Queue
Queue继承自 Collection,我们先来看看类结构吧,代码量比较少,我直接贴代码了
public interface Queue extends Collection {
boolean add(E var1);
boolean offer(E var1);
E remove();
E poll();
E element();
E peek();
}
从方法名上不太好猜每个方法的作用,我们直接来看 API 吧
| ~ | 抛出异常 | 返回特殊值 |
|---|---|---|
| 插入 | add(e) | offer(e) |
| 移除 | remove() | poll() |
| 检查 | element() | peek() |
好像就除了对增删查操作增加了一个不抛出异常的方法,没什么特点吧,我们继续看描述~
在处理元素前用于保存元素的 collection。除了基本的 Collection 操作外,队列还提供其他的插入、提取和检查操作。每个方法都存在两种形式:一种抛出异常(操作失败时),另一种返回一个特殊值(null 或 false,具体取决于操作)。插入操作的后一种形式是用于专门为有容量限制的 Queue 实现设计的;在大多数实现中,插入操作不会失败。
就描述了这三组方法的区别,那么以后我操作队列尽量用不抛出异常的方法总行了吧。另外也没看出什么名堂,那么队列这个接口到底是规范了什么行为?我记得队列好像是一种数据常用的结构,我们来看看百度百科的定义吧
队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。
看了百度百科的描述,才知道队列规范了集合只允许在表前端删除,在表后端插入。这不就是 FIFO 嘛~~
什么是 FIFO?
FIFO 是英语 first in first out 的缩写。先进先出,想象一下,在车辆在通过不允许超车的隧道时,是不是先进入隧道的车辆最先出隧道。
FIFO 有什么用?
这个问题我回答不了,队列只是一种数据结构,在某些特定的场合,用队列实现效率会比较高。
Queue 的抽象实现类
AbstractQueue 是Queue 的抽象实现类,和Lst、Set 的抽象实现类一样,AbstractQueue 也继承自 AbstractCollection。
AbstractQueue 实现的方法不多,主要就 add、remove、element 三个方法的操作失败抛出了异常。
Queue 的实现类
PriorityQueue 直接继承自 AbstractQueue,并且除序列号接口外,没实现任何接口,大概算是最忠诚的 Queue 实现类吧。照惯例,我们先来看看 API 介绍。
一个基于优先级堆的无界优先级队列。优先级队列的元素按照其自然顺序进行排序,或者根据构造队列时提供的 Comparator 进行排序,具体取决于所使用的构造方法。优先级队列不允许使用 null 元素。依靠自然顺序的优先级队列还不允许插入不可比较的对象.
此队列的头 是按指定排序方式确定的最小 元素。如果多个元素都是最小值,则头是其中一个元素——选择方法是任意的。队列获取操作 poll、remove、peek 和 element 访问处于队列头的元素。
优先级队列是无界的,但是有一个内部容量,控制着用于存储队列元素的数组大小。它通常至少等于队列的大小。随着不断向优先级队列添加元素,其容量会自动增加。无需指定容量增加策略的细节。
进队列的数据还要进行排序,每次取都是取到元素最小值,尼玛,说好的 FIFO 呢?好吧,我暂且当这是一个取出时有顺序的队列,看起来和昨天学的 TreeSet 功能差不多哈。
PriorityQueue 叫优先队列,即优先把元素最小值存到队头。想象一下,使用PriorityQueue去管理一个班的学生,根据可以年龄、成绩、身高设置好对应的 Comparator ,然后就能自动从小到大排序呢。哈哈哈~
我们先来看一下 PriorityQueue 的实现吧~
类成员变量如下~
public class PriorityQueue extends AbstractQueue implements Serializable {
private static final long serialVersionUID = -7720805057305804111L;
private static final int DEFAULT_INITIAL_CAPACITY = 11;
transient Object[] queue;
private int size;
private final Comparator comparator;
transient int modCount;
private static final int MAX_ARRAY_SIZE = 2147483639;
}
没错,基于数组的实现,也能找到 grow 扩容方法,少了 List 的各种方法,Queue 的方法我们前面也看了。那么我们就之前去看他是怎么实现优先队列的~
思考一下,既然是数组实现,又能按元素大小顺序去取出,那么肯定是在添加元素的时候做的排序,直接把对应的元素值大小的元素添加到对应的位置。那么我们就从 add 方法看起吧~~
public boolean add(E var1) {
return this.offer(var1);
}
public boolean offer(E var1) {
if(var1 == null) {
throw new NullPointerException();
} else {
++this.modCount;
int var2 = this.size;
if(var2 >= this.queue.length) {
this.grow(var2 + 1);
}
this.size = var2 + 1;
if(var2 == 0) {
this.queue[0] = var1;
} else {
this.siftUp(var2, var1);
}
return true;
}
}
private void siftUp(int childIndex) {
E target = elements[childIndex];
int parentIndex;
while (childIndex > 0) {
parentIndex = (childIndex - 1) / 2;
E parent = elements[parentIndex];
if (compare(parent, target) <= 0) {
break;
}
elements[childIndex] = parent;
childIndex = parentIndex;
}
elements[childIndex] = target;
}
上面的方法调用都很简单,我就不写注释了,add 调用 offer 添加元素,如果集合里面的元素个数不为零,则调用 siftUp 方法把元素插入合适的位置。
敲黑板~~接下来的东西我看了老半天才看明白。有点吃力
注意了,siftUp里面的算法有点奇怪,我一开始还以为是二分插入法,然而并不是。
首先,我们这里走进了一个误区,PriorityQueue 虽然是一个优先队列,能够满足我们刚刚说的需求,把一个班的学生按年龄大小顺序取出来,但是在内存中(数组中)的保存却并不是按照从小到大的顺序保存的,但是一直 poll,是能够按照元素从小到大的顺去取出结果。
这里我做了一个小测试。
PriorityQueue integers = new PriorityQueue<>();
integers.add(8);
integers.add(6);
integers.add(5);
已知 PriorityQueue 用数组存储,大家猜猜我这样存进队列的三个数子是怎样存储的?
一开始我以为是5、6、8的顺序,但是 debug 的时候看到 PriorityQueue 里面保存数据数组里面的存放顺序是5、8、6.why?
然后我调用下面这个方法打印~
while (!integers.isEmpty()) {
Log.e("_____", integers.poll() + "~~");
}
结果是5、6、8.这他妈就尴尬了。
然后怎么办~去找度娘呗。。。
好了,开始解析~~
不知道大家记不记得一种数据结构叫二叉树,这里就是使用了二叉树的思路,所以比较难理解。
首先,这里使用的是一种特殊的二叉树:1.父节点永远小于子节点,2.优先填满第 n 层树枝再填 n+1 层树枝。也就是说,数组里面的5、8、6是这样存储的
依次添加元素8、6、5.
5
/ \
8 6
‖
∨
数组角标位置
0
/ \
1 2
这样能理解了吧,再回过头去看siftUp方法,捋一下添加元素的过程。
添加8
没什么好说的,直接添加一个元素到到数组[0]即可,二叉树添加一个顶级节点-
添加5
首先把[1]的位置赋值给5,使得数组中的元素为{8,5}
然后执行siftUp(1)方法(1是刚刚插入元素5的角标)siftUp方法首先获取5的父节点,判断5是否小于父节点。 如果小于,则交换位置继续比较祖父节点 如果大于或者已经到顶级节点,结束。
siftUp方法后,数组变为{5,8}
- 添加6
重复上面的动作,数组变为{5,8,6}
问:如果此时添加数字7,数组的顺序是多少?
思考一下3分钟~~
好,3分钟过去了,结果是{5,7,6,8}
为什么会这样?拿着数字7代入到上面的方法中去算呀,首先8在数组中的角标是3,3要去和父节点比,求父节点的公式是(3-1)/2 = 1.于是父节点的角标是1,7<8,因此交换位置,此时角标1还有父节点 (1-1)/2 = 0,再比较7和5,7>5,满足大于父节点条件,结束。
好了,现在应该明白了吧~~~没明白再回过头去理解一遍。
接下来,我们来看循环调用 poll() 方法是怎样从{5,8,6}的数组中按照从小到大的顺序取出5、6、8.
我们来看 poll()方法
public E poll() {
if (isEmpty()) {
return null;
}
E result = elements[0];
removeAt(0);
return result;
}
private void removeAt(int index) {
size--;
E moved = elements[size];
elements[index] = moved;
siftDown(index);
elements[size] = null;
if (moved == elements[index]) {
siftUp(index);
}
}
private void siftDown(int rootIndex) {
E target = elements[rootIndex];
int childIndex;
while ((childIndex = rootIndex * 2 + 1) < size) {
if (childIndex + 1 < size
&& compare(elements[childIndex + 1], elements[childIndex]) < 0) {
childIndex++;
}
if (compare(target, elements[childIndex]) <= 0) {
break;
}
elements[rootIndex] = elements[childIndex];
rootIndex = childIndex;
}
elements[rootIndex] = target;
}
这是 api23 里面 PriorityQueue 的方法,和 Java8 略有不同,但实现都是一样的,只是方法看起来好理解一些。
首先 poll 方法取出了数组角标0的值,这点不用质疑,因为角标0对应二叉树的最高节点,也就是最小值。
然后在 removeAt 方法里面把数组的最后一个元素覆盖了第0个元素,再是将最后一个元素置空,好,到了这里,进入第二个关键点了,黑板敲起来~~
这里在赋值之后调用了 siftDown(0);
我们来看 siftDown()方法~
这个方法从0角标(最顶级父节点)开始,先判断左右子节点,取较小的那个一,和父节点比较,然后再对比左右子节点。根据我们这里二叉树的特点,最终能取到最小的那个元素放到顶级父节点,保证下一次 poll能取到当前集合最小的元素。具体代码不带着读了~~
ok,PriorityQueue 看完了。
Deque
刚刚我们一直在找 FIFO 的集合,找到个 PriorityQueue,然而并不是。
然后我们继续找呗,发现了 Queue 有一个子接口Deque
来看看 API 文档的定义~
一个线性 collection,支持在两端插入和移除元素。名称 deque 是“double ended queue(双端队列)”的缩写,通常读为“deck”。大多数 Deque 实现对于它们能够包含的元素数没有固定限制,但此接口既支持有容量限制的双端队列,也支持没有固定大小限制的双端队列。
此接口定义在双端队列两端访问元素的方法。提供插入、移除和检查元素的方法。每种方法都存在两种形式:一种形式在操作失败时抛出异常,另一种形式返回一个特殊值(null 或 false,具体取决于操作)。插入操作的后一种形式是专为使用有容量限制的 Deque 实现设计的;在大多数实现中,插入操作不能失败。
嗯~就是一个首尾插入删除操作都直接的接口。
我们刚刚说了 Queue 遵循 FIFO 规则,当有了 Deque,我们还能实现 LIFO(后进先出)。反正像先进后出、后进先出都能在 Deque 的实现类上做到,具体看各位 Coder 们怎么操作了。
总结一下 Deque 的方法~
| ~~-- | ____第一个元素(头部)..... | _____最后一个元素(尾部) |
|---|
| ~ | 抛出异常 | 特殊值 | 抛出异常 | 特殊值 |
|---|---|---|---|---|
| 插入 | addFirst(e) | offerFirst(3) | addLast(e) | offerLast(3) |
| 移除 | removeFirst() | pollFirst() | removeLast() | pollLast() |
| 检查 | getFirst() | peekFirst() | getLast() | peekLast() |
____特么的,MD 语法不支持这种不对齐表格
如果想用作 LIFO 队列,应优先使用此接口,而不是遗留的 Stack 类。在将双端队列用作堆栈时,元素被推入双端队列的开头并从双端队列开头弹出。堆栈方法完全等效于 Deque 方法,如下表所示:
| 堆栈方法 | 等效 Deque 方法 |
|---|---|
| push(e) | addFirst(e) |
| pop() | removeFirst() |
| peek() | peekFirst() |
就酱紫吧,也没什么特别的,我个人不太喜欢这个接口,我觉得这个接口规范的行为有点多,不符合接口隔离原则和单一职能原则。
接下来我们就去看看 Deque 的实现类吧。
看两个具有代表性的类吧,第一个是基于数组实现的 ArrayQeque,第二个是基于链表实现的LinkedList。
LinkedList
前面 List 的时候我们看过 LinkedList,LinkedList 继承自AbstractList,同时也实现了 List 接口,因此这是一个很全能的类。一句话描述就是:基于链表结构实现的数组,同时又支持双向队列操作。
还记得之前在 List 结尾留的一个思考题么:怎样用链表的结构快速实现栈功能LinkedListStack?
public class LinkedListStack extends LinkedList{
public LinkedListStack(){
super();
}
@Override
public void push(Object o) {
super.push(o);
}
@Override
public Object pop() {
return super.pop();
}
@Override
public Object peek() {
return super.peek();
}
@Override
public boolean isEmpty() {
return super.isEmpty();
}
public int search(Object o){
return indexOf(o);
}
}
呐,这里给出了实现,其实什么都没做,就是调用了父类方法。这个类只是看起来结构清晰的实现了 LIFO,但是由于继承自 LinkedList,还是可以调用 addFirst 等各种“非法操作方法”,这就是我说的不理解 Java 为什么要这样设计,还推荐使用 Deque 替换栈实现。项目实际开发中,同学们要使用栈结构直接用 LinkedList就行了,我这里 LinkedListStack 只是便于大家理解 LinkedList 也可以用作栈集合。
ArrayDeque
照惯例先看 API 定义~
Deque接口的大小可变数组的实现。数组双端队列没有容量限制;它们可根据需要增加以支持使用。它们不是线程安全的;在没有外部同步时,它们不支持多个线程的并发访问。禁止 null 元素。此类很可能在用作堆栈时快于 Stack,在用作队列时快于 LinkedList。
感觉 ArrayDeque 才是一个正常的 Deque 实现类,ArrayDeque 直接继承自 AbstractCollection,实现了Deque接口。
类部实现和 ArrayList 一样都是基于数组,当头尾下标相等时,调用doubleCapacity()方法,执行翻倍扩容操作。
头尾操作是什么鬼?我们都知道ArrayDeque 是双向列表,就是可以两端一起操作的列表。因此使用了两个指针 head 和tail 来保存当前头尾的 index,一开始默认都是0角标,当添加一个到尾的时候,tail先加1,再把值存放到 tail 角标的数组里面去。
那么 addFirst 是怎么操作的呢?head 是0,添加到-1的角标上面去?其实不是的,这里 你可以把这个数组当成是一个首尾相连的链表,head 是0的时候 addFirst 实际上是把值存到了数组最后一个角标里面去了。即: 当 head 等于0的时候 head - 1 的值 数组.length - 1,代码实现如下。
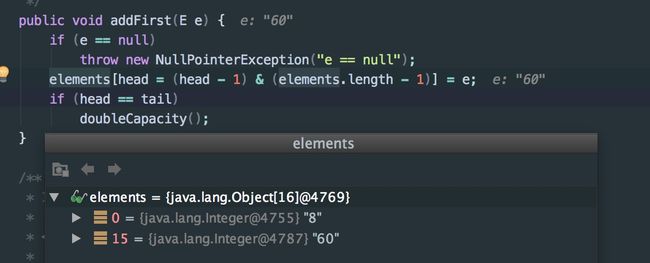
如图,这是我如下代码的执行添加60时 debug
ArrayDeque integers = new ArrayDeque<>();
integers.addLast(8);
integers.addFirst(60);
然后当head == tail的时候表示数组用满了,需要扩容,就执行doubleCapacity扩容,这里的扩容和 ArrayList 的代码差不多,就不去分析了。
总结
凡是牵涉到需要使用 FIFO 或者 LIFO 的数据结构时,推荐使用 ArrayDeque,LinkedList 也行,还有 get(index)方法~~