JAVA序列化机制的深入研究
对象序列化的最主要的用处就是在传递,和保存对象(object)的时候,保证对象的完整性和可传递性。
序列化算法一般会按步骤做如下事情:
◆ 将对象实例相关的类元数据输出。
◆ 递归地输出类的超类描述直到不再有超类。
◆ 类元数据完了以后,开始从最顶层的超类开始输出对象实例的实际数据值。
◆ 从上至下递归输出实例的数据
序列化及反序列化介绍
序列化是指把对象转换成有序字节流,以便在网络上传输或者保存在本地文件中。序列化后的字节流保存了Java对象的状态以及相关的描述信息。客户端从文件中或网络上获得序列化后的对象字节流后,根据字节流中所保存的对象状态及描述信息,通过反序列化重建对象。本质 上讲,序列化就是把实体对象状态按照一定的格式写入到有序字节流,反序列化就是从有序字节流重建对象,恢复对象状态。序列化机制的核心作用就是对象状态的 保存与重建。
2、什么情况下需要序列化
a)当你想把的内存中的对象状态保存到一个文件中或者数据库中时候;
b)当你想用套接字在网络上传送对象的时候;
c)当你想通过RMI传输对象的时候;
3、当对一个对象实现序列化时,究竟发生了什么?
在没有序列化前,每个保存在堆(Heap)中的对象都有相应的状态(state),即实例变量(instance ariable)
6、相关注意事项
a)序列化时,只对对象的状态进行保存,而不管对象的方法;
b)当一个父类实现序列化,子类自动实现序列化,不需要显式实现Serializable接口;
c)当一个对象的实例变量引用其他对象,序列化该对象时也把引用对象进行序列化;
d)并非所有的对象都可以序列化,至于为什么不可以,有很多原因了,比如:
1.安全方面的原因,比如一个对象拥有private,public等field,对于一个要传输的对象,比如写到文件,或者进行rmi传输等等,在序列化进行传输的过程中,这个对象的private等域是不受保护的。
2. 资源分配方面的原因,比如socket,thread类,如果可以序列化,进行传输或者保存,也无法对他们进行重新的资源分配,而且,也是没有必要这样实现。
声明为static和transient类型的成员数据不能被序列化。因为static代表类的状态,transient代表对象的临时数据。
什么时候使用序列化:
一:对象序列化可以实现分布式对象。主要应用例如:rmi要利用对象序列化运行远程主机上的服务,就像在本地机上运行对象时一样。
二:java对象序列化不仅保留一个对象的数据,而且递归保存对象引用的每个对象的数据。可以将整个对象层次写入字节流中,可以保存在文件中或在网络 连接上传递。利用对象序列化可以进行对象的"深复制",即复制对象本身及引用的对象本身。序列化一个对象可能得到整个对象序列。
类通过实现java.io.serializable接口以启用其序列化功能。未实现此接口的类将无法使其任何状态序列化或反序列化。可序列化类的所有子类型本身都是可序列化的。序列化接口没有方法或字段,仅用于标识可序列化的语义。
要允许不可序列化类的子类型序列化,可以假定该子类型负责保存和还原超类型的公用(public)、受保护的(protected)和(如果可访问) 包(package)字段的状态。仅在子类型扩展的类有一个可访问的无参数构造方法来初始化该类的状态时,才可以假定子类型有此责任。如果不是这种情况, 则声明一个类为可序列化类是错误的。该错误将在运行时检测到。
在反序列化过程中,将使用该类的公用或受保护的无参数构造方法初始化不可序列化类的字段。可序列化的子类必须能够访问无参数的构造方法。可序列化子类的字段将从该流中还原。
当遍历一个图形时,可能会遇到不支持可序列化接口的对象。在此情况下,将抛出notserializableexception,并将标识不可序列化对象的类。
在序列化和反序列化过程中需要特殊处理的类必须使用下列准确签名来实现特殊方法:
writeobject方法负责写入特定类的对象的状态,以便相应的readobject方法可以还原它。通过调用 out.defaultwriteobject可以调用保存object的字段的默认机制。该方法本身不需要涉及属于其超类或子类的状态。状态是通过使用 writeobject方法或使用dataoutput支持的用于基本数据类型的方法将各个字段写入objectoutputstream来保存的。
readobject方法负责从流中读取并还原类字段。它可以调用in.defaultreadobject来调用默认机制,以还原对象的非静态和非 瞬态字段。defaultreadobject方法使用流中的信息来分配流中通过当前对象中相应命名字段保存的对象的字段。这用于处理类发展后需要添加新 字段的情形。该方法本身不需要涉及属于其超类或子类的状态。状态是通过使用writeobject方法或使用dataoutput支持的用于基本数据类型 的方法将各个字段写入objectoutputstream来保存的。
将对象写入流时需要指定要使用的替代对象的可序列化类,应使用准确的签名来实现此特殊方法:
此writereplace方法将由序列化调用,前提是如果此方法存在,而且它可以通过被序列化对象的类中定义的一个方法访问。因此,该方法可以拥有 私有(private)、受保护的(protected)和包私有(package-private)访问。子类对此方法的访问遵循java访问规则。
在从流中读取类的一个实例时需要指定替代的类应使用的准确签名来实现此特殊方法。
序列化运行时使用一个称为serialversionuid的版本号与每个可序列化类相关联,该序列号在反序列化过程中用于验证序列化对象的发送者和 接收者是否为该对象加载了与序列化兼容的类。如果接收者加载的该对象的类的serialversionuid与对应的发送者的类的版本号不同,则反序列化 将会导致invalidclassexception。可序列化类可以通过声明名为"serialversionuid"的字段(该字段必须是静态 (static)、最终(final)的long型字段)显式声明其自己的serialversionuid:
如果可序列化类未显式声明serialversionuid,则序列化运行时将基于该类的各个方面计算该类的默认serialversionuid值,如“
java(tm)对象序列化规范”中所述。不过,强烈建议所有可序列化类都显式声明serialversionuid值,原因计算默认的 serialversionuid对类的详细信息具有较高的敏感性,根据编译器实现的不同可能千差万别,这样在反序列化过程中可能会导致意外的 invalidclassexception。因此,为保证serialversionuid值跨不同java编译器实现的一致性,序列化类必须声明一个 明确的serialversionuid值。还强烈建议使用private修改器显示声明serialversionuid(如果可能),原因是这种声明 仅应用于立即声明类--serialversionuid字段作为继承成员没有用处。
java.io.serializable引发的问题——什么是序列化?在什么情况下将类序列化?
序列化就是一种用来处理对象流的机制,所谓对象流也就是将对象的内容进行流化。可以对流化后的对象进行读写操作,也可将流化后的对象传输于网络之间。 序列化是为了解决在对对象流进行读写操作时所引发的问题。序列化的实现:将需要被序列化的类实现serializable接口,该接口没有需要实现的方 法,implementsserializable只是为了标注该对象是可被序列化的,然后使用一个输出流(如:fileoutputstream)来构 造一个objectoutputstream(对象流)对象,接着,使用objectoutputstream对象的 writeobject(objectobj)方法就可以将参数为obj的对象写出(即保存其状态),要恢复的话则用输入流。
序列化:序列化是将对象转换为容易传输的格式的过程。例如,可以序列化一个对象,然后使用http通过internet在客户端和服务器之间传输该对象。在另一端,反序列化将从该流重新构造对象。是对象永久化的一种机制。确切的说应该是对象的序列化,一般程序在运行时,产生对象,这些对象随着程序的停止运行而消失,但如果我们想把某些对象(因为是对象,所以有各自不同 的特性)保存下来,在程序终止运行后,这些对象仍然存在,可以在程序再次运行时读取这些对象的值,或者在其他程序中利用这些保存下来的对象。这种情况下就 要用到对象的序列化。
只有序列化的对象才可以
服务器硬盘上把序列化的对象取出,然后通过网络传到客户端,再由客户端把序列化的对象读入内存,执行相应的处理。
对象序列化是java的一个特征,通过该特征可以将对象写作一组字节码,当在其他位置读到这些字节码时,可以依此创建一个新的对象,而且新对象的状态 与原对象完全相同。为了实现对象序列化,要求必须能够访问类的私有变量,从而保证对象状态能够正确的得以保存和恢复。相应的,对象序列化api能够在对象 重建时,将这些值还原给私有的数据成员。这是对java语言访问权限的挑战。通常用在服务器客户端的对象
交换上面,另外就是在本机的存储。
对象序列化的最主要的用处就是在传递,和保存对象(object)的时候,保证对象的完整性和可传递性。譬如通过网络传输,或者把一个对象保存成一个文件的时候,要实现序列化接口。
即使你没有用过对象序列化(serialization),你可能也知道它。但你是否知道
java还支持另外一种形式的对象持久化,外部化(externalization)?
下面是序列化和外部化在代码级的关联方式:
序列化和外部化的主要区别
外部化和序列化是实现同一目标的两种不同方法。下面让我们分析一下序列化和外部化之间的主要区别。
通过serializable接口对对象序列化的支持是内建于核心api的,但是java.io.externalizable的所有实现者必须提供 读取和写出的实现。java已经具有了对序列化的内建支持,也就是说只要制作自己的类java.io.serializable,java就会试图存储和 重组你的对象。如果使用外部化,你就可以选择完全由自己完成读取和写出的工作,java对外部化所提供的唯一支持是接口:
序列化会自动存储必要的信息,用以反序列化被存储的实例,而外部化则只保存被存储的类的标识。当你通过java.io.serializable接口 序列化一个对象时,有关类的信息,比如它的属性和这些属性的类型,都与实例数据一起被存储起来。在选择走externalizable这条路时,java 只存储有关每个被存储类型的非常少的信息。
每个接口的优点和缺点
序列化:
JAVA•优点:内建支持
•优点:易于实现
•缺点:占用空间过大
•缺点:由于额外的开销导致速度变比较慢
外部化
•优点:开销较少(程序员决定存储什么)
•优点:可能的速度提升
•缺点:虚拟机不提供任何帮助,也就是说所有的工作都落到了开发人员的肩上。
在两者之间如何选择要根据应用程序的需求来定。serializable通常是最简单的解决方案,但是它可能会导致出现不可接受的性能问题或空间问题;在出现这些问题的情况下,externalizable可能是一条可行之路。
要记住一点,如果一个类是可外部化的(externalizable),那么externalizable方法将被用于序列化类的实例,即使这个类型提供了serializable方法:
序列化机制的用途
通过对象的序列化我们可以得到对象状态信息的字节流数据,这些数据代表了当前对象的状态。当对象转化成二进制数据流之后,我们可以通过多种方式处理它,比如可以通过Socket将 数据发送的远程主机,又或者保存的本地文件中以期后用。同时,当我们通过某种方式获取了对象序列化之后的二进制数据之后,通过反序列化机制实现对象的重 建,恢复之前对象的状态。由此可知,序列化后的字节流可以应用到任何想要重建对象的地方,您所需要的就是获取这些字节流数据。
Java序列化机制解析
实现序列化的方式
Java API提供了对序列化的支持,要实现对象的序列化和反序列化,基本上包括两个步骤:
1.声明对象具有可序列化的能力
2.通过Java API实现具体的序列化处理
在Java语言中,声明对象具有可序列化的能力主要有两种方式:其一,实现Serializable接口;其二,实现Externalizable接口。两者既有区别又有联系。Java从JDK1.1开始支持对象的序列化机制,Serializable接口没有声明任何方法,实现该接口的Java类不需要对任何方法提供实现(默认情况下,定制序列化时除外),因此,该接口仅仅是一个”mark interface”,实现该接口意味着告知JVM该对象可以序列化。Java序列化机制要求所有具备序列化的对象必须实现该接口,否则是不能被序列化的,如果对于没有实现该接口的对象进行序列化时,Java API会抛出异常,无法进行序列化。
Serializable接 口提供了默认的序列化行为,在默认情况下,开发人员只需实现该接口,无需进行其他额外的操作,即可实现的对象的序列化。当然,所谓默认的处理,必然隐藏着 对序列化对象的默认操作,比如对象的哪些属性被序列化。默认情况下,只对对象中非静态的字段(对象的成员数据也会被保存,不能序列化任何成员方法和静态成员变量)以及非瞬时的字段(transient,只能用来修饰字段)进行序列化,其他的字段是不允许被序列化的。 这种情况的具体表现就是,在序列化的有序字节流中没有保存不能被序列化的字段的状态,因此,在反序列化时,这些字段状态是不能被重建的。但是有一点需要注 意的是,经过反序列化后的对象,除了对可被序列化的字段状态进行重建之外,其他的没有被序列化的字段作为对象属性的一部分,也在对象重建时得以初始化。但 是这些字段的状态是不被保存的,重建后的这些属性仅仅是系统赋予的默认值,而非保存了对象序列化之前的状态。
实现Serializable接口除了提供默认的序列化方式之外,同样允许开发人员定制序列化,即通过实现以下相同签名的方法来实现:
序列化方法:
private void writeObject(java.io.ObjectOutputStream out) throws IOException
反序列化方法:
private void readObject(java.io.ObjectInputStream in) throws IOException, ClassNotFoundException;
其中,writeObject方法用于定制序列化,readObject方法用于实现定制反序列化。
在示例代码中会对这两个方法的使用进行展示。
Externalizable接口集成自Serializable接口,实现该接口意味着对象本身完全掌控自己的序列化方式。该接口JDK源码如下:
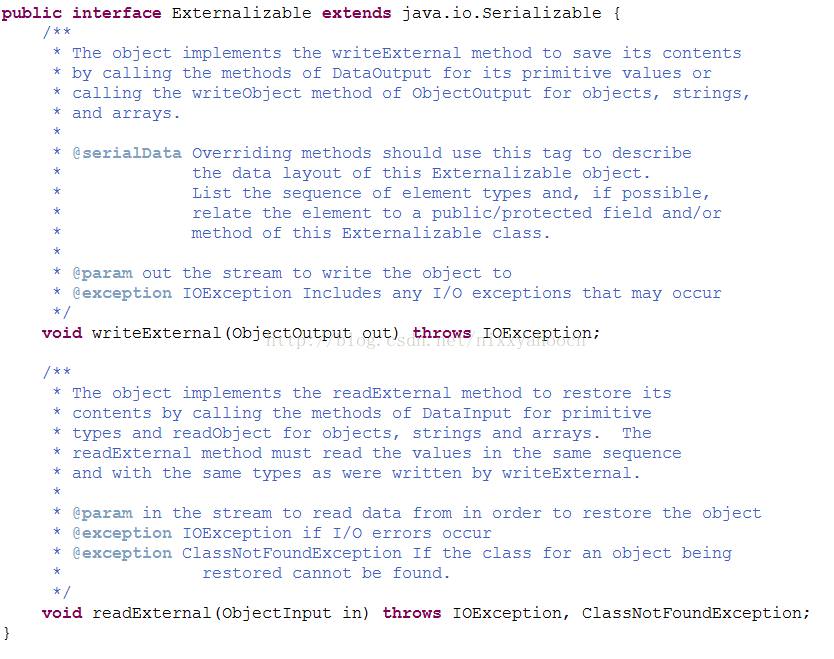
Externalizable接口定义了两个方法:writeExternal(ObjectOutput out)和readExternal(ObjectInput in)。write方法用于实现定制序列化,read方法用于实现定制反序列化。
基于Externalizable接口的定制和基于Serializable接口的定制有所不同。基于Externalizable接口的定制是通过实现上述两个方法实现的,而且方法中操作的参数也不一样,基于Externalizable接口是通过操作ObejectOutput类和ObjectInput类实现的。而基于Serializable接口是通过操作ObjectOutputStream类和ObjectInputStream类实现的。至于两种方式的序列化定制方式会在稍后的示例中进行展示。
哪些数据被序列化了?
我们采用默认的序列化方式(仅仅直接实现Serializable接口)序列化对象时,默认的,只将非静态的和no-transient字段进行序列化,除此之外的其他域在默认情况下是不进行序列化的,也就是说,在序列化的字节流数据中没有对这两种类型数据的记录。这是为什么呢?如果是从代码级别上分析,从JDK源码可知,JDK源码进行了默认的处理,然后将静态属性和瞬时属性排除在序列化之外,但为什么会选择这样的实现呢?我们都知道,对象序列化的本质是将对象的状态通过有序字节流进行保存或传输,由此,问题的焦点应该是对象的状态。静态变量是类变量,属于整个类,并非专属于每个对象实例,因此,不序列化静态变量时合理的。瞬时变量,指的是被transient关键字修饰的变量,该关键字表示为瞬时的,即不做持久化处理的,以此来控制属性是否被包含进入序列化的字节流中。因此,在序列化时,排除transient关键字修饰的属性也是合理的。
需要注意的是,没有被序列化的属性不会出现在序列化后的有序字节流中,但是,我们在反 序列化时,是可以访问这些变量的。这是因为,序列化的过程保存了你所期望保存的对象的状态(属性当前值),反序列化就是重建对象的过程,在这个过程中,字 节流中所保存的对象状态被重新赋予了新建的对象。此时,对于没有被序列化的属性也是存在的,因为其是类定义的一部分,在新建的对象中是必然存在的。唯一不 同的是,他们的值是类定义的默认值,而非是来自字节流中保存的状态。这也恰恰反映了序列化的本质:保存对象的状态。
那么,到底哪些数据被序列化到了有序字节流中呢?字节流数据包含了non-static和non-transient类型的成员数据、类名、类签名、可序列化的基类以及类中引用的其他对象。
针对于父类,有几点原则:
1.如果基类实现了Serializable接口,则其子类默认的是可序列化的,不必显示声明;
2.如果基类没有实现Serializable接口,在反序列化时,会调用基类的无参构造方法,重建基类对象只不过是不会保留基类对象状态。
基于Serializable接口
默认序列化
基于Serializable接口的默认序列化步骤为:首先,进行序列化声明,代码如下:

实现了Serializable接口的Java类与我们平时定义Java类没有太大区别,唯一需要注意的是serialVersionUID属性。每个实现Serializable接口的对象都有一个serialVersionUID,长整型,64位,唯一标示了该序列化对象。在类定义中,可以显示的定义该静态变量,也可以不定义。在不定义的情况下,Java编译器会隐式的生成该变量。强烈建议显示定义。那么,该变量有什么用途呢?反序列化兼容控制。serialVersionUID相同才能进行反序列化。例如:远程主机需要反序列化对象C,如果在本地和远程主机内的C对象持有的serialVersionUID不同,即使两个类其它部分完全一样,也是不能成功反序列化话的,会抛出异常。因此,如果对类做了修改,为了保证版本对序列化兼容,该变量的值保持不变。从另一个角度来讲,不期望不同版本的类对序列化兼容,则改变该变量值。
然后,通过Java API进行实际的序列化处理。我们选择的场景是:将对象进行序列化,然后保存到本地文件中。然后,从本地文件读取序列化后的有序字节流,进行反序列化,重建对象。代码示例如下:

说明:在实际的对象实例化过程中,涉及到的Java类是ObjectOutputStream和ObjectInputStream。这两个类负责对象序列化的主要工作。
定制序列化
上面的代码示例中,展示了最为基本的默认的对象序列化和反序列化方式。之所以称之为是基本的,是因为,我们在对自定义的类进行序列化时完全没有进行任何“干涉”, 系统默认的选择了类定义中符合规则的属性进行序列化,因此这是一种默认的方式。与之相对应的是,我们可以定制序列化及反序列化,以满足实际的需要。例如: 序列化的对象一般在网络上进行传输,所以安全性是必须要考虑的问题。大部分情况下,我们期望对类似于密码等这样的敏感信息进行加密处理,以密文的形式在网 络间传输,增强数据的安全性。但是,通过我们上述的方式进行序列化,默认的处理方式是不能保证密码的密文传输的。因此,针对此类问题,我们必须能够定制对 象的序列化和反序列化过程,只有这样才能将我们的业务逻辑加入其中,以满足实际应用的需要。
如何实现定制呢?
定制序列化和反序列化与上述序列化方式的不同在于:自定义类的实现。
首先,同样,自定义的类要实现Serializable接口,这是序列化处理的前提。不同的是,在定制序列化时,需要根据我们的实际需要,重写writeObject和readObject方法,完成序列化和反序列化的定制。示例代码如下:
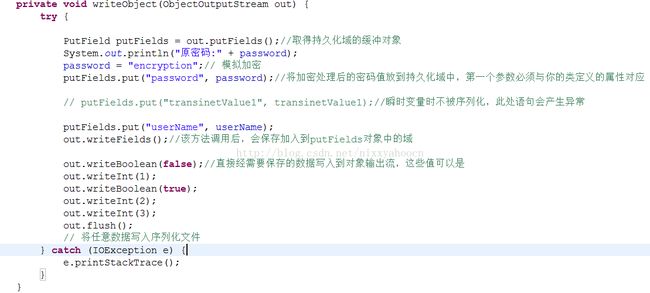

说明:定制序列化过程中,序列化和反序列化读取信息的顺序要保持一致,否则会出现意想不到的后果。
基于Externalizable接口
实现Extenalizable接口的类将完全由自己控制自身的序列化和反序列化。示例代码如下:

对象序列化及反序列化测试代码:

测试输出结果为:
序列化带来的问题
网络传输的安全性
对象进行序列化之后转化成有序的字节流在网络上进行传输,如果通过默认的序列化方式, 则代码都是以明文的方式进行传输。这种情况下,部分字段的安全性是不能保障的,特别是像密码这样的安全敏感的信息。因此,如果您需要对部分字段信息进行特 殊的处理,那么应当选择定制对象的序列化方式,例如对密码等敏感信息进行加密处理。
类自身封装的安全性
对对象进行序列化时,类中所定义的被private、final等 访问控制符所修饰的字段是直接忽略这些访问控制符而直接进行序列化的,因此,原本在本地定义的想要一次控制字段的访问权限的工作都是不起作用的。对于序列 化后的有序字节流来说一切都是可见的,而且是可重建的。这在一定程度上削弱了字段的安全性。因此,如果您需要特别处理这些信息,您可以选择相应的方式对这 些属性进行加密或者其他可行的处理,以尽量保持数据的安全性。
总结
1.通过序列化和反序列化实现了对象状态的保存、传输以及对象的重建。在进行对象序列化时,开发人员可以根据自身情况,灵活选择默认方式或者自定义方式实现对象的序列化和反序列化。
2.序列化机制是Java中对轻量级持久化的支持。
3.序列化的字节流数据在网上传输的安全问题需要引起大家足够的注意。
4.序列化破坏了原有类的数据的”安全性“,例如private属性不起作用的。
序列化就是一种用来处理对象流的机制,所谓对象流也就是将对象的内容进行流化。可以对流化后的对象进行读写操作,也可将流化后的对象传输于网络之间。序列化是为了解决对象流读写操作时可能引发的问题(如果不进行序列化可能会存在数据乱序的问题)。
要实现序列化,需要让一个类实现Serializable接口,该接口是一个标识性接口,标注该类对象是可被序列化的,然后使用一个输出流来构造一个对象输出流并通过writeObject(Object)方法就可以将实现对象写出(即保存其状态);如果需要反序列化则可以用一个输入流建立对象输入流,然后通过readObject方法从流中读取对象。序列化除了能够实现对象的持久化之外,还能够用于对象的深度克隆。
1、java序列化简介
序列化就是指对象通过写出描述自己状态的数值来记录自己的过程,即将对象表示成一系列有序字节,java提供了将对象写入流和从流中恢复对象的方法。对象能包含其它的对象,而其它的对象又可以包含另外的对象。JAVA序列化能够自动的处理嵌套的对象。对于一个对象的简单域,writeObject()直接将其值写入流中。当遇到一个对象域时,writeObject()被再次调用,如果这个对象内嵌另一个对象,那么,writeObject()又被调用,直到对象能被直接写入流为止。程序员所需要做的是将对象传入ObjectOutputStream的writeObject()方法,剩下的将有系统自动完成。
要实现序列化的类必须实现的java.io.Serializable或java.io.Externalizable接口,否则将产生一个NotSerializableException。该接口内部并没有任何方法,它只是一个"tagging interface",仅仅"tags"它自己的对象是一个特殊的类型。类通过实现java.io.Serializable接口以启用其序列化功能。未实现此接口的类将无法使其任何状态序列化或反序列化。可序列化类的所有子类型本身都是可序列化的。序列化接口没有方法或字段,仅用于标识可序列化的语义。Java的"对象序列化"能让你将一个实现了Serializable接口的对象转换成一组byte,这样日后要用这个对象时候,你就能把这些byte数据恢复出来,并据此重新构建那个对象了。
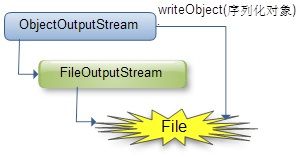
序列化图示
反序列化图示
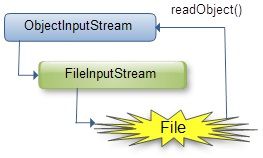
在序列化的时候,writeObject与readObject之间是有先后顺序的。readObject将最先write的object read出来。用数据结构的术语来讲就称之为先进先出!
2、序列化的必要性及目的
Java中,一切都是对象,在分布式环境中经常需要将Object从这一端网络或设备传递到另一端。这就需要有一种可以在两端传输数据的协议。Java序列化机制就是为了解决这个问题而产生。
Java序列化支持的两种主要特性:
Java的RMI使本来存在于其他机器的对象可以表现出就像本地机器上的行为。
将消息发给远程对象时,需要通过对象序列化来传输参数和返回值.
Java序列化的目的:
支持运行在不同虚拟机上不同版本类之间的双向通讯;
定义允许JAVA类读取用相同类较老版本写入的数据流的机制;
定义允许JAVA类写用相同类较老版本读取的数据流的机制;
提供对持久性和RMI的序列化;
产生压缩流且运行良好以使RMI能序列化;
辨别写入的是否是本地流;
保持非版本化类的低负载;
3、序列化异常
序列化对象期间可能抛出6种异常:
InvalidClassException通常在重序列化流无法确定类型时或返回的类无法在取得对象的系统中表示时抛出此异常。异常也在恢复的类不声明为public时或没有public缺省(无变元)构造器时抛出。
NotSerializableException通常由具体化对象(负责自身的重序列化)探测到输入流错误时抛出。错误通常由意外不变量值指示,或者表示要序列化的对象不可序列化。
StreamCorruptedException在存放对象的头或控制数据无效时抛出。
OptionalDataException流中应包含对象但实际只包含原型数据时抛出。
ClassNotFoundException流的读取端找不到反序列化对象的类时抛出。
IOException要读取或写入的对象发生与流有关的错误时抛出。
4、序列化一个对象
序列化一个对象,以及对序列化后的对象进行操作,需要遵循以下3点:
1、 一个对象能够序列化的前提是实现Serializable接口或Externalizable接口,Serializable接口没有方法,更像是个标记。有了这个标记的Class就能被序列化机制处理。
2、 写个程序将对象序列化并输出。ObjectOutputStream能把Object输出成Byte流。
3、 要从持久的文件中读取Bytes重建对象,我们可以使用ObjectInputStream。
在序列化时,有几点要注意的:
当一个对象被序列化时,只序列化对象的非静态成员变量Non-static,不能序列化任何成员方法和静态成员变量,不能序列化Non-transient变量。
如果一个对象的成员变量是一个对象,那么这个对象的数据成员也会被保存。
如果一个可序列化的对象包含对某个不可序列化的对象的引用,那么整个序列化操作将会失败,并且会抛出一个NotSerializableException。可以通过将这个引用标记为transient,那么对象仍然可以序列化。对于一些比较敏感的不想序列化的数据,也可以采用该标识进行修饰。
http://www.cnblogs.com/redcreen/articles/1955307.html
如何序列化一个对象
一个对象能够序列化的前提是实现Serializable接口,Serializable接口没有方法,更像是个标记。
有了这个标记的Class就能被序列化机制处理。
import java.io.Serializable;
class TestSerial implements Serializable {
public byte version= 100;
public byte count= 0;
}
然后我们写个程序将对象序列化并输出。ObjectOutputStream能把Object输出成Byte流。
我们将Byte流暂时存储到temp.out文件里。
public static void main(String args[]) throws IOException {
FileOutputStream fos = new FileOutputStream("temp.out");
ObjectOutputStream oos = new ObjectOutputStream(fos);
TestSerial ts = new TestSerial();
oos.writeObject(ts);
oos.flush();
oos.close();
}
如果要从持久的文件中读取Bytes重建对象,我们可以使用ObjectInputStream。
public static void main(String args[]) throws IOException {
FileInputStream fis = new FileInputStream("temp.out");
ObjectInputStream oin = new ObjectInputStream(fis);
TestSerial ts = (TestSerial) oin.readObject();
System.out.println("version="+ts.version);
}
执行结果为100.
对象的序列化格式
将一个对象序列化后是什么样子呢?打开刚才我们将对象序列化输出的temp.out文件
以16进制方式显示。内容应该如下:
AC ED 00 05 73 72 00 0A 53 65 72 69 61 6C 54 65
73 74 A0 0C 34 00 FE B1 DD F9 02 00 02 42 00 05
63 6F 75 6E 74 42 00 07 76 65 72 73 69 6F 6E 78
70 00 64
这一坨字节就是用来描述序列化以后的TestSerial对象的,我们注意到TestSerial类中只有两个域:
publicbyte version = 100;
publicbyte count = 0;
且都是byte型,理论上存储这两个域只需要2个byte,但是实际上temp.out占据空间为51bytes,也就是说除了数据以外,还包括了对序列化对象的其他描述
Java的序列化算法
序列化算法一般会按步骤做如下事情:
◆将对象实例相关的类元数据输出。【元数据】
◆递归地输出类的超类描述直到不再有超类。【超类描述】
◆类元数据完了以后,开始从最顶层的超类开始输出对象实例的实际数据值。【超类-类的实际数据值】
◆从上至下递归输出实例的数据【实例数据值】
我们用另一个更完整覆盖所有可能出现的情况的例子来说明:
class parent implements Serializable {
int parentVersion= 10;
}
class contain implements Serializable{
Int containVersion= 11;
}
public class SerialTest extends parent implements Serializable {
int version= 66;
contain con = new contain();
public int getVersion(){
return version;
}
public static void main(String args[]) throws IOException {
FileOutputStream fos = new FileOutputStream("temp.out");
ObjectOutputStream oos = new ObjectOutputStream(fos);
SerialTest st = new SerialTest();
oos.writeObject(st);
oos.flush();
oos.close();
}
}
AC ED: STREAM_MAGIC.声明使用了序列化协议.
00 05: STREAM_VERSION.序列化协议版本.
0x73: TC_OBJECT.声明这是一个新的对象.
0x72: TC_CLASSDESC.声明这里开始一个新Class。
00 0A: Class名字的长度.
53 65 72 69 61 6c 54 65 73 74:SerialTest,Class类名.
05 52 81 5A AC 66 02 F6:SerialVersionUID,序列化ID,如果没有指定,
则会由算法随机生成一个8byte的ID.
0x02:标记号.该值声明该对象支持序列化。
00 02:该类所包含的域个数。
0x49:域类型. 49代表"I",也就是Int.
00 07:域名字的长度.
76 65 72 73 69 6F 6E: version,域名字描述.
0x4C:域的类型.
00 03:域名字长度.
63 6F 6E:域名字描述,con
0x74: TC_STRING.代表一个new String.用String来引用对象。
00 09:该String长度.
4C 63 6F 6E 74 61 69 6E 3B:Lcontain;, JVM的标准对象签名表示法.
0x78: TC_ENDBLOCKDATA,对象数据块结束的标志
0x72: TC_CLASSDESC.声明这个是个新类.
00 06:类名长度.
70 61 72 65 6E 74: parent,类名描述。
0E DB D2 BD 85 EE 63 7A:SerialVersionUID,序列化ID.
0x02:标记号.该值声明该对象支持序列化.
00 01:类中域的个数.
0x49:域类型. 49代表"I",也就是Int.
00 0D:域名字长度.
70 61 72 65 6E 74 56 65 72 73 69 6F 6E:parentVersion,域名字描述。
0x78: TC_ENDBLOCKDATA,对象块结束的标志。
0x70: TC_NULL,说明没有其他超类的标志。.
0000000A: 10,parentVersion域的值.
00000042: 66, version域的值.
0x73: TC_OBJECT,声明这是一个新的对象.
0x72: TC_CLASSDESC声明这里开始一个新Class.
00 07:类名的长度.
63 6F 6E 74 61 69 6E: contain,类名描述.
FC BB E6 0E FB CB 60 C7:SerialVersionUID,序列化ID.
0x02: Various flags.标记号.该值声明该对象支持序列化
00 01:类内的域个数。
0x49:域类型. 49代表"I",也就是Int..
00 0E:域名字长度.
63 6F 6E 74 61 69 6E 56 65 72 73 69 6F 6E:containVersion,域名字描述.
0x78: TC_ENDBLOCKDATA对象块结束的标志.
0x70:TC_NULL,没有超类了。
0000000B: 11,containVersion的值.
这个例子是相当的直白啦。SerialTest类实现了Parent超类,内部还持有一个Container对象。
序列化后的格式如下:
AC ED 00 05 7372 00 0A 53 65 72 69 61 6C 54 65
73 74 05 52 81 5A AC 66 02 F6 02 00 0249 00 07
76 65 72 73 69 6F 6E4C00 03 63 6F 6E74 00 09
4C63 6F 6E 74 61 69 6E 3B 7872 00 06 70 61 72
65 6E 74 0E DB D2 BD 85 EE 63 7A 02 00 0149 00
0D 70 61 72 65 6E 74 56 65 72 73 69 6F 6E 78 70
0000000A 0000004273 72 00 07 63 6F 6E 74
61 69 6E FC BB E6 0E FB CB 60 C7 02 00 0149 00
0E 63 6F 6E 74 61 69 6E 56 65 72 73 69 6F 6E 78
700000000B
我们来仔细看看这些字节都代表了啥。
开头部分,见颜色:
AC ED: STREAM_MAGIC.声明使用了序列化协议.
00 05: STREAM_VERSION.序列化协议版本.
0x73: TC_OBJECT.声明这是一个新的对象.
序列化算法的第一步就是输出对象相关类的描述。例子所示对象为SerialTest类实例,因此接下来输出SerialTest类的描述。见颜色:
0x72: TC_CLASSDESC.声明这里开始一个新Class。
00 0A: Class名字的长度.
53 65 72 69 61 6c 54 65 73 74:SerialTest,Class类名.
05 52 81 5A AC 66 02 F6:SerialVersionUID,序列化ID,如果没有指定,则会由算法随机生成一个8byte的ID.
0x02:标记号.该值声明该对象支持序列化。
00 02:该类所包含的域个数。
接下来,算法输出其中的一个域,intversion=66;见颜色:
0x49:域类型. 49代表"I",也就是Int.
00 07:域名字的长度.
76 65 72 73 69 6F 6E: version,域名字描述.
然后,算法输出下一个域,contain con = new contain();这个有点特殊,是个对象。描述对象类型引用时需要使用JVM的标准对象签名表示法,见颜色:
0x4C:域的类型.
00 03:域名字长度.
63 6F 6E:域名字描述,con
0x74: TC_STRING.代表一个new String.用String来引用对象。
00 09:该String长度.
4C 63 6F 6E 74 61 69 6E 3B:Lcontain;, JVM的标准对象签名表示法.
0x78: TC_ENDBLOCKDATA,对象数据块结束的标志
.接下来算法就会输出超类也就是Parent类描述了,见颜色:
0x72: TC_CLASSDESC.声明这个是个新类.
00 06:类名长度.
70 61 72 65 6E 74: parent,类名描述。
0E DB D2 BD 85 EE 63 7A:SerialVersionUID,序列化ID.
0x02:标记号.该值声明该对象支持序列化.
00 01:类中域的个数.
下一步,输出parent类的域描述,intparentVersion=100;同见颜色:
0x49:域类型. 49代表"I",也就是Int.
00 0D:域名字长度.
70 61 72 65 6E 74 56 65 72 73 69 6F 6E:parentVersion,域名字描述。
0x78: TC_ENDBLOCKDATA,对象块结束的标志。
0x70: TC_NULL,说明没有其他超类的标志。.
到此为止,算法已经对所有的类的描述都做了输出。下一步就是把实例对象的实际值输出了。这时候是从parent Class的域开始的,见颜色:
0000000A: 10,parentVersion域的值.
还有SerialTest类的域:
00000042: 66, version域的值.
再往后的bytes比较有意思,算法需要描述contain类的信息,要记住,现在还没有对contain类进行过描述,见颜色:
0x73: TC_OBJECT,声明这是一个新的对象.
0x72: TC_CLASSDESC声明这里开始一个新Class.
00 07:类名的长度.
63 6F 6E 74 61 69 6E: contain,类名描述.
FC BB E6 0E FB CB 60 C7:SerialVersionUID,序列化ID.
0x02: Various flags.标记号.该值声明该对象支持序列化
00 01:类内的域个数。
.输出contain的唯一的域描述,intcontainVersion=11;
0x49:域类型. 49代表"I",也就是Int..
00 0E:域名字长度.
63 6F 6E 74 61 69 6E 56 65 72 73 69 6F 6E:containVersion,域名字描述.
0x78: TC_ENDBLOCKDATA对象块结束的标志.
这时,序列化算法会检查contain是否有超类,如果有的话会接着输出。
0x70:TC_NULL,没有超类了。
最后,将contain类实际域值输出。
0000000B: 11,containVersion的值.
serialVersionUID值的重要作用
根据上面的分析,可以发现如果一个类可序列化,serialVersionUID建议给一个确定的值,不要由系统自动生成,否则在增减字段(不能修改字段类型及长度)时,如果两边的类的版本不同会导致反序列化失败.
注意问题
如果序列化时代码这样写:
SerialTest st = new SerialTest();
oos.writeObject((parent)st);
会发现序列化的对象依然是SerialTest,如果在分布式环境中用Parent反序列化(调用段不存在SerialTest),会造成ClassNotFoundException.
7.1 定制数据格式的序列化
验证怎样用writeObject和readObject方法编码一个定制数据格式。当有大量持久性数据时,数据应该以简洁、精简的格式存放。此例子用一个矩形对称阵列,只对其一半数据序列化,即只写/读一半数据再恢复成完整阵列。
7.2 非序列化超类的序列化
当一个已序列化的子类的超类没有序列化时,子类必须显式存储超类的状态。
7.3 超类具体化的具体化
当用具体化接口时,一个具体化对象必须运行writeExternal()方法存储对象的状态,用readExternal方法读取对象的状态。此例子验证了一个怎样存储和恢复它可具体化超类对象的状态。当一个可具体化对象的超类也具体化,子类要在它自己的writeExternal()和readExternal()方法中调用其超类的writeExternal()和readExternal()方法。
7.4 超类非具体化的具体化
当用具体化接口时,一个具体化对象必须运行writeExternal()方法存储对象的状态,用readExternal()方法读取对象的状态。此例子验证了一个对象怎样存储和恢复它非具体化超类的状态。当一个可具体化对象的超类没有具体化,子类必须用它自己的writeExternal()和readExternal()方法明确存储和恢复其超类的可具体化对象状态。