAVING AVG(salary) > 8000
GROUP BY department_id;
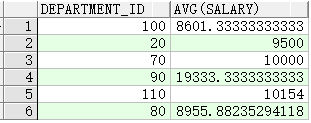
使用 HAVING 子句来限制组
查询最高薪金高于$10,000的部门的部门编号和最高薪金
SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary)>10000 ;
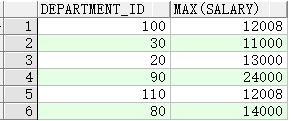
查询工资总额超过$13,000的每个职务的职务标识和月薪总额。该示例排除了销售代表,并按照月薪总额对列表进行排序
SELECT job_id, SUM(salary) PAYROLL
FROM employees
WHERE job_id NOT LIKE '%REP%'
GROUP BY job_id
HAVING SUM(salary) > 13000
ORDER BY SUM(salary);
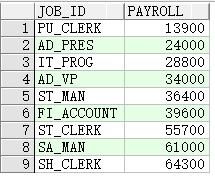
嵌套分组函数
查询最高平均薪水
SELECT MAX(AVG(salary))
FROM employees
GROUP BY department_id;
第6章 子查询
- 子查询(内部查询)在执行主查询之前执行一次
- 然后主查询(外部查询)会使用该子查询的结果
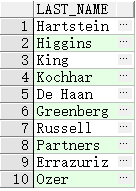
内部查询用于确定员工Abel的薪金。外部查询采用内部查询的结果,并使用此结果来显示薪金超过此数额的所有员工。
SELECT last_name
FROM employees
WHERE salary >
(SELECT salary
FROM employees
WHERE last_name = 'Abel');
单行子查询
- 仅返回一行
- 使用单行比较运算符
- 单行运算符有:
= 等于
> 大于
>= 大于等于
< 小于
< 小于等于
<> 不等于
- 单行运算符有:
显示职务标识和员工141相同的员工
SELECT last_name, job_id
FROM employees
WHERE job_id =
(SELECT job_id
FROM employees
WHERE employee_id = 141);
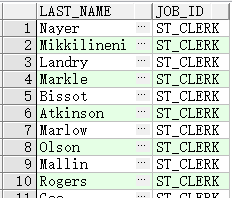
查询职务标识和员工141相同,并且薪金高于员工143的员工
SELECT last_name, job_id, salary
FROM employees
WHERE job_id =
(SELECT job_id
FROM employees
WHERE employee_id = 141)
AND salary >
(SELECT salary
FROM employees
WHERE employee_id = 143);
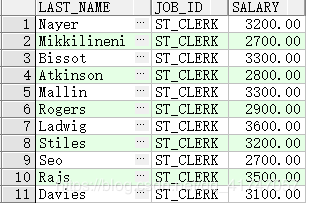
- 在子查询中使用分组查询
查询薪金等于最低薪金的所有员工的姓氏、职务标识和薪金
SELECT last_name, job_id, salary
FROM employees
WHERE salary =
(SELECT MIN(salary)
FROM employees);
![]()
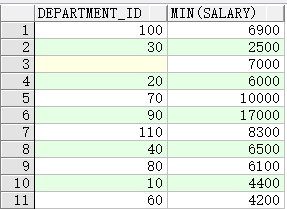
- 具有子查询的 HAVING 语句
SELECT department_id, MIN(salary)
FROM employees
GROUP BY department_id
HAVING MIN(salary) >
(SELECT MIN(salary)
FROM employees
WHERE department_id = 50);
查找平均薪资最低的工作
SELECT job_id, AVG(salary)
FROM employees
GROUP BY job_id
HAVING AVG(salary) = (SELECT MIN(AVG(salary))
FROM employees
GROUP BY job_id);
- 单行运算符 不能 用于多行子查询
错误示例:
SELECT employee_id, last_name
FROM employees
WHERE salary =
(SELECT MIN(salary)
FROM employees
GROUP BY department_id);
多行子查询
- 返回多个行
- 使用多行比较运算符
- 多行运算符有:
IN 等于列表中的任意一个
ANY 将值与子查询返回的任意一个值进行比较
ALL 将值与子查询返回的每个值进行比较
- 多行运算符有:
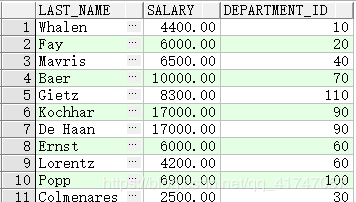
IN 运算符
查薪金等于各个部门最低薪金的所有员工
SELECT last_name, salary, department_id
FROM employees
WHERE salary IN (SELECT MIN(salary)
FROM employees
GROUP BY department_id);
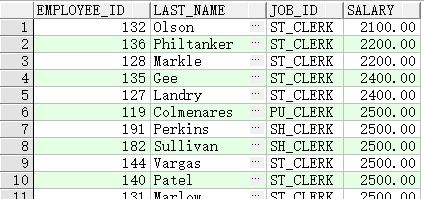
ANY 运算符
- ANY 运算符(和其同义词SOME运算符)将值与子查询返回的在意一个值进行比较
- < ANY意味着低于最高值
> ANY意味着高于最低值
= ANY等同于IN
- < ANY意味着低于最高值
查询职务不是IT程序员并且薪金低于任何一个IT程序员的员工,程序员的最高薪金为$9,000
SELECT employee_id, last_name, job_id, salary
FROM employees
WHERE salary < ANY
(SELECT salary
FROM employees
WHERE job_id = 'IT_PROG')
AND job_id <> 'IT_PROG';
ALL 运算符
- ALL 运算符会将一个值与子查询返回的每个值进行比较
- < ALL意味着低于最低值
> ALL意味着高于最高值 - NOT运算符可以和 IN、ANY 和 ALL 运算符配合使用
- < ALL意味着低于最低值
查询薪金低于所有职务标识为 IT_PROG 的员工且职务不是 IT_PROG 的员工
SELECT employee_id, last_name, job_id, salary
FROM employees
WHERE salary < ALL
(SELECT salary
FROM employees
WHERE job_id = 'IT_PROG')
AND job_id <> 'IT_PROG';
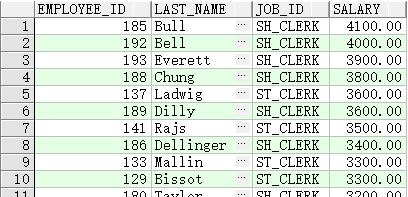
子查询中的空值
显示没有任何下属的所有员工
SELECT emp.last_name
FROM employees emp
WHERE emp.employee_id NOT IN
(SELECT mgr.manager_id
FROM employees mgr);
该SQL语句没有返回任何行,因为内部查询返回的其中一个值是空值,所以整个查询不会返回任何行
- 如果使用的是 IN 运算符,则子查询的结果集中存在空值就不会成为问题
- IN运算符等同于**= ANY**
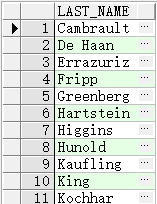
查询具有下属的员
SELECT emp.last_name
FROM employees emp
WHERE emp.employee_id IN
(SELECT mgr.manager_id
FROM employees mgr);
等效于:
SELECT last_name FROM employees
WHERE employee_id NOT IN
(SELECT manager_id
FROM employees
WHERE manager_id IS NOT NULL);
第7章 使用iSQL*Plus产生可读的输出
替代变亮
- 使用iSQL*Plus替代变量可以执行以下任务:
- 临时存储值
单和号(&)
双和号(&&)
DEFINE 命令 - 在SQL 语句之间传递变量值
- 动态更改题头和页脚
- 临时存储值
& 替代变量
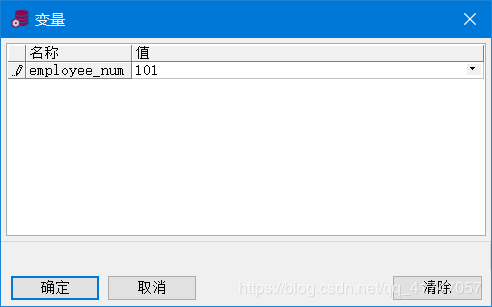
使用前缀有和号(&)的变量可以提示用户输入值
SELECT employee_id, last_name, salary, department_id
FROM employees
WHERE employee_id = &employee_num ;
![]()
指定 字符 和 日期值
- 对于日期和字符值使用单引号
- 可以将 和号 用于诸如 UPPER 和 LOWER 之类的函数
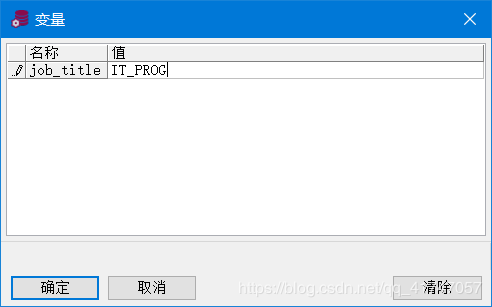
- 使用 UPPER(’&job title1) 可以使用户不必以大写输入职称
查询会根据 iSQL*Plus 替代变量的职称值检索
SELECT last_name, department_id, salary*12
FROM employees
WHERE job_id = '&job_title' ;
指定列名、表达式和文本
- 使用替代变量可以补充以下对象:
WHER 条件
ORDER BY 子句
列表达试
表名
整个 SELLECT 语句
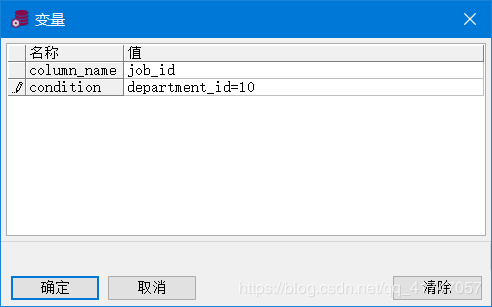
查询满足任何条件的 员工编号 和 任何其它列
SELECT employee_id, &column_name
FROM employees
WHERE &condition;
![]()
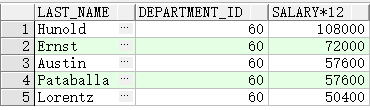
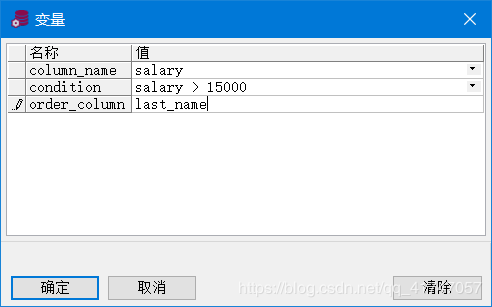
查询 EMPLOYEES 表中的员 工编号、姓名、职称 和 用户在运行时指定的任何其它列
SELECT employee_id, last_name, job_id,
&column_name
FROM employees
WHERE &condition
ORDER BY &order_column ;

定义替代变量
DEFINE 和 UNDEFINE 命令
- 变量执行以下 任一 操作 之前 一直 保持 已定义状态
- 使用 UNDEFIINE 命令清除它
- 退出 iSQL*Plus
- 可以使用 DEFINE 命令来验证更改
使用 DEFINE 命令 处理 & 替代变量
使用 DEFINE 命令创建一个员工编号的 iSQL*Plus 替代变量,并且在运行时显示该员工的员工编号、姓名、薪金和部门编号
DEFINE employee_num = 200;
SELECT employee_id, last_name, salary, department_id
FROM employees
WHERE employee_id = &employee_num ;

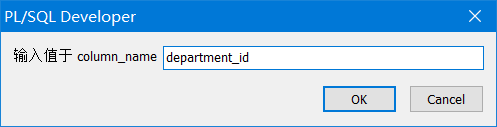
使用 && 替代变量
SELECT employee_id, last_name, job_id, &&column_name
FROM employees
ORDER BY &column_name;
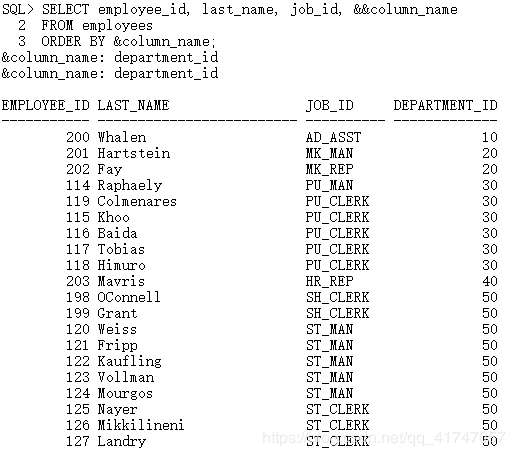
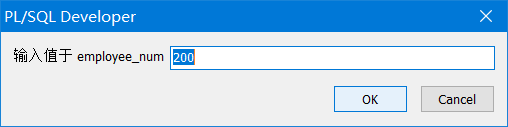
使用 VERIFY 命令
- 使用 VERIFY 命令可以切换替代变量的显示,分别显示 iSQL*Plus 用值替换替代变量前后的状况
SET VERIFY ON
SELECT employee_id, last_name, salary, department_id
FROM employees
WHERE employee_id = &employee_num;
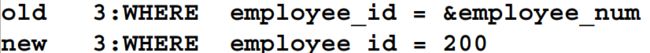
自定义 iSQL*Plus 环境
SET 命令变量
- 使用 SET 命令可以控制当前会话
SET system variable value
- 使用 SHOW 命令可以验证所设置的内容
SET ECHO ON
SHOW ECHO
echo ON
- SET 命令变量
ARRAYSIZE { 20 / n } arraysize -->设置数据库数据取数大小
FEEDBACK { 6 / n / OFF / ON } feedback -->显示当查询选择了至少n条记录时将返回的记录的数量
HEADING { OFF / ON } heading -->确定是否在报表中显示列标题
LONG { 80 / n } long -->设置显示 LONG 值的最大宽度
如:
SET HEADING OFF
SHOW HEADING
HEADING OFF
COLUMN 命令
- COLUMN 命令选项
CLEAR 清除任何列格式
HEADING text 设置列标题(如果使用竖线(|),那么除非使用调整对齐,否则将强制在标题中换行)
FORMAT format 更改列数据的显示
NOPRINT 隐藏列
NULL text 指定在值为空时显示的文本
PRINT 显示列
创建列标题
COLUMN last_name HEADING 'Employee|Name'
COLUMN salary JUSTIFY LEFT FORMAT $99,990.00
COLUMN manager FORMAT 999999999 NULL 'No manager
显示 LAST_NAME 当前设置
COLUMN last_name

清除 LAST_NAME 设置
COLUMN last_name CLEAR
- COLUMN 格式样式
9 取消前导零的数字 999999 123
0 加上前导零 099999 001234
$ 浮动的美元记号 $9999 $1234
L 当地货币 L9999 L1234
. 小数点的位置 9999.99 1234.00
, 千位分隔符 9,999 1,234
BREAK 命令
- 使用 BREAK 命令可以取消重复项
BREAK ON job_id
- 使用 CLEAR 命令可以清除所有的 BREAK 设置
CLEAR BREAK
TTITLE 和 BTITLE 命令
- 显示 题头 和 页脚
TTITLE [text|OFF|ON]
- 设置报表 题头
TTITLE 'Salary|Report'
- 设置报表页脚
BTITLE 'Confidential'
创建脚本文件以便运行报表
- 如何创建脚本文件:
- 在 SQL 提示符下创建 SQL SELECT 语句。确保报表所需的数据是准确的,然后再将语句保存到文件中,并应用格式命令。如果您要使用 BREAK 命令,请确保将相关的 ORDER BY 子句包含在内
- 将 SELECT 语句保存到脚本文件中
- 编辑该脚本文件以便输入 iSQL*Plus 命令
- 在 SELECT 语句之前添加必需的格式命令。一定不要将 iSQL*Plus 命令放置在 SELECT 语句中
- 确保 SELECT 语句后面跟着运行字符,可以是分号 ( ; ) 或斜线 ( / )
- 在运行字符之后添加清除格式的 iSQL*Plus 命令。或者,您可以将所有格式清除命令保存在一个重置文件中
- 将您的更改保存到该脚本文件中
- 将该脚本文件加载到 iSQL*Plus 文本窗口中,然后单击“执行”按钮
- 准则
- 在脚本中,iSQL*Plus 命令之间可以包含空白行
- 如果 iSQL*Plus 或 SQL*Plus 命令太长,则可以用一个连字符 ( - ) 终止当前行,然后在下一行继续该命令
- 可以缩写 iSQL*Plus 命令
- 将重置命令放置到文件的结尾处,可以还原最初的 iSQL*Plus 环境
创建一个脚本文件,用它创建一个报表,以便显示薪金低于 $15,000 的所有员工的职务标识、姓氏和薪金。添加一个居中的两行题头 “Employee Report” 和一个居中的页脚 “Confidential” 。将职称列重命名为跨两行的 “Job Category” 。将员工姓名列重命名为 “Employee” 。将薪金列重命名为 “Salary” ,并将其格式设置为 $2,500.00 的样式。
SET FEEDBACK OFF
TTITLE 'Employee|Report'
BTITLE 'Confidential'
BREAK ON job_id
COLUMN job_id HEADING 'Job|Category'
COLUMN last_name HEADING 'Employee'
COLUMN salary HEADING 'Salary' FORMAT $99,999.99
REM ** Insert SELECT statement
SELECT job_id, last_name, salary
FROM employees
WHERE salary < 15000
ORDER BY job_id, last_name
/
REM clear all formatting commands ...
SET FEEDBACK ON
COLUMN job_id CLEAR
COLUMN last_name CLEAR
COLUMN salary CLEAR
CLEAR BREAK
...
第8章 处理数据
向表中添加新行:INSERT 语句
- 使用此语法一次只能添加一行
- 为清楚起见,请在 INSERT 子句中使用列列表
- 将字符值和日期值包含在单引号中,建议不要将数字值包含在单引号中
- 因为如果使用了单引号,分配给 NUMBER 数据类型列的数字值可能会发生隐式转换
插入新行
INSERT INTO departments(department_id, department_name,
manager_id, location_id)
VALUES (70, 'Public Relations', 100, 1700);
插入带有空值的行
隐式:在列列表中省略该列
INSERT INTO departments (department_id,
department_name )
VALUES (30, 'Purchasing');
显试:在 VALUES 子句中指定 NULL 关键字
INSERT INTO departments
VALUES (100, 'Finance', NULL, NULL);
插入特殊值
- SYSDATE 函数记录 当前 日期 和 时间
INSERT INTO employees (employee_id,
first_name, last_name,
email, phone_number,
hire_date, job_id, salary,
commission_pct, manager_id,
department_id)
VALUES (113,
'Louis', 'Popp',
'LPOPP', '515.124.4567',
SYSDATE, 'AC_ACCOUNT', 6900,
NULL, 205, 100);
插入特定日期
- 通常使用 DD-MON-YY 格式插入日期值,世纪默认为当前世纪,包含时间信息,默认时间为午夜 (00:00:00)
- 如果必须以不同于默认格式的格式输入日期,例如要输入另一个世纪的日期或者特定时间,则必须使用 TO_DATE 函数
在 EMPLOYEES 表中记录了员工 Raphealy 的信息,将 HIRE_DATE 列设置为1999年2月3日
INSERT INTO employees
VALUES (114,
'Den', 'Raphealy',
'DRAPHEAL', '515.127.4561',
TO_DATE('FEB 3, 1999', 'MON DD, YYYY'),
'AC_ACCOUNT', 11000, NULL, 100, 30);
如果使用下面的语句而不是上述语句,hire_date 的年份将被解释为2099
INSERT INTO employees
VALUES (114,
'Den', 'Raphealy',
'DRAPHEAL', '515.127.4561',
'03-FEB-99',
'AC_ACCOUNT', 11000, NULL, 100, 30);
创建脚本
- 在 SQL 语句中使用 & 替代变量来提示输入值
- & 是变量值的占位符。
INSERT INTO departments
(department_id, department_name, location_id)
VALUES (&department_id, '&department_name',&location);
从其它表中复制行
- 不要使用 VALUES 子句。
- 使 INSERT 子句中的列数与子查询中的列数匹配
INSERT INTO sales_reps(id, name, salary, commission_pct)
SELECT employee_id, last_name, salary, commission_pct
FROM employees
WHERE job_id LIKE '%REP%';
创建表中行的复本,应在子查询中使用 SELECT *
INSERT INTO copy_emp
SELECT *
FROM employees;
更改表中的数据:UPDATE 语句
- 使用 UPDATE 语句修改现有的行
- 如果需要,一次可以更新多个行
更新表中的行
- 如果指定了 WHERE 子句,则可以修改特定的某一行或多个行
UPDATE employees
SET department_id = 70
WHERE employee_id = 113;
- 如果省略了 WHERE 子句,则会修改表中的所有行
UPDATE copy_emp
SET department_id = 110;
用子查询更新两个列
更新员工 114 的 职务 和 薪金,使之与员工 205 的 职务 和 薪金 相同
UPDATE employees
SET job_id = (SELECT job_id
FROM employees
WHERE employee_id = 205),
salary = (SELECT salary
FROM employees
WHERE employee_id = 205)
WHERE employee_id = 114;
根据另一个表更新行
根据另一个表中的 值,在 UPDATE 语句中使用 子查询 更新表中的 行
UPDATE copy_emp
SET department_id = (SELECT department_id
FROM employees
WHERE employee_id = 100)
WHERE job_id = (SELECT job_id
FROM employees
WHERE employee_id = 200);
从表中删除行:DELETE 语句
从表中删除行
- 如果指定了 WHERE 子句,则可以删除特定的行
DELETE FROM departments
WHERE department_name = 'Finance';
- 如果省略了 WHERE 子句,则会删除表中的所有行
DELETE FROM copy_emp;
根据另一个表删除行
在 DELETE 语句中使用子查询,以便根据另一个表中的值来删除表中的行
DELETE FROM employees
WHERE department_id =
(SELECT department_id
FROM departments
WHERE department_name LIKE '%Public%');
- 如果某行包含作为另一个表的外键的主键,则不能删除该行
错误示例:
示例尝试从 EMPLOYEES 表中删除部门编号60,但由于部门编号被用作EMPLOYEES表的外键,因而产生一个错误
DELETE FROM departments
WHERE department_id = 60;
下面的语句之所以有效是因为部门70中没有员工
DELETE FROM departments
WHERE department_id = 70;
在 INSERT 语句中使用子查询
- 可以用子查询代替 INSERT 语句的 INTO 子句中的表名
INSERT INTO
(SELECT employee_id, last_name,
email, hire_date, job_id, salary,
department_id
FROM employees
WHERE department_id = 50)
VALUES (99999, 'Taylor', 'DTAYLOR',
TO_DATE('07-JUN-99', 'DD-MON-RR'),
'ST_CLERK', 5000, 50);
在 DML 语句中使用 WITH CHECK OPTION 关键字
- 子查询用来指定 DML 语句的表和列
- WITH CHECK OPTION 关键字可以防止更改不在子查询中的行
- 指定 WITHCHECK OPTION 就指明了如下情况:
- 如果在 INSERT、UPDATE 或 DELETE 语句中使用子查询代替表,则不允许对该表进行更改以免产生子查询中不包含的行
示例中,使用了 WITH CHECKOPTION 关键字。子查询中指定了查询部门 50 中的行,但部门标识在 SELECT 中未指定,而且 VALUES 列表中也未提供部门标识的值。插入这样的行会产生为空值的部门标识,该部门标识不在子查询中
INSERT INTO (SELECT employee_id, last_name, email,
hire_date, job_id, salary
FROM employees
WHERE department_id = 50 WITH CHECK OPTION)
VALUES (99998, 'Smith', 'JSMITH',
TO_DATE('07-JUN-99', 'DD-MON-RR'),
'ST_CLERK', 5000);
显式默认功能:DEFAULT 语句
- 利用显式默认功能,您可以在希望使用列默认值的地方将 DEFAULT 关键字作为列值
- 这样用户就可以控制在何时何地将默认值应用于数据
- 显式默认值可以在 INSERT 和 UPDATE 语句中使用
DEFAULT 用于 INSERT 语句
示例中INSERT 语句使用了 MANAGER_ID 列的默认值。如果没有为该列定义默认值,则会插入一个空值
INSERT INTO departments
(department_id, department_name, manager_id)
DEFAULT 用于 UPDATE 语句
示例使用 UPDATE 语句将部门 10 的 MANAGER_ID 列设置为默认值。如果没有为该列定义默认值,则会将其更改为空值
UPDATE departments
SET manager_id = DEFAULT WHERE department_id = 10;
合并行:MERGE 语句
- 提供有条件地在数据库表中更新或插入数据的功能
- 如果该行存在就执行 UPDATE,如果是新行则执行 INSERT:
- 避免单独更新
- 增强性能和易用性
- 在数据仓库应用程序中尤为有用
在 COPY_EMP 表中插入或更新行,以便与 EMPLOYEES 表匹配
MERGE INTO copy_emp c
USING employees e
ON (c.employee_id = e.employee_id)
WHEN MATCHED THEN
UPDATE SET
c.first_name = e.first_name,
c.last_name = e.last_name,
...
c.department_id = e.department_id
WHEN NOT MATCHED THEN
INSERT VALUES (e.employee_id, e.first_name, e.last_name,
e.email, e.phone_number, e.hire_date, e.job_id,
e.salary, e.commission_pct, e.manager_id,
e.department_id);
示例将 COPYEMP 表中的 EMPLOYEE_ID与 EMPLOYEES 表中的 EMPLOYEE_ID匹配。如果发现匹配项,就更新COPY_EMP 中的行,使之与 EMPLOYEES 表中的行匹配。如果没找到该行,则将其插入到COPY_EMP表中
MERGE INTO copy_emp c
USING employees e
ON (c.employee_id = e.employee_id)
WHEN MATCHED THEN
UPDATE SET
c.first_name = e.first_name,
c.last_name = e.last_name,
c.email = e.email,
c.phone_number = e.phone_number,
c.hire_date = e.hire_date,
c.job_id = e.job_id,
c.salary = e.salary,
c.commission_pct = e.commission_pct,
c.manager_id = e.manager_id,
c.department_id = e.department_id
WHEN NOT MATCHED THEN
INSERT VALUES (e.employee_id, e.first_name, e.last_name,
e.email, e.phone_number, e.hire_date, e.job_id,
e.salary, e.commission_pct, e.manager_id,
e.department_id);
数据库事务处理
显式事务处理
COMMIT 和 ROLLBACK 语句
-
使用 COMMIT 和 ROLLBACK 语句,可以:
- 确保数据的一致性
- 在使更改永久化之前预览数据更改
- 按逻辑关系对相关操作进行分组
-
使用COMMIT、SAVEPOINT 和 ROLLBACK 语句可以控制事务处理的逻辑
- COMMIT–> 将所有待定的数据更改永久化,从而结束当前的事务处理
- SAVEPOINT name --> 在当前事务处理中标记一个保存点
- ROLLBACK --> 将放弃所有待定的数据更改,从而结束当前的事务处理
- ROLLLBACK TO SAVEPOINT name -->将当前的事务处理回退到指定的保存点,从而放弃从该保存点之后所作的所有 更改 和 创建的保存点。如果省略了 TO SAVEPOINT 子句,ROLLBACK 语句将回退整个事务处理。由于保存点是逻辑的,因此无法列出您创建的保存点
使用 SAVEPOINT 语句在当前事务处理中创建一个标记
使用 ROLLBACK TO SAVEPOINT 语句回退到该标记处
UPDATE...
SAVEPOINT update_done;
INSERT...
ROLLBACK TO update_done;
隐式事务处理
COMMIT 或 ROLLBAC 操作之前数据的状态
- 数据处理操作主要影响数据库缓冲区;因此可以将数据恢复到以前的状态
- 当前用户可以通过对表进行查询来复查数据处理操作的结果
- 其他用户无法查看当前用户进行的数据处理操作的结果
- Oracle服务器将建立读一致性,从而确保每个用户看到的数据都是上次提交时的数据
- 受影响的行将被锁定,其他用户无法修改这些行中的数据
COMMIT操作之后数据的状态
- 数据更改被写入到数据库
- 以前的数据状态永久丢失
- 所有用户都可以查看该事务处理的结果
- 受影响行的锁定被释放;其他用户可以对这些行进行新的数据更改
- 所有保存点都被清除
提交数据
进行更改
DELETE FROM employees
WHERE employee_id = 99999;
INSERT INTO departments
VALUES (290, 'Corporate Tax', NULL, 1700);
提交更改
COMMIT;
Commit complete.
ROLLBACK 操作之后数据的状态
- 数据更改被撤消
- 数据还原到以前的状态
- 受影响行的锁定被释放
语句级别回退
- 如果在执行期间单个 DML 语句失败,则只需回退该语句。
- Oracle 服务器实施隐式保存点。
- 所有其它更改将被保留。
- 用户应该通过执行 COMMIT或 ROLLLBACK 语句显式终止事务处理。
读一致性
- 保证数据库读取者和写入者看到一致的数据
- 保证读取者看不到正在被更改的数据
- 保证写入者对数据库的更改在一致的方式下完成
- 保证一个写入者进行的更改不会打断另一个写入者正在进行的更改,也不会与之冲突
锁定
- 在 Oracle 数据库中,锁具有以下特性:
- 防止并发事务处理之间的破坏性交互作用
- 不需要用户操作
- 自动使用最低级别的限制
- 在事务处理期间保持锁定
- 具有两种类型:显式锁定和隐式锁定
隐式锁定
- 两种锁定模式:
- 排它模式:不允许其他用户访问
- 共享模式:允许其他用户访问
- 高级别数据并发:
- DML:表共享,行排它
- 查询:不需要锁定
- DDL:保护对象定义
- 在提交或回退之前一直保持锁定