背景#
Apache Spark已逐渐成为下一代大数据处理工具的典范,它利用内存来处理数据,因而其处理速度远超Hadoop的MapReduce。
江湖传言,大数据工程师钱途无量,不少java开发工程师将目光投向了大数据开发工程师,有意转型成为“玩数据”的人,在未来从事海量数据的处理、分析、统计、挖掘等相关工作。
spark方向大数据开发工程师入门的第一步是搭建开发环境,本文讲述64位win7操作系统下基于eclipse的spark开发环境搭建。
步骤概览#
- jdk1.8下载和安装
- eclipse4.7下载和安装
- scala IDE插件下载和安装
- spark下载和配置
- hadoop下载和配置
- Spark示例运行
操作指南#
1、 jdk1.8下载和安装##
eclipse4.7(oxygen)要求的JRE/JDK版本最低为1.8。
1)打开JDK8u131下载页面(下载地址如下):
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html

2)点选【Accept License Agreement 】,下载获得安装文件jdk-8u131-windows-x64.exe。
3)双击执行jdk-8u131-windows-x64.exe可直接安装JDK1.8,也可以参考下述步骤制作绿色版放置在本机目录(例:D:\Java\jdk1.8.0_131)
- 鼠标右击jdk-8u131-windows-x64.exe,解压安装包文件到本机目录(例:E:\jdk-8u131-windows-x64)
- 打开命令提示符,切换到【E:\jdk-8u131-windows-x64.rsrc\1033\JAVA_CAB10】 目录下,执行【extrac32 111】命令。
E:
cd E:\jdk-8u131-windows-x64\.rsrc\1033\JAVA_CAB10
extrac32 111
- 将【E:\jdk-8u131-windows-x64.rsrc\1033\JAVA_CAB10】目录下生成的【tools.zip】文件解压到【E:\jdk-8u131-windows-x64.rsrc\1033\JAVA_CAB10\tools】目录,在命令提示符中切换到该目录,执行下述命令创建jar包:
for /r %x in (*.pack) do .\bin\unpack200 -r "%x" "%~dx%~px%~nx.jar"
- 大功告成,【E:\jdk-8u131-windows-x64.rsrc\1033\JAVA_CAB10\tools】目录就是你想要的绿色版jdk。
4)配置环境变量
- 新增环境变量【JAVA_HOME】指向jdk目录(例:D:\Java\jdk1.8.0_131)
- 新增环境变量【CLASSPATH】,设置变量值为【.;%JAVA_HOME%\lib;%JAVA_HOME%\lib\tools.jar】
- 修改环境变量【PATH】,在变量值末尾追加【;%JAVA_HOME%\bin; %JAVA_HOME%\jre\bin;】
5)校验JDK环境
打开命令提示符,输入【Java -version】,正常显示jdk版本号代表jdk安装配置成功。

2. eclipse4.7下载和安装
1)打开eclipse官网下载页面:
https://www.eclipse.org/downloads/eclipse-packages/

2)下载【Eclipse IDE for Java EE Developers】的window 64版,获得【 eclipse-jee-oxygen-R-win32-x86_64.zip】。
3)解压【eclipse-jee-oxygen-R-win32-x86_64.zip】到本机目录(例:D:\Java\eclipse-jee-oxygen-R-win32-x86_64)
4)打开【D:\Java\eclipse-jee-oxygen-R-win32-x86_64\eclipse】目录下的【eclipse.ini】配置文件,在末尾另起一行添加下述配置:
-Dfile.encoding=utf-8
3. scala IDE插件下载和安装
spark采用scala作为默认编程语言,所以需要为eclipse安装 scala IDE插件。
1)打开scala IDE插件下载页面
http://scala-ide.org/download/prev-stable.html

2)由于Spark2.1.1基于Scala2.11.8编译,这里选择Scala IDE4.5.0对应的zipfile,获得【base-20161213-1347.zip】,解压到本机目录(例:D:\java\Scala-IDE-211-update-site)。
3)启动eclipse4.7,指定一个workspace(例:D:\java\eclipse-workspace),进入Eclipse主界面。
4)通过【help-->Install New Software...】打开插件安装页,点击【Add】按钮添加Scala IDE插件对应的Repository(通过【Local...】按钮指向目录【D:\java\Scala-IDE-211-update-site\base】),确定后返回。

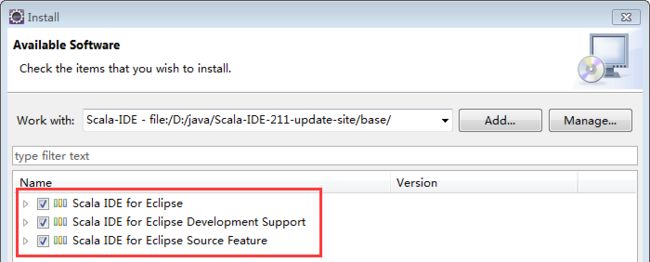
5)勾选【Scala IDE for Eclipse】、【Scala IDE for Eclipse Development Support】、【Scala IDE for Eclipse Source Feature】,点击【Next】按钮完成安装并根据提示重启Eclipse。
6)Eclipse重启后,通过【Window --> Perspective --> Open Perspective --> Other...】打开Scala开发透视图。
4. spark下载和配置
Spark官方网站针对多个Hadoop版本提供不同的预编译版,此处选择最新版(搭载Hadoop2.7的Spark2.1.1)。
1)打开Spark下载页面
https://spark.apache.org/downloads.html

2)下载获得【spark-2.1.1-bin-hadoop2.7.tgz】,解压到本机目录(例:D:\java\spark-2.1.1-bin-hadoop2.7)。
3)在Eclipse工作空间(workspace),通过【Window --> Preferences】打开首选项配置页,切换到【Java --> Build Path --> User Libraries】,为Spark2.1.1创建User Library。

4)通过【Add External JARs...】按钮,将Spark2.1.1相关jar包(目录【D:\java\spark-2.1.1-bin-hadoop2.7\jars】中除【scala-compiler-2.11.8.jar】、【scala-library-2.11.8.jar】之外的其他jar包)添加到User Library【Spark2.1.1】中保存。
5. hadoop下载和配置
windows系统开发执行spark程序需要Hadoop环境支持(否则将抛出Failed to locate the winutils binary in the hadoop binary path错误),可以通过第三方组件【winutils】完成。
1、打开winutils在github上的首页面,
https://github.com/steveloughran/winutils/

2)点击【Clone or download】按钮,然后点击【Download ZIP】按钮下载获得【winutils-master.zip】,将压缩包下【hadoop-2.7.1】文件夹解压到本机目录(例:D:\java\hadoop-2.7.1)。
注:windows本机运行spark需要用到 D:\java\hadoop-2.7.1\bin\winutils.exe
6. Spark示例运行
前文下载的【spark-2.1.1-bin-hadoop2.7.tgz】中包含spark示例代码,打开目录【D:\java\spark-2.1.1-bin-hadoop2.7\examples\src\main】,可以看到spark示例代码包括java、scala、R、python四种,这里演示java示例的JavaWordCount。
1)在Eclipse中创建一个名为【sparkworks-helloworld】的scala工程。

2)为【sparkworks-helloworld】工程添加前文创建的User Library【spark2.1.1】,然后创建名为【org.apache.spark.examples】的包。

3)复制【D:\java\spark-2.1.1-bin-hadoop2.7\examples\src\main\java\org\apache\spark\examples】目录下的【JavaWordCount.java】文件,粘贴到包【org.apache.spark.examples】下。
4)选中【JavaWordCount.java】,通过右键菜单【Run as --> Java Application】执行JavaWordCount的main函数,在控制台可看到下述提示:
Usage: JavaWordCount
5)选中【JavaWordCount.java】,通过右键菜单【Run as --> Run Configurations...】打开配置界面,切换到Arguments选项卡,配置【Program arguments 】和【 VM arguments 】,前者对应于单词计数程序的输入文件,后者设置Spark运行环境。

VM arguments:
-Dspark.master=local[*]
-Dhadoop.home.dir=D:\java\hadoop-2.7.1
6)再次执行JavaWordCount的main函数,可在控制台看到执行结果输出。
结语#
本文讲述64位win7操作系统下基于eclipse的spark开发环境搭建,未涉及大数据集群环境,但足够你启动Local版的spark程序的开发和调试了。