之前老王曾经写过一篇文章简单探讨过WSFC 2016的故障域以及站点感知功能,但是随着继续深入的应用和使用,老王发现站点感知这个概念在WSFC 2016体系里面贯穿到了很多功能,因此决定再写一篇,主要与大家探讨在ReallyWorld中应该如何思考站点感知,故障域,以及WSFC 2016健康服务功能
# 1. 初谈WSFC 2016故障域
故障域通常来说,只有当我们作为交付SLA,或享用SLA的时候会听到这个概念,例如,当我们购买了某云厂商的云服务,它们会保证很多个9,但前提是我们要把云服务里面的多个应用虚拟机放在不同的故障域,对于使用者来说,通常情况下云厂商会告诉你,放在不同的故障域,您的虚拟机就会被放在不同的机架,永远不会被一起维护,一起出现故障的几率很低等等。
如果作为交付方,我们则需要在后台设定故障域这套policy,故障域不是一项固定的技术,它应该是一个规范,引入故障域规范后,管理员就应该知道,不应该同时对一个用户所有故障域的机器一同做维护,技术层面会通过群集系统或VIM系统确保不同故障域资源 始终被放在不同机架或机柜上,实现到这一步才算是逻辑定义+物理实现,至于物理能不能实现,还是取决于基础架构对于故障域的感知,WSFC2016中支持逻辑定义Chassis,rack,site三种故障域级别。

目前能够真正实现故障域感知的只有S2D功能,S2D一旦感知到WSFC配置了Chassis或rack故障域级别,会始终确保extent多个副本撒到不同Chassis或rack

# 2.再谈站点感知与故障域
站点感知的主要作用老王认为有七
故障转移规则:当配置站点感知后,应用会首先尝试在同一站点的节点进行故障转移,反相关性和可用所有者配置会盖过站点感知
排水维护规则:应用会首先尝试在同一站点的节点进行排水,反相关性和可用所有者配置会盖过站点感知
站点特定心跳:只有为群集配置了站点感知功能后,我们才可以配置站点心跳检测频率
站点票数修剪:配置了站点感知功能后,我们可以配置首选站点功能,被选中首选站点的节点在50/50中会获胜,非首选站点自动去掉一票
层次首选站点:可以配置群集级别首选站点,实现非首选站点票数修剪,也可以配置群集组级别首选站点,实现多主首选
存储站点亲和:配置站点感知后,默认情况下虚拟机会寻找CSV所在的站点,站点感知逻辑认为虚拟机和CSV在同一站点帮助提高效率,通过配置存储首选站点可以始终确保虚拟机和CSV位于同站点,如果虚拟机发现当前和CSV不在同一站点,将在一分钟后移至
延伸群集配置:当我们配置延伸群集时,实际上一个延伸群集是两块,一块是群集上面的应用,一块是经过复制自动故障转移的存储,虽然存储可以做到自动跨站点故障转移,但是延伸群集存储复制是不考虑多站点问题的,它不懂,只知道复制磁盘内容到指定节点,以及和群集联动,但是我们需要为应用考虑多站点故障转移的问题,默认情况下应用会转移至所有可用节点,可能虚拟机会转移到远程站点,但是实际上这时候提供存储的还是主站点,这时主站点访问效率就会降低,因此延伸群集最佳实践还是配合上站点感知功能,实现底层的存储故障转移,也实现应用最佳可用性,实现应用默认在本地故障转移,默认始终和本地存储在一起
当我们思考一个跨站点的群集架构时,除了网络,存储,仲裁那些该考虑的点,另外一点需要考虑的就是群集的放置策略,很多时候如果忽略了群集放置策略就会导致额外的停机时间,如果利用好了群集放置策略又能解决很多复杂问题
站点感知,说穿了,老王认为它和S2D故障域感知是两回事,站点故障感知实现的是在群集中定义出站点架构,让故障转移,排水,心跳,仲裁执行时可以多出来一个参考项目,将我们脑袋里面的多站点架构通过软件定义出来显示,并且让群集组件参照它去进行工作。
站点感知定义是WSFC2016实现出来的方法,其中有的功能我们在以前的旧版本也可以实现,例如应用首先在本地站点故障转移,以前我们是定义首选所有者,站点票数修建,以前我们是定义LowerQuorumPriorityNodeID,WSFC 2016站点故障感知的新方法与以往不同的是,把这些群集里面不同的功能,通过一个站点感知功能给串了起来,这是它的厉害之处,同时站点感知支持通过PS批量配置,管理起来比2016之前旧方案方便,总之,大家需要慢慢的去接受这个概念,并试着应用它,让多站点群集架构更加完善。
# 3.终谈故障域与健康服务
通过总结,老王认为在WSFC2016中,故障域的定义,主要有三层用途
1.配合S2D这等应用实现故障域感知 (我希望未来可以有越来越多像S2D这样可以实现故障域感知的应用)
2.配合WSFC实现站点感知,以此控制站点内站点间,故障转移,排水维护,心跳检测,仲裁执行
3.配合健康服务实现定位排错
当我们在powershell里面创建的一个个故障域,其实就是一个个逻辑定义文本,如果没有S2D,WSFC这些能够感知到它们的组件,它们就只是一个普通的Text,不会起到作用,只有有能够感知到它们的组件,定义的故障域级别才能物理实现作用
理清这个概念后我们再来看下健康服务功能,之前老王讲WSFC 2016系列的时候把它漏掉了,特地补上
基本上大家可以把它理解为一个WSFC自身的监控功能,通过健康服务可以帮助我们关注某一个群集应用,群集组件的性能收集,工作状态,对它不同层级的运行状态进行事件报告。
目前健康服务还只能for S2D,当我们在群集中启用S2D后,默认就开启了健康服务功能,健康服务会日常监控S2D的运作,收集它的性能报告,不同于一般的事件日志,老王认为健康服务所收集的日志,显示出来非常友好实在,管理员一目了然。
例如这些

当我们需要使用健康服务 监视S2D时,输入以下命令即可
Get-StorageSubSystem *Cluster* | Debug-StorageSubSystem
参数字段
严重性
问题实用描述
推荐解决问题下一个步骤
它的物理位置 如果有定义故障域,按照嵌套关系显示出来当前故障警报在那个站点下的那个机架上的那个机柜那台服务器
资源的说明,如果有定义故障域,也将按照嵌套关系显示

区别于一般的监控软件,老王为什么说它友好呢,是因为它的错误显示的很明确,可以直接告诉你网线掉了,那块网卡,那个服务器失去连接了,或是那块磁盘掉了
如图所示,有一个关键级别的日志,提示hv01失联,下面location和description按照嵌套关系自动显示出所在位置或地址
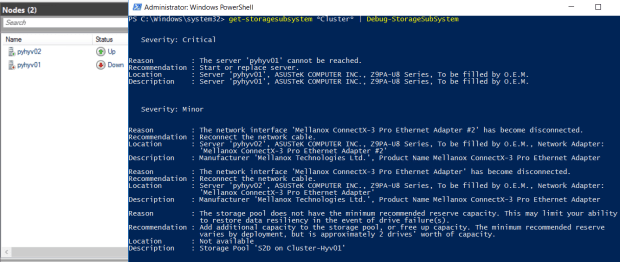
Get-StorageSubSystem *Cluster* | Debug-StorageSubSystem这条命令仅在群集开启S2D后才可以运行
默认情况下此命令的执行显示的是会影响到S2D群集整体运作的日志,这些故障大多数和硬件或配置有关
也可以运行
Get-Volume -FileSystemLabel
Get-FileShare -Name
这将返回 仅影响到指定文件共享或卷层级的故障日志,这些故障通常和容量规划或复原功能配置有关
健康服务除了监控故障日志,另外一个点是性能收集,收集S2D运作过程中一些实用的性能参数,如CPU利用率,IOP,容量。
执行命令Get-StorageSubSystem *Cluster* | Get-StorageHealthReport显示S2D整体性能报告

显示指定秒间隔内的S2D性能报告
Get-StorageSubSystem Cluster* | Get-StorageHealthReport -Count
显示S2D某一共享或卷的性能报告
Get-Volume -FileSystemLabel
Get-StorageNode -Name
另外一项功能,健康服务功能也可以用于监控S2D运作过程中正在执行的重要作业
Get-StorageHealthAction
如果当前S2D正在执行以下操作,将显示
即将失败的、 失去连接或无响应物理磁盘
当前存储池正在更换物理磁盘
还原完整复原数据
重新平衡存储池
基本上健康服务目前主要实现这三项功能,微软希望通过健康服务功能帮助群集管理员提高监控运维效率,采用实用的监控日志和性能指标,监控日志可以和故障域功能相整合,当发生错误时可以自动嵌套故障域关系,帮助管理员定位问题位置,目前该功能仅限用于S2D,老王希望未来越来越多的群集功能可以支持监控服务。
本文老王主要和大家探讨了下概念,如需要实作,请参考老王另外一篇博客 WSFC2016 故障域站点感知