1 前言
一直想沿着图像处理这条线建立一套完整的理论知识体系,同时积累实际应用经验。因此有了从使用AVFoundation捕捉图像,OpenCV识别图像,OpenGL渲染场景的学习计划,另外机器学习和深度学习在多媒体编码及图像处理中的应用也在计划之中。
在上写博客的目的有两个,其一是为了记录自己的学习历程,并把这作为自己的一个学习笔记,在需要的时候方便查阅。另外就是希望通过这种方式结识更多有着相同爱好的开发者,能够一起交流和讨论这个方向的知识。
该系列文章为OpenGL蓝宝书OpenGL SuperBible第6版英文版读书笔记,运行环境macOS 10.12.6,Xcode 9.0.1。在Mac上不能使用该书的最新版第7版,因为第7版的使用Open GL4.5,然而即使是最新的Macbook pro也不支持该版本。其实苹果已经使用Metal替代了OpenGL,并且将OpenGL相关的接口都标注为废弃,但是这并不表示学习OpenGL的知识是无用的。
关于资料,本系列文章全部都配有MacOS或者iOS环境中的Demo,并且每个例子都准备有Start和Final两个工程,后者是完整的示例程序,运行后可以得到和文章配图相同的效果。而Start结尾的工程是为了能够让看到篇文章,并相联系的小伙伴能够更容易的实现自己的程序,在该项目中移除了关键的代码,这样在练习时就可以不必花太多时间在无用的代码上,只需要补全关键的代码即可。
在Mac上,GPU定义了物理支持的OpenGL版本,Mac OS框架定义了支持的GL API版本。获取前者的信息除了之前提到的在苹果官网中查看,还可以使用AppStore中一个OpenGL Extension Viewer查看。后者信息在NSOpenGLContext中讲解。
另外,查询你的Mac能支持的OpenGL版本移步至Mac设备支持的OpenGL列表。查询你的GPU能够支持的特性请移步至苹果设备GPU型号及其在不同的环境下支持的OpenGL特性。我的Mac支持OpenGL4.1 Profile。因此选用OpenGL SuperBible 6th,但这个版本书使用的OpenGL版本是OpenGL4.3 Profile,因此书中部分功能无法使用。具体各版本OpenGL支持的功能特性移步至OpenGL历史版本。
2 简介
OpenGL是一个跨平台的图形编程接口,他可以在Linux、Windows、Mac OS、iOS、Android等各种平台上使用。
OpenGL的目标是在程序和底层图形处理子系统之间提供一个抽象的层,其中底层图形处理子系统通常由一个或者多个带有专用存储的高性能处理器组成。OpenGL需要平衡它的抽象程度,使它能够屏蔽不同硬件和系统带来的编程复杂性,同时兼顾能够充分使用硬件特性。游戏引擎的抽象程度通常很高,视频游戏机(video game consoles)的抽象程度通常非常低。
现代GPU展现出的强大计算能力使它不仅仅局限于图形处理,它还可以在物理模拟、人工智能甚至音频处理中得到充分利用。现代CPU由大量被称为着色器核心(shader core)的小型可编程处理器组成。每个核心都运行着迷你程序(shader),执行简单有限和单一的计算指令。
2.1 起源和发展
OpenGL起源于Silicon Graphics公司的IRIS图像实验室,最早是为其高端显卡服务的专有API,1992年时将其开源发布OpenGL 1.0版本。当年,OpenGL架构审核委员会(ARB)在其组织下成立,最初成员包括IBM, Intel, and Microsoft等公司。ARB负责设计管理和发布OpenGL描述和规范。现在该委员会是Khronos Group的一部分,OpenGL目前最新的版本是4.6。
2008年ARB将OpenGL分为两个部分,core profile和compatibility profile。core profile只保留现代GPU支持的较新部分接口。后者支持至OpenGL 1.0的接口。在开始新项目是应该使用前着,维护老项目时使用后者。值得注意的是,在部分平台上,更新的特性只支持在core profile中使用。另外使用前者编写的程序其运行速度也要高于后者。
2.2 竞争者
3D图形处理常用的两个编程语言是OpenGL ARB主导的OpenGL以及Microsoft主导的Direct3D。OpenGL更早发布,但是随后由于Direct3D支持可编程图形硬件特性,并且能及时支持新的GPU特性迅速抢占了OpenGL地位。在DirectX 10后其跟随最新的Windows系统绑定发布新版本,并且更新速度变慢,导致不能及时支持GPU生产商发布的新型GPU特性。OpenGL的ARB委员会加速其研发速度,现在它同样支持可编程图形硬件特性,并且较于Direct3D它及时支持新型GPU特性,ARB正在让它重新占领市场的领导地位。
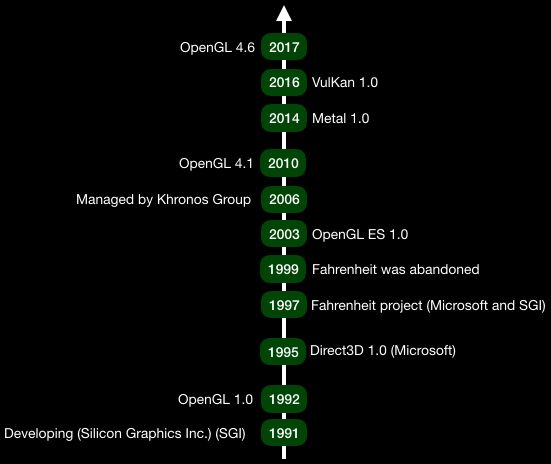
另外如前文说到,苹果于2014年发布了自己的图像渲染框架Metal,并且宣称和OpenGL相比,其具有更好的渲染性能。在2016年,负责维护OpenGL的ARB委员会发布了他们的新一代图像渲染框架VulKan,这被认为是OpenGL的接任者,该框架已经得到了来自工业局各个巨头的积极响应。ARB称VulKan具有比OpenGL更高的性能,这里也有着重新夺回游戏市场地位的意图。下图介绍了主要的图像渲染引擎开发历史。
2.3 图像管道
OpenGL的工作方式类似工厂中的流水线,OpenGL接受来自程序的命令,并将这些命令发送到底层的图形硬件。在图形硬件中,大量的指令排队并发运行,队列中某个指令前阶段可能后另一个指令的后阶段同时执行。进一步说,计算机图形通常由很多重复的任务块(如计算一个像素应该是什么颜色)组成,这些任务之间相互独立。OpenGL将程序发送给它的工作分解为很基础并且并行的任务块。现代的图形处理器通过极高的并发运算达到非常高的性能。
这种流水线的概念在OpenGL中被称为图像管道,图形处理可以分为几个阶段,每个阶段由一个着色器或者一个固定函数组成。下图描述了图像管道中的所有阶段。

图中蓝色的矩形表示可编程的阶段,我们可以通过编写OpenGL指定类型的着色器来自定义这些阶段的图像处理逻辑。绿色的矩形代表固定函数,即我们不能控制其内部实现,但是实际上一些固定函数仍然是用着色器语言实现的,只是它由GPU供应商提供预制的代码。
2.4 图元、管线和像素
当收到来自程序的命令时,数据从管道的一端流入,在流动的过程中,着色器程序(Shader)和固定函数会从缓存(Buffer)和纹理(Texture)中抓取更多的数据。某些阶段甚至存储数据到这些缓存和纹理内,最后在管道另一端返回处理完成的数据。
OpenGL中基本的渲染单元为图元(Primitive),OpenGL支持多种图元,他们由点、线和三角这三个基本图元组成。程序将复杂表面分解为大量三角形图元然后将其交付给GPU,GPU使用其内置的光栅器(Rasterizer)将其转化为一些列的像素点用于随后的渲染操作。
点、线和三角分别由一个、两个或多个顶点组成,顶点主要位于三维空间坐标系中。图形管道通常分为两部分,第一部分称为前端(Front End),它负责处理顶点和图元,最终将它们转化为点、线和三角,然后将其交付给光栅器,这一过程称为初始装配(Primitive Assembly)。经过光栅化器后,由向量构成的几何图形被转化为大量相互独立的像素点。从这里开始进入后端(Back End)的处理过程,其中包括深度(Depth)和模板(Stencil)测试、片段着色、颜色混合最终得到输出图像。
3 MacOS环境搭建
在Metal未发布之前,OpenGL在Apple眼中的地位正如Direct3D在Microsoft中一样,Apple为OpenGL的研发提供了很大的支持。但是由于Apple关注用户的体验,希望当前的应用能在Apple系列的所有设备中正常运行,因此Apple官方仅仅采用成熟的OpengGL版本,一些新的特性在Apple中以扩展的形式存在。
在Mac OS中,系统处理提供原生的OpenGL框架,还提供CGL、GLKit框架,以及在AppKit框架提供NSOpenGL相关的控件辅助我们开发程序。它们的功能描述见下表。除此之外我们还能使用一些第三方的框架,如GLUT等技术使用OpenGL。
| 名字 | 描述 |
|---|---|
| CGL | 最底层的OpenGL接口 |
| NSOpenGL | 基于OpenGL部分接口进行面向对象的封装 |
| GLKit | iOS中的一个OpenGL辅助开发工具库,其中部分功能在MacOS上也能使用 |
3.1 Core OpenGL
Core OpenGL是最底层的框架,它可以很好的和NSOpenGL中、GLUT或者其他更高级的第三方框架协同工作。另外CGL可以不使用NSOpenGL中视图部分直接创建全屏幕的context,但这在现代的OS X上已经不被鼓励使用。大多数Core OpenGL的方法都需要使用CGL context作为参数,获取当前的CGL context的方法是CGLGetCurrentContext(void)。
3.2 NSOpenGL
NSOpenGL主要包含视图(NSOpenGLView)和配置(NSOpenGLContext)两部分内容,其中后者主要用于配置OpenGL的版本信息等OpenGL方面的配置信息,以及一些视图中使用的渲染颜色空间等信息。
NSOpenGLView主要提供以下4个方法,各个方法的调用时间和必要的配置信息如下。示例使用Storyboard的方式创建NSOpenGLView,尽管UI界面上可以配置部分OpenGL Context的属性,但是由于某些配置仍无法完成。通常都需要使用代码配置,并且需要注意的是,代码中重新设置了上下文,这会使UI界面上的配置全部失效。通常需要在OpenGL Context中配置Color为32bit RGBA、Depth为24bit、Stencil为8bit、Renderer为Accelerated Renderer。更多配置和其具体意义参考头文件和Apple官网。
// Initialize OpenGL view and configure OpenGL Context. Several Contexts can be exist
// on application, but there are only one can be current context for a given thread.
// Moreover, OpenGL Context can share resouces so we can upload a texture or anything
// that needed for redering by a background context and then pass these resources to next context.
- (instancetype)initWithCoder:(NSCoder *)decoder {
// NSOpenGLProfileVersionLegacy is default
// NSOpenGLPFAColorSize must be always match the screen's color depth
// 对于BOOL的key,只需要在数组中包含这个key值就表示使用这个配置,对于有具体数值的key值,
// 其后需要紧跟一个数值,数组以0作为结束标志。
NSOpenGLPixelFormatAttribute pixelFormatAttributes[] = {
NSOpenGLPFAColorSize, 32,
NSOpenGLPFADepthSize, 24,
NSOpenGLPFAStencilSize, 8,
NSOpenGLPFAAccelerated,
NSOpenGLPFAOpenGLProfile, NSOpenGLProfileVersion4_1Core,
0
};
NSOpenGLPixelFormat *pixelFormat = [[NSOpenGLPixelFormat alloc] initWithAttributes:pixelFormatAttributes];
NSOpenGLContext *openGLContext = [[NSOpenGLContext alloc] initWithFormat:pixelFormat shareContext:nil];
if (self = [super initWithCoder:decoder]) {
[self setOpenGLContext:openGLContext];
[openGLContext makeCurrentContext];
}
return self;
}
// This method is called once time only after initialization
- (void)prepareOpenGL {
glClearColor(1.0f, 0.1f, 0.1f, 1.0f);
NSLog(@"Version: %s", glGetString(GL_VERSION));
NSLog(@"Renderer: %s", glGetString(GL_RENDERER));
NSLog(@"Vendor: %s", glGetString(GL_VENDOR));
NSLog(@"GLSL Version: %s", glGetString(GL_SHADING_LANGUAGE_VERSION));
}
// This method will call after "prepare" method when OpenGL view is created or each resization of the OpenGL view.
- (void)reshape {
NSRect bounds = [self bounds];
glViewport(0, 0, NSWidth(bounds), NSHeight(bounds));
}
// 这个方法执行具体的渲染逻辑
- (void)drawRect:(NSRect)dirtyRect {
glClear(GL_COLOR_BUFFER_BIT);
// “glFlush" is istead of some sort of buffer swap call. On Mac OS X, desktop compositing
// engine can be saw as front buffer, all OpenGL windows are really single buffered. Given
// OpenGL windows are always rendering to an off-screen buffer, when "glFlush" method is
// called, system will integrate the openGL rendering to the rest of teh desktop.
glFlush();
}
3.3 GLKit
GLKit是为了更好从OpenGL ES 1.x 的固定管道编程过渡到使用可编程管道的OpenGL ES 2.0设计的。最初只存在于iOS 5.0平台上,在OS X 10.8时引入Mac OS平台中。GLKit主要包含4个内容,纹理加载、数学库、特效和视图控制器。其中视图控制器部分只能在iOS平台中使用。特效部分主要是对部分固定函数管道(fixed-function pipeline)的进一步包装。但这对于我们深入理解OpenGL的实现原理有反面影响,因此不会介绍这个点。
OpenGL处理3D模型是靠向量和矩阵作为数学基础的,在OpenGL库中并不支持这些复杂的运算。于与其他平台需要额外的第三方数学库相比。Apple在GLKit中包含了数学库,数学库的主要目的是进行复杂的向量和矩阵运算,GLKMatrixLookAt甚至可以创建一个基于镜头的矩阵转换,GLKMatrixStack可以追踪矩阵变化的历史记录。简单的矩阵运算如下,复杂运算在以后示例中使用。
- (void)resizedWithWidth:(int)width height:(int)height {
glViewport(0, 0, width, height);
_mProgection = GLKMatrix4MakePerspective(GLKMathDegreesToRadians(60.0f), width/(float)height, 0.1f, 1000.0f);
GLKVector3 vLooking = GLKVector3Add(_cameraFrame.vWhere, _cameraFrame.vForward);
_mCamera = GLKMatrix4MakeLookAt(_cameraFrame.vWhere.x, _cameraFrame.vWhere.y, _cameraFrame.vWhere.z, vLooking.x, vLooking.y, vLooking.z, _cameraFrame.vUp.x, _cameraFrame.vUp.y, _cameraFrame.vUp.z);
GLKMatrix4 matrixMVP = GLKMatrix4Multiply(_mProgection, _mCamera);
GLKMatrix3 mNormal = GLKMatrix4GetMatrix3(_mCamera);
}
- (void)moveForwardWithDistance:(float)distance {
GLKVector3 vForward = GLKVector3MultiplyScalar(_cameraFrame.vForward, distance);
_cameraFrame.vWhere = GLKVector3Add(_cameraFrame.vWhere, vForward);
}
- (void)rotateLocalYWithAngle:(float)angle {
// 绕着镜头z轴向量创建一个旋转矩阵
GLKMatrix4 rot = GLKMatrix4MakeRotation(angle, _cameraFrame.vUp.x, _cameraFrame.vUp.y, _cameraFrame.vUp.z);
GLKVector3 vNewForward = GLKMatrix4MultiplyVector3(rot, _cameraFrame.vForward);
_cameraFrame.vForward = GLKVector3Normalize(vNewForward);
}
GLKit处理纹理主要有两个类。GLKTextureLoader负责加载2D或者3D纹理,并返回一个GLKTextureInfo的实例。另外GLKTextureLoader可以在子线程上使用Shared OpenGL Context异步加载纹理。GLKTextureInfo包含纹理大小,OpenGL Target Type等信息。
- (void)initModels {
NSString *path = [[NSBundle mainBundle] pathForResource:@"rock" ofType:@"png"];
NSError *error = nil;
_textureStones = [GLKTextureLoader textureWithContentsOfFile:path options:nil error:&error];
//convert png file to mipmaps
glBindTexture(GL_TEXTURE_2D, _textureStones.name);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR_MIPMAP_NEAREST);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
glGenerateMipmap(GL_TEXTURE_2D);
}
name:纹理的标识符,使用glBindTexture()将其绑定到context中。
target:纹理的类型,只支持GL_TEXTURE_2D和GL_TEXTURE_CUBEMAP。
width; height; depth:以像素为单位的纹理宽、高、深度。
alphaState:保存Alpha通道在颜色数据中的存储方式,可选None、NonPremultiplied、Premultiplied三个类型
textureOrigin:源图片的原点位置,可以是Unknown、TopLeft、BottomLeft,这个属性由GLKTextureLoader设置,代表纹理在加载时是否需要镜像处理
containsMipmaps:Bool值,标识是否包含率纹理(Mipmaps)
mimapLevelCount:率纹理(Mipmaps)的等级数量
arrayLength:数组长度
3.4 Retina屏适配
在Mac Retina屏系列出现以后,对于Cocoa中视图的尺寸都是以point为单位,而OpenGL函数中图像及纹理的尺寸都是以pixel为单位。在非Retina屏幕中它们具有相同的值,但是在Retina屏幕中,它们具有不同的值。Mac OS对于OpenGL默认的渲染规则是1个点渲染1个像素,启用Retina特性的代码级两个单位之间的转换代码如下。
- (instancetype)initWithCoder:(NSCoder *)decoder {
if (self = [super initWithCoder:decoder]) {
// 启用全像素渲染
[self setWantsBestResolutionOpenGLSurface:YES];
}
return self;
}
- (void)reshape {
NSRect bounds = [self bounds];
// 将点数转化为像素
NSRect backRect = [self convertRectToBacking:bounds];
glViewport(0, 0, NSWidth(bounds), NSHeight(backRect));
}
3.5 窗口化程序
后面的例子都会基于活动窗口创建OpenGL程序,此时我们会使用窗口系统提供的默认缓存接受处理后的数据。在MacOS中存在一个桌面缓存合成引擎,系统屏幕包含一个大的帧缓存对象,桌面合成引擎会在合适的时机将系统各个可见窗口的帧缓存数据合成到屏幕帧缓存至少,最后将合成后的帧缓存渲染到屏幕上。桌面合成引擎只有收到缓存交换信号时才会处理窗口的帧缓存,发出缓存交换信号需要调用函数glFlush()。下图简单表示了窗口缓存和屏幕缓存的关系。

3.6 全屏渲染
很多OpenGL程序需要进行全屏渲染,而不是在一个活动窗口中。实现这个目标有两种方式,1)创建一个和整个屏幕一样大的窗口,在OS X10.6之前,这并不是最优的方式。2)使用CGL捕捉屏幕得到更好的全屏渲染效果。在OS X10.6之后,苹果不建议捕捉屏幕,当渲染到全屏幕窗口时,将会得到一个Context标记,OS X会屏幕捕捉方式使用的技术自动优化图像渲染。另外还可以使用双渲染缓存的方式即先将图像渲染至一个更小的缓存中来提升填充性能。捕捉屏幕还会导致UI信息无法在全屏时弹出(如系统提示电量不足信息)。
使用上述第一个方式实现全屏渲染时,在NSOpenGLView的子类中的渲染逻辑时,不再使用glFlush(),取代它的是方法[[self openGLContext] flushBuffer]。
- (void)drawRect:(NSRect)dirtyRect {
[super drawRect:dirtyRect];
[[self openGLContext] flushBuffer];
}
程序加载完成后手动实例化NSOpenGLView的方法如下。
- (void)applicationDidFinishLaunching:(NSNotification *)aNotification {
NSRect mainDisplayRect = [[NSScreen mainScreen] frame];
NSWindow *fullScreenWindow = [[NSWindow alloc] initWithContentRect:mainDisplayRect
styleMask:NSWindowStyleMaskBorderless backing:NSBackingStoreBuffered defer:YES];
[fullScreenWindow setLevel:NSMainMenuWindowLevel+1];
[fullScreenWindow setOpaque:YES];
[fullScreenWindow setHidesOnDeactivate:YES];
NSOpenGLPixelFormatAttribute pixelFormatAttributes[] = {
NSOpenGLPFAColorSize, 32,
NSOpenGLPFADepthSize, 24,
NSOpenGLPFAStencilSize, 8,
NSOpenGLPFAAccelerated,
NSOpenGLPFADoubleBuffer,
NSOpenGLPFAOpenGLProfile, NSOpenGLProfileVersion4_1Core, 0
};
NSOpenGLPixelFormat* pixelFormat = [[NSOpenGLPixelFormat alloc] initWithAttributes:pixelFormatAttributes];
NSRect viewRect = NSMakeRect(0.0, 0.0, mainDisplayRect.size.width, mainDisplayRect.size.height);
GLCoreProfileView *fullScreenView = [[GLCoreProfileView alloc] initWithFrame:viewRect pixelFormat:pixelFormat];
[fullScreenWindow setContentView: fullScreenView];
[fullScreenWindow makeKeyAndOrderFront:self];
[fullScreenWindow makeFirstResponder:fullScreenView];
}
3.7 帧率同步
Macbook Pro渲染图像是从上至下逐行刷新,当渲染的帧率和屏幕刷新帧率不一致时,可能导致屏幕刷新到一半时,渲染新的图像,从而导致屏幕上下显示了两帧不同的图像。Macbook Pro的屏幕刷新率为60FPS,我们不能直接设置渲染帧率,但是可以通过设置每帧渲染之前的屏幕刷新率次数kCGLCPSwapInterval来控制渲染帧率。他可以消除图像撕裂现象。可以这样理解,当该值为2时,图像渲染帧率最大为30FPS,当一个渲染操作完成后,负责渲染的线程将会等待两次屏幕刷新时间后继续执行渲染操作。此时后台线程可以完成其他更重要的处理任务。在任何时候都可以调用改变渲染帧率的方法,它会立即生效。需要注意的是,这个并不能保证渲染率一定为30FPS,因为如果单个渲染逻辑超时,会发生丢帧现象。
GLint sync = 1;
CGLSetParameter(CGLGetCurrentContext(), KCGLCPSwapInterval, &sync);
3.8 提升填充效率
填充效率指的是将图像数据转换为帧缓存像素信息的速率。一个简单的办法就是使用更小的窗口,在全屏模式下降低屏幕分辨率。在OS X10.6之前,对于一个全屏幕OpenGL游戏,在运行游戏、捕捉屏幕等操作之前改变屏幕分辨率并不常见。捕捉屏幕并改变屏幕分辨率方法暂不深入研究。在使用双缓存的前提下,我们可以用CGL去改变协调图像缓存的尺寸,使其小于前台图像缓存来提升填充效率。当渲染到屏幕时,协调图像缓存的内容会拉伸填充到整个前台图像缓存。
在改变协调图像缓存尺寸时,必须重新设置glViewport。
- (void) reshape {
GLint dim[2] = {newWidth, newHeight};
CGLSetParameter(CGLGetCurrentContext(), kCGLCPSurfaceBackingSize, dim);
CGLEnable(CGLGetCurrentContext(), kCGLCESurfaceBackingSize);
glViewport(0, 0, newWidth, newHeight);
}
3.9 OpenGL多线程操作
OpenGL驱动会先通过CPU处理一部分计算,然后最终将其交付到GPU渲染。在OS X 10.5以后,可以启用多线程OpenGL核心将这些任务交给多个线程处理。在多核CPU设备上,这样能再一定程度上提升性能。但其提升效果有限,甚至有时会降低性能。当有关OpenGL执行的代码的执行性能不受限于CPU时,通常不会有明显的性能提升。另外,调用大量的生成渲染管道函数(glGetFloatv(), glGetIntegerv(), glReadPixels()等)也会影响其性能提升潜力。
CGLEnable(CGLGetCurrentContext(), kCGLCEMPEngine);
3.10 GLUT
GLUT的全称为OpenGL Utility Toolkit,一个基于窗口系统的OpenGL编程工具。最早于1994年发布,初期定位为说明和学习框架,随后不断扩展,支持基本的游戏编程特性。尽管现在不是主流的工具,但是Apple针对OS X进行了部分优化。
创建基于GLUT的程序需要移除空白项目中的AppDelegate.m/.h和main.m文件,并创建包含GLUT的C/C++文件。
int main(int argc, char* argv[]) {
glutInit(&argc, argv);
glutInitDisplayMode(GLUT_DOUBLE | GLUT_RGBA | GLUT_DEPTH | GLUT_STENCIL | GLUT_3_2_CORE_PROFILE);
glutCreateWindow("GLUT Core Profile Demo");
glutReshapeFunc(ChangeSize);
glutKeyboardFunc(KeyPressFunc);
glutDisplayFunc(RenderScene);
SetupRC();
printf("Version: %s\r\n", glGetString(GL_VERSION));
printf("Renderer: %s\r\n", glGetString(GL_RENDERER));
printf("Vendor: %s\r\n", glGetString(GL_VENDOR));
printf("GLSL Version: %s\r\n",
glGetString(GL_SHADING_LANGUAGE_VERSION));
glutMainLoop();
return 0;
}
3.11 渲染一个三角形
这里通过一个简单的例子来了解最基本的OpenGL程序组成,以及着色器语言编写方法。首先在Xocde中新建一个mac OS目录下的Cocoa App程序,在主窗口中添加NSOpenGLView的子类GLCoreProfileView,如前文描述。这里使用Shader.vsh和Shader.fsh文件分别用于编写顶点着色器和片段着色器。并且在工程中导入OpenGL和GLKit框架。完成后的文件目录如下所示。Demo传送门

一个基本的OpenGL程序包含以下几个步骤。
- 1-配置GLContext,这里配置为Apple支持的最新4.1 Profile,具体方法见前文。
- 2-准备着色器字符串,这里使用创建空白文件方式,其内容见下面代码。
- 3-创建、编译着色器。
- 4-创建、链接OpenGL程序(program)。
- 5-创建顶点数组对象(VAO),并将数据关联至着色器,这里只创建,关联在后面章节讲解。
- 6-渲染图形。
准备顶点着色器
// 指定了OpenGL版本为 4.1 Core Profile
#version 410 core
void main() {
// 通常顶点数据是通过外部传入,这里简单示例采用另外一种方式gl_VertexID,它检查外面调用的方法glDrawArrays(GL_TRIANGLES, 0, 3);
// 从第一个参数开始取顶点,直到最后一个参数定义的顶点数量。
// The gl_VertexID input starts counting from the value given by the first parameter of glDrawArrays()
// and counts upwards one vertex at a time for count vertices (the third parameter of glDrawArrays())
const vec4 vertices[3] = vec4[3](vec4( 0.25, -0.25, 0.5, 1.0),
vec4(-0.25, -0.25, 0.5, 1.0),
vec4( 0.25, 0.25, 0.5, 1.0));
// gl_Position为GLSL中的内部的输出变量,这个输出变量OpenGL内部会用于拓扑重建等任务(Tessellation)。
gl_Position = vertices[gl_VertexID];
}
准备片段着色器
#version 410 core
// Out表示输出变量,这个输出变量会被OpenGL捕捉,并用于图形的渲染
out vec4 FragColor;
void main() {
FragColor = vec4(0.0, 0.8, 1.0, 1.0);
}
创建和编译着色器、链接程序、创建VAO
- (void)prepareOpenGL {
[self loadShaders];
glGenVertexArrays(1, &_vertexArray);
glBindVertexArray(_vertexArray);
}
- (BOOL)loadShaders {
GLuint vertexShader;
GLuint fragShader;
NSString *vertexShaderPathName;
NSString *fragShaderPathName;
_program = glCreateProgram();
vertexShaderPathName = [[NSBundle mainBundle] pathForResource:@"Shader" ofType:@"vsh"];
if (![self compileShader:&vertexShader type:GL_VERTEX_SHADER filePath:vertexShaderPathName]) {
NSLog(@"Failed to compile vertex shader");
}
fragShaderPathName = [[NSBundle mainBundle] pathForResource:@"Shader" ofType:@"fsh"];
if (![self compileShader:&fragShader type:GL_FRAGMENT_SHADER filePath:fragShaderPathName]) {
NSLog(@"Failed to compile fragment shader");
}
glAttachShader(_program, vertexShader);
glAttachShader(_program, fragShader);
if (![self linkProgram:_program]) {
NSLog(@"Failed to link program: %d", _program);
if (vertexShader != 0) {
glDeleteShader(vertexShader);
vertexShader = 0;
}
if (fragShader != 0) {
glDeleteShader(fragShader);
fragShader = 0;
}
if (_program != 0) {
glDeleteProgram(_program);
_program = 0;
}
return NO;
}
if (vertexShader != 0) {
glDetachShader(_program, vertexShader);
glDeleteShader(vertexShader);
}
if (fragShader != 0) {
glDetachShader(_program, fragShader);
glDeleteShader(fragShader);
}
return YES;
}
- (BOOL)compileShader:(GLuint *)shader type:(GLenum)type filePath:(NSString *)path {
const GLchar *shaderSource = [NSString stringWithContentsOfFile:path encoding:NSUTF8StringEncoding error:nil].UTF8String;
*shader = glCreateShader(type);
glShaderSource(*shader, 1, &shaderSource, nil);
glCompileShader(*shader);
GLint status = 0;
glGetShaderiv(*shader, GL_COMPILE_STATUS, &status);
if (status == 0) {
GLint logLen = 0;
glGetShaderiv(*shader, GL_INFO_LOG_LENGTH, &logLen);
GLchar *infoLog = malloc(sizeof(char) * logLen);
glGetShaderInfoLog(*shader, logLen, NULL, infoLog);
NSLog(@"Shader at: %@", path);
fprintf(stderr, "Info Log: %s\n", infoLog);
glDeleteShader(*shader);
return NO;
}
return YES;
}
- (BOOL)linkProgram:(GLuint)program {
glLinkProgram(program);
GLint status = 0;
glGetProgramiv(program, GL_LINK_STATUS, &status);
if (status == 0) {
GLint logLen = 0;
glGetProgramiv(program, GL_INFO_LOG_LENGTH, &logLen);
GLchar *infoLog = malloc(sizeof(char) * logLen);
glGetProgramInfoLog(program, logLen, NULL, infoLog);
fprintf(stderr, "Prog Info Log: %s\n", infoLog);
return NO;
}
return YES;
}
渲染图形
- (void)drawRect:(NSRect)dirtyRect {
const GLfloat color[] = { (float)sin(_lifeDuration) * 0.5f + 0.5f, (float)cos(_lifeDuration) * 0.5f + 0.5f,
0.0f, 1.0f };
glClearBufferfv(GL_COLOR, 0, color);
// 当glDrawArrays画顶点时可以指定点的大小
// glPointSize(40);
glUseProgram(_program);
glDrawArrays(GL_TRIANGLES, 0, 3);
glFlush();
}
4 管线(Pipeline)
在OpenGL中VertexShader是第一个可编程的步骤,但是它并不是管线的第一个步骤,管线的第一个步骤是顶点抓取(vertex fetching),这是一个固定函数,系统负责调用并给顶点着色器提供输入数据。
4.1 向顶点抓取模块传入数据
在着色器中GLSL提供了in关键字用于定义输入属性,对于顶点着色器,顶点抓取模块(vertex fetching stage)负责为这些输入变量提供数据。顶点抓取模块是一个固定函数,可以使用类似于glVertexAttrib*()的函数来告诉它执行某些特定的操作。Demo传送门
在着色器中定义输入变量
#version 410 core
// layout关键字和location关键字指定了该输入的索引值为0,后面使用glVertexAttrib4fv函数时使用相同的值就能完成数据通信
layout (location = 0) in vec4 offset;
void main() {
const vec4 vertices[3] = vec4[3](vec4( 0.25, -0.25, 0.5, 1.0),
vec4(-0.25, -0.25, 0.5, 1.0),
vec4( 0.25, 0.25, 0.5, 1.0));
gl_Position = vertices[gl_VertexID] + offset;
}
和顶点抓取模块数据通信
- (void)drawRect:(NSRect)dirtyRect {
const GLfloat color[] = { (float)sin(_lifeDuration) * 0.5f + 0.5f, (float)cos(_lifeDuration) * 0.5f + 0.5f,
0.0f, 1.0f };
glClearBufferfv(GL_COLOR, 0, color);
glUseProgram(_program);
GLfloat attrib[] = { (float)sin(_lifeDuration) * 0.5f, (float)cos(_lifeDuration) * 0.6f,
0.0f, 0.0f };
// Update the value of input attribute 0
glVertexAttrib4fv(0, attrib);
glDrawArrays(GL_TRIANGLES, 0, 3);
glFlush();
}
4.2 不同模块间数据通信
正如定义了in关键字,GLSL还定义了out关键字用于输出变量,任意一个用out关键字定义在某个模块中的变量,在其下一个模块都能使用同样的标识符通过in关键字获取。在该示例中变量直接被顶点着色模块传递到片段着色模块是由于中间模块并未被激活。Demo传送门
4.2.1 传递简单数据
顶点着色器接受变量color,输出变量vsColor
#version 410 core
layout (location = 0) in vec4 offset;
layout (location = 1) in vec4 color;
out vec4 vsColor;
void main() {
gl_Position = ...;
vsColor = color;
}
片段着色器接受变量vsColor
#version 410 core
in vec4 vsColor;
out vec4 FragColor;
void main() {
FragColor = vsColor;
}
渲染时向顶点着色器传入变量
- (void)drawRect:(NSRect)dirtyRect {
...
glVertexAttrib4fv(0, attrib);
GLfloat fragColor[] = {1.0f, 0.0f, 0.0f, 1.0f};
glVertexAttrib4fv(1, fragColor);
...
}
4.2.2 传递复杂数据结构
GLSL允许在shader之间以结构体的方式传递数据。这样有两个好处,第一:允许输出变量和输入变量名称不同,只需要他们结构的定义相同。第二:允许用同一个变量传递多个数据。但是需要注意的是这种方式不允许在向vertexshader的输入和fragment的输出中使用。Demo传送门
顶点着色器
#version 410 core
layout (location = 0) in vec4 offset;
layout (location = 1) in vec4 color;
out VS_OUT {
vec4 color;
} vs_out;
void main() {
gl_Position = ...;
vs_out.color = color;
}
片段着色器
#version 410 core
in VS_OUT {
vec4 color;
} fs_in;
out vec4 color;
void main() {
color = fs_in.color;
}
4.3 曲面细分(Tessellation)
曲面细分指的是将大的多边形分为大量的较小的点、线和三角,使这些小图元能直接被光栅化器使用。在逻辑上,曲面细分阶段紧紧跟着ShaderVertex模块,拓扑重建由一个可编程曲面细分控制模块(tessellation control shader)、一个固定函数曲面细分引擎(tessellation engine)和曲面细分评价器组成(tessellation evaluation shader)。
4.3.1 曲面细分控制模块(tessellation control shader)
曲面细分将图形补丁组(patches)分解为大量的较小的点、线和三角(此例只包含一个补丁,由三个控制点组成的三角形)。可以通过glPatchParameteri()设置每个补丁(patch)的控制点个数(pname = GL_PATCH_VERTICES)。不调用此函数时,默认设置为3。当启用曲面细分时,OpenGL会为每个控制点调用一次vertex shader,同时曲面细分控制程序将控制点分组进行批量处理,其每批处理的控制点大小和每个补丁(patch)的控制点数量相同(每处理一个patch后该着色器代码才会执行)。控制模组生成的每批的控制点可以改变,从而使得模组的消耗顶点数量不同于输出顶点数量。
该模块主要负责两件事情:
1:确定曲面细分引擎需要的拓扑重建级别。
2:生成曲面细分评价器需要的数据,即将原始补丁控制点做自定义修改后传入评价器程序。
在编写曲面细分控制模组时,对于数据的传递有如下内建变量。
layout (vertices = 3) out;vertices定义了控制模组每批处理输出的控制点个数。
gl_InvocationID;控制模组内部用的数组索引,其范围和输入控制点个数相关。
gl_TessLevelInner;输出的图元内部曲面细分因子数组(可以只设置首个)。
gl_TessLevelOuter;输出的图元边界曲面细分因子数组(容量和输出控制点个数相同,需要全部赋值)。
gl_out、gl_in:输出和输入的控制点数组。
#version 410 core
layout (vertices = 3) out;
void main(void) {
if (gl_InvocationID == 0) {
gl_TessLevelInner[0] = 5.0;
gl_TessLevelOuter[0] = 5.0;
gl_TessLevelOuter[1] = 5.0;
gl_TessLevelOuter[2] = 5.0;
}
gl_out[gl_InvocationID].gl_Position = gl_in[gl_InvocationID].gl_Position+vec4(0.25,0,0,0.0);
}
4.3.2 曲面细分引擎(The Tessellation Engine)
曲面细分引擎是一个固定函数,它根据前一个模组传入的细分因子将图形补丁组(patches)细分为大量点、线和三角。当细分引擎将图形补丁组分解后,代表基础图元的顶点数组被曲面细分评估函数获取。细分引擎负责为评估函数生成参数,用于转换图元和为光栅化做准备。
4.3.3 曲面细分评估函数(Tessellation Evaluation Shaders)
当前一个模组将图形补丁组(patches)细分为大量点、线和三角,生成大量顶点后。OpenGL会为每一个顶点调用一次评估函数。曲面细分等级越高时,曲面评估函数耗时越长。需要注意这点,并且避免复杂的评估函数。评估函数接受来自控制函数的输出控制点(gl_in),并以此为基础建立重心坐标系(barycentric coordinate system),同时接收细分引擎传入顶点的重心坐标(gl_TessCoord.x)。通过设置细分模型、多边形细分规则、细分图元计算方向来计算出每个顶点的坐标。
#version 410 core
layout (triangles, equal_spacing, cw) in;
void main(void) {
gl_Position = (gl_TessCoord.x * gl_in[0].gl_Position + gl_TessCoord.y * gl_in[1].gl_Position + gl_TessCoord.z * gl_in[2].gl_Position);
}
为了观察具体效果,在渲染时调用glPolygonMode()函数控制渲染模式,此例中使用GL_FRONT_AND_BACK作为其参数face表示除了视角能看见的面,视角不可见的面也需要绘制,使用GL_LINE作为mode参数表示只绘制轮廓。另外绘制函数也需要改为GL_PATCHES而不再绘制三角。
void glPolygonMode(GLenum face, GLenum mode);
glDrawArrays(GL_PATCHES, 0, 3);
当启用上述两个着色器,再修改本次示例中上文的顶点着色器和片段着色器后得到下图结果。Demo传送门

4.4 几何着色器阶段(Geometry Shaders)
几何着色器模组理论上是管道前端的最后一个模组,位于曲面细分模组和光栅化模组之间。每处理一个图元,几何着色器将会被调用一次,并接收组成该图元的所有顶点数据。在众多模组间,其具有独特的性质。一:它可以通过两个函数(EmitVertex() and EndPrimitive())来直接改变在管道中流动的数据量()。二:它可以改变图元的类型,如将三角分解为顶点输出,或者将顶点组合为三角输出。
#version 410 core
layout (triangles) in;
layout (points, max_vertices = 3) out;
void main(void) {
int I;
for (i = 0; i < gl_in.length(); i++) {
gl_Position = gl_in[i].gl_Position;
EmitVertex();
}
}
上面代码将triangles作为几何着色器的输入图元类型,输出点图元类型,每个shader最多输出3个顶点。在为每个顶点计算出输出位置后,调用EmitVertex()生成一个顶点。在着色器的末尾,OpenGL会自动调用EndPrimitive()函数将当前缓存中的图元形成points定义的图元并将其输出,随后清空画布。
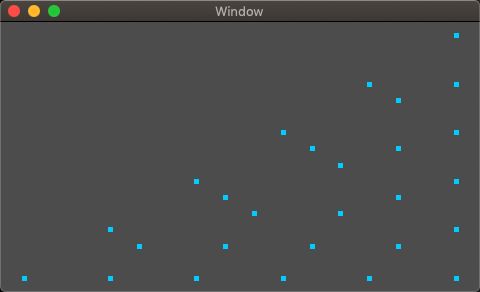
在前文示例的基础上启用本小节中的几何着色器,并将每个点的大小通过调用glPointSize()函数设置为5个像素后得到下图所示结果。Demo传送门
4.5 图元的装配,剪切和光栅化
当管道前端(vertex shading, tessellation, and geometry shading)运行完成后,一个固定函数执行了一系列的任务将顶点转化为像素。在这一系列复杂的任务之中,第一步为图元装配(primitive assembly),它将顶点分为线、三角和点图元。随后OpenGL将会对其不可见部分进行剪切(由视图窗口控制viewport)。最后可见图元被发送到光栅化器(rasterizer)。光栅化器将图元分解为像素,并将这些像素点发送给片段着色器进行进一步处理。
4.5.1 剪切(Clipping)
在OpenGL中点的位置信息,正如在各个shader中使用的glPosition变量都是由4个坐标组成的,它们被称为齐次坐标(homogeneous coordinate)。在投影几何中使用齐次坐标空间表示点比使用常规的笛卡尔空间更简单(Cartesian space)。在将顶点从齐次坐标系转化为笛卡尔坐标系的过程中,OPenGL执行了透视除法(perspective division),即将前三个元素(x.y.z)都除以第4个元素(w)。
经过投影除法后,所有点都位于常规设备空间内(normalized device space)。在OpenGL内可见的常规设备空间在x、y轴上的范围是(-1.0至1.0),在z轴上的范围是(0.0至1.0)。在这个范围内的图元部分都是可见的,在这个范围外的部分都将会被丢弃。对于每一个图元,如果图元的所有顶点都在可视范围内,这个图元将直接输出到光栅化器;如果图元的所有顶点全部在可视范围内,整个图元将会被丢弃;如果图元部分顶点在可视范围内,将会执行额外操作,将在下文讲到剪切章节时解释。
4.5.2 视口变换(Viewport Transformation)
经过剪切后,所有的顶点都位于常规设备空间内(normalized device space)。但是我们在屏幕上显示的窗口坐标空间,其距离单位为像素,范围从左下的(0,0)直至右上角的(w-1,h-1)。OpenGL执行视口变换操作,通过平移和和缩放的操作将顶点从常规设备空间转换到窗口坐标空间(window coordinates)。窗口坐标空间通过调用glViewport()和glDepthRange()函数设置。

公式中xw,yw,zw为转后顶点的坐标,px,py为视口的宽和高,ox,oy为视口的原点,xd,yd,zd为转换前位于标准设备空间内的坐标。
4.5.3 面剔除(Culling)
在三角形真正被处理之前,可能会经过一个精选阶段。该阶段计算确定了三角形是面向观察者还是背向观察者,同时确定三角形是否会被管道中下一个阶段的程序处理。OpenGL通过front-facing和back-facing来表示三角形的朝向,通常,背向观察者的三角形都会被丢弃,因为对于封闭的图形,这些表面都将被隐藏。但是绘制透视图形的时候这些表面不能被丢弃。
在决定三维空间中的一个三角形在z轴上是背向观察者或者是面向观察者时,OpenGL采用计算其在xy投影三角有向面积的方式。一种计算有向面积的方式是计算任意两条边的交叉相乘差的和(take the cross product of two of its edges)。公式如下。
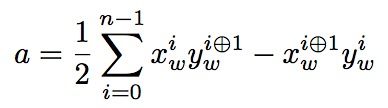
其中xiw和ywi 分别是第i个顶点的窗口坐标,i⊙1是(i+1)对3求余。如果结果是正数,这个三角形图元被认为是面向观察者的,如果是负数则是背向观察者了,只有当三个顶点在同一直线上时,该值为0。另外可以通过调用glFrontFace()函数取得相反结果,其默认设置是GL_CCW(三角形顶点出现顺序为逆时针的三角形图元被认为是面向观察者图元By default, this state is set to GL_CCW, indicating that triangles whose vertices are in counterclockwise order are considered to be front-facing),当设置为GL_CW表示三角形顶点出现顺序为正时针,此时OpenGL会默认为每个有向面积取负数。

另外一种计算三角形有向面积的方式是通过行列式的方式计算。其中x0,y0,x1,y1,x2,y2分别代表顶点V0,V1,V2。A表示三角形的有向面积。

在计算出三角形的朝向状态后,程序中通过glEnable(GL_CULL_FACE)函数启用精选模组,默认会剔除背向观察者的三角形图元(back-facing)(When you enable culling, OpenGL will cull back-facing triangles by default)。可以通过函数glCullFace() 和参数GL_FRONT, GL_BACK, GL_FRONT_AND_BACK设置需要剔除的三角形种类。
点图元和线图元没有几何面积,因此精选阶段将会忽略这些图元。并且该阶段三角形图元的顶点顺序和vertexshader中顶点输入顺序一级tesselation evaluation shader中的顶点输入顺序相关,此实例vshader输入顺序为cw,teshader输入顺序为cw,但是在计算culling阶段时默认过滤后向图元,在使用默认计算朝向参数设置时,即会剔除掉cw顶点顺序的三角形图元。可见从teshader到culling阶段OpenGL内部进行了某些转换,使得三角形顶点顺序反向。
4.5.4 光栅化(Rasterization)
光栅化模组会计算哪些片段在线或者三角图元内。大多数OpenGL系统在光栅化三角形时采用半空间(half-space-based)计算方法一遍能够并行处理大量计算任务。具体的计算方式是,OpenGL会为窗口坐标系中的三角形图元限定一个边界框,将在框里的每一个像素分别和三角形的三条边比较,向量的叉乘(点向量分别和三条连续相连边向量叉乘)和向量点乘(上一步三个向量分别两两点乘)确定点是否在三条边的同一侧。这种方式使得每个像素的计算都相对独立,它只考虑三角形某一边的两个端点和片段自己的位置,使得大规模并行计算得以进行。只有同时在三条边内的片段才会被传递到片段的下一个模组。下图简单的演示了光栅化过程,其中绿色的片段表示经过光栅化处理的到的片段。

4.6 片段着色器(Fragment Shaders)
片段着色器是图形管道的最后一个可编程模组,它计算出每个片段的颜色并将其输入到帧缓存中。这里是图形管道中计算量最大的一个模组。光栅化过程可能会为每个图元生成甚至上百万个片段。前文示例中的片段着色器代码非常简单,通常这里的逻辑会更复杂,它需要执行与光照(lighting)、纹理贴图(applying materials)和片段深度(depth of the fragment)相关的计算逻辑。gl_FragCoord是一个重要的输入内部变量,它包括了片段在窗口中的坐标。片段着色器同样可以接受来自前一个着色器传入的变量,但是这里的输入变量不同于管道中其他模组接收的输入变量,该阶段的输入变量会在图元的不同片段之间发生变化。
这里启用只启用顶点着色器和片段着色器。它们的代码分别如下。
顶点着色器
#version 410 core
out vec4 vs_color;
void main(void) {
const vec4 vertices[3] = vec4[3](vec4( 0.25, -0.25, 0.5, 1.0),
vec4(-0.25, -0.25, 0.5, 1.0),
vec4( 0.25, 0.25, 0.5, 1.0));
const vec4 colors[] = vec4[3](vec4( 1.0, 0.0, 0.0, 1.0),
vec4( 0.0, 1.0, 0.0, 1.0),
vec4( 0.0, 0.0, 1.0, 1.0));
gl_Position = vertices[gl_VertexID];
vs_color = colors[gl_VertexID];
}
片段着色器
#version 410 core
in vec4 vs_color;
out vec4 color;
void main(void) {
color = vs_color;
}
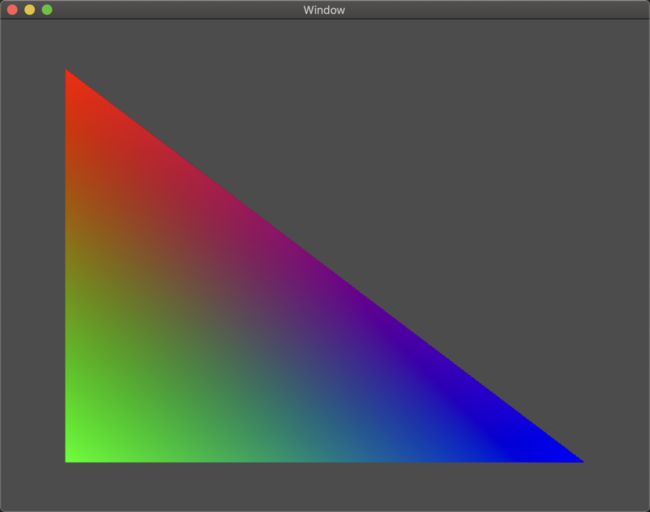
当使用上述代码替换前文中的片段着色器后得到下图结果。可以看见顶点着色器只为其每个顶点指定了固定的颜色,但是OpenGL内部会根据片段距离三个顶点的距离计算出该片段的真实颜色值。Demo传送门
4.7 帧缓存操作(Framebuffer Operations)
帧缓存阶段是管道的最后一个阶段,它负责计算屏幕上可见内容,并且管理一块内存区域用于存储每个像素点的数据。在大多数平台上,帧缓存和操作系统(更准确的将是窗口系统)管理的当前窗口(当前窗口占满整个屏幕时即指代整个屏幕)相关联。窗口系统提供了默认帧缓存,当需要进行离屏渲染时也可以提供指定的帧缓存。帧缓存会保存多个状态,例如确定片段着色器产生的数据应该写入的位置,以及数据的格式等。这些状态保存在一个帧缓存对象(Framebuffer Object)中。
4.7.1 像素操作(Pixel Operations)
在片段着色器输出像素数据和将其渲染到屏幕上之间还要经过几个操作来确定其是否应该被放入窗口中,其中每个操作都可以在程序中开启或禁用。
第一个操作是剪切测试(scissor Test),它负责测试片段是否位于程序定义的矩形框内,矩形框内的片段输出到下一个任务,矩形框外的片段将会被丢弃。
接下来是模板测试(Stencil Test),它负责比较程序提供的参考值和模板缓存中对应的值。模板缓存为每个片段存储一个值。这些值没有任何特定的语义,它能被用于任何目的。模版缓存测试通过和失败的条件,以及模版缓存内部的值更新逻辑可以通过调用OpenGL的接口控制。
接下来是深度测试(Depth Test),比较片段的z轴坐标分量和深度缓存中的对应的值,和模版缓存意义,深度缓存也会为每个片段保存一个值。深度缓存是帧缓存的另一部分,它包含了每个像素的景深(像素和观察者的距离)信息。通常景深缓存中存储的数据取值范围有近到远为0~1。
在对窗口中同一个坐标点进行多次渲染时,OpenGL会比较当前待处理片段的z轴坐标分量,和已深度缓存中对应的景深数据。如果当前片段的对应景深数据更小,当前片段就会替代原有片段。这个测试的逻辑可以调用OpenGL的函数设置。另外景深测试的结果同样也会影响OpenGL对模板测试的处理结果。
接下来根据片段的颜色值的格式(浮点型,标准化整形,或者整型),将它们向后传递到混合和逻辑操作模组(Blending or Logical Operation Stage)。如果是小数或者标准化整型数据,混合模组将会被启用。OpenGL提供大量的函数用于计算片段着色器输出的结果和当前颜色缓存中值混合值,计算出的混合值将会被写入到帧缓存中。如果帧缓存包含的是整型数据,OpenGL将会对片段着色器的输出值和当前帧缓存中对应值执行AND、OR、XOR等逻辑操作,并将计算出新的值写入到帧缓存中。
4.8 计算着色器(Compute Shaders)
前文分析了OpenGL图形管道的各个阶段,但是OpenGL中还独立于图形管道之外运行着计算着色器。它可以被认为是独立于图像管道外的单模组管道。
每次计算着色器的调用都被在单个工作单元中处理,这个工作单元被称为工作块(work item),多个工作块形成一个工作组(local workgroups)。这OpenGL的计算管道就依赖于这些工作组运行。除了一些表明当前计算着色器允许工作组大小的内部变量,计算着色器不含任何固定的输出或者输入变量,其所有的计算结果都将写入内存中。
#version 410 core
layout (local_size_x = 32, local_size_y = 32) in;
void main(void) {
// Do nothing
}
计算着色器的编译链接方法和顶点着色器的编译链接方法相同。上述代码定义了一个简单的计算着色器,其中规定了单个工作组的容量是32*32个工作块。
5 总结
在这个短文中,我们主要聊到了两个关键点,(1)OpenGL的图像管道,和(2)MacOS开发环境搭建。