Abstract
从Bert到Transformer到Attention,想要了解这一套体系的内部机制,便从将Attention机制运用到NLP问题中的第一篇论文开始阅读。
Neural Machine Translation(NMT) 旨在建一个单个神经网络,这个网络可以共同调整以最大化模型的表现。
在传统的Encoder-Decoder模型中,源文本被Encoder转化为一个固定长度的向量,而Decoder运用该向量生成翻译文本。在这篇文章,作者猜想,这个固定长度的向量可能是提升表现的一个关键所在,并提出,通过以下方法来扩展该模型:允许该模型自动寻找原文本中的哪一部分和预测目标单词相关,而无需将这一功能实现为一个独立的较为困难的部分。
Introduction
在过去提出来的Encoder-Decoder模型中,两部分是共同调整以在给定的训练样本中,使得到正确翻译的概率最大。
文章提出的模型和以往模型的最大不同是,不再尝试编码乘一个固定长度的向量,而是编码成一个向量序列并在Decoder的过程中自动选择向量的子集。
以往的模型由于所使用的Encoder-Decoder都是由RNN构成,其局限性在于无法记忆长距离的语义信息,因此模型对于长句子翻译效果很差,但是这篇文章提出的模型对以往的模型进行了改进,尤其是在对于长序列文本的提升更为明显。
Background
从概率学的角度来思考,即把翻译这一任务用数学模型来表示,如下:
\[ \arg \max _{\mathbf{y}} p(\mathbf{y} | \mathbf{x}) \]
其中,x是输入,y是输出。
对于训练过程来说,如果把NMT作为一个黑盒,则输入x、y,不断训练调整参数使条件概率最大。而在测试过程中,则是输入x,经过已经训练好的黑盒,输出y,即我们想得到的目标文本。
RNN ENCODER–DECODER
在RNN Encoder-Decoder Framework中,
\[ \mathbf{x}=\left(x_{1}, \cdots, x_{T_{x}}\right) \]
被Encoder读取并转化为向量c。用公式表达为:
\[ h_{t}=f\left(x_{t}, h_{t-1}\right) \]
\[ c=q\left(\left\{h_{1}, \cdots, h_{T_{x}}\right\}\right) \]
其中,ht是在时间t时刻的隐藏状态(hidden state),c是由一系列隐藏状态产生的向量。
Decoder经常被训练在给定上下文向量c和之前的所有预测单词的前提下,来预测下一个单词。即:
\[ p(\mathbf{y})=\prod_{t=1}^{T} p\left(y_{t} |\left\{y_{1}, \cdots, y_{t-1}\right\}, c\right) \]
运用RNN网络,每一个条件概率被建模为:
\[ p\left(y_{t} |\left\{y_{1}, \cdots, y_{t-1}\right\}, c\right)=g\left(y_{t-1}, s_{t}, c\right)\]
其中,g是一个非线性、可能含有多层次、输出yt的概率分布的函数,st是RNN的隐藏状态。
LEARNING TO ALIGN AND TRANSLAT
Align是对齐的意思。
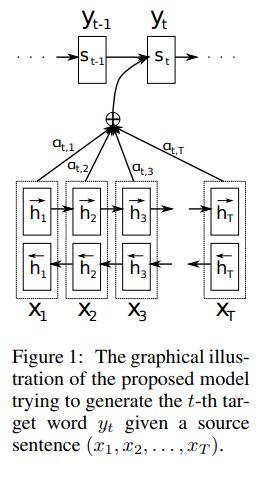
文章提出了一个用于神经网络机器翻译的新的结构。这个新的结构包括由双向RNN构成的Encoder和一个仿真在输入端搜索的Decoder。
DECODER
在新的模型中,我们定义每个条件概率如下:
\[ p\left(y_{i} | y_{1}, \ldots, y_{i-1}, \mathbf{x}\right)=g\left(y_{i-1}, s_{i}, c_{i}\right) \]
其中:
\[ s_{i}=f\left(s_{i-1}, y_{i-1}, c_{i}\right) \]
与之前的公式对比,可以看到概率分布是基于对应每一个单词的单独的上下文向量ci。
这个ci是由一系列的注释annotation决定的,这个是注释是Encoder将输入序列映射到的。
对于每一个注释hi,包含整个输入序列的信息,这个信息是强烈关注输入序列的第i个单词。
上下文向量ci,是带圈中的所有注释的和:
\[ c_{i}=\sum_{j=1}^{T_{x}} \alpha_{i j} h_{j} \]
权重 alpha是通过以下方式计算出来:
\[ \alpha_{i j}=\frac{\exp \left(e_{i j}\right)}{\sum_{k=1}^{T_{x}} \exp \left(e_{i k}\right)} \]
其中:
\[ e_{i j}=a\left(s_{i-1}, h_{j}\right) \]
e是一个校准模型,用来衡量输入中j位置附近的单词和输入位置i的匹配度。我们把a函数建模成一个前馈神经网络模型并同其他组成部分一起进行训练的。值得注意的是,不像传统的机器翻译那样,对齐部分不被考虑为一个隐藏变量。相反,对其模型直接计算软对齐(Soft Alignment),这样可以允许损失函数的梯度通过后馈网络训练。
ENCODER: BIDIRECTIONAL RNN FOR ANNOTATING SEQUENCES
在过去的RNN模型中,是从头到尾地读进去一个序列x的。但是在这个提出的方案中,我们想要注释(Annotation)总结不仅仅是前面的信息还有后面文字携带的信息。因此,我们使用了双向RNN结构,这种结构最近在语音识别上实现了重要效果。
BiRNN包括一个前向RNN和一个反向RNN,前向读取得到前向隐藏状态hForward(i),反向得到hBackward(i)。我们通过链接两个隐藏状态得到最终隐藏状态(也是注释)。这个注释序列会在后期被Decoder和对齐模型使用计算上下文向量。