嗯 今天看下 LinkedList,这个 最后会总结写 ArrayList 的区别吧
image
-
先看下构造函数
public LinkedList() { } public LinkedList(Collection c) { this(); addAll(c); }
// 咳咳 怎么说呢 没想到你是这样的构造函数 什么都不干
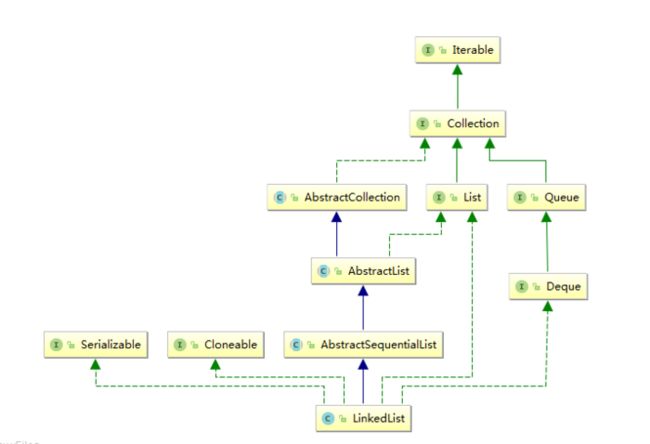
在看LinkedList 的增删改查之前 我们得有一个认知 就是LinkedList 的 数据结构是 链表(从名字就看出来了),他的每个 节点 都是存在一个 内部类中
private static class Node {
E item;
Node next;
Node prev;
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
Node 节点 可以看出 LinkedList 是 一个双向链表 存了他自己 和 next 和 prev
接下去我们就可以 真正开始看 增删改查了
老规矩看下 add
- 增 add() ,addAll()
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node l = last;
// 构建 node 节点
final Node newNode = new Node<>(l, e, null);
//将最新的add 放到 最后
last = newNode;
// 如果尾节点为空 新加入的变成 头结点
if (l == null)
first = newNode;
else// 否则 之前的last 的 next 连接到新加入的节点
l.next = newNode;
size++;// 数组size 变大
modCount++; // 增加修改次数
}
- 删 remove
根据对象
public boolean remove(Object o) {
if (o == null) {
for (Node x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
根据 对象删除 比较简答 直接去 equals()
根据 下 标删除
public E remove(int index) {
// 判断是否越界
checkElementIndex(index);
return unlink(node(index));
}
// 这段代码用到了 二分法查找 出node 节点
Node node(int index) {
// assert isElementIndex(index);
// 有是size>>1 这个意思就是 size/2 ( >> 效率高)
// index list的左半部分的时候
if (index < (size >> 1)) {
Node x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else { // 右半部分
Node x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
// unlink 就是清楚所有 有关节点 的链接然后 删除连接 节点前后 的 next 和prev 在相互连接
E unlink(Node x) {
// assert x != null;
final E element = x.item;
final Node next = x.next;
final Node prev = x.prev;
// 如果当前节点的 prev 为空 则当前节点的next 变成头节点
if (prev == null) {
first = next;
} else {//否则 prev的 next 连接 当前节点的next
prev.next = next;
x.prev = null;
}
if (next == null) { //如果next 则 prev 变成last
last = prev;
} else { // 否则 next prev 连接 当前节点的prev
next.prev = prev;
x.next = null;
}
x.item = null; // 当前节点 全部连接置空 (提醒jvm GC )
size--; // 减少 数据大小
modCount++; //增加修改次数
return element; // 弹出 当前节点的值
}
- 改 set
public E set(int index, E element) {
checkElementIndex(index);
// 查处
Node x = node(index);
//
E oldVal = x.item;
// 修改
x.item = element;
//返回
return oldVal;
}
查 get
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
嗯 看起来都很简单的样子 从源码来说 让我看看其他的扩展
这得从昨天 贴的 最后一段代码 说起 ArrayList 和 LinkedList遍历的时候
从今天可以看出来 LinkedList get 是 二分法查找 而 ArrayList 的get 是 直接数组的下标取出来 当然是 ArrayList 遍历快
我们在比较下 remove
回忆一下 ArrayList 增 是 调用底层本地 native 方法 整个数组 拷贝 移动的数组位置 之后 数组向前移动一位
但是LinkedList 增 移动的时候 就很简单了 unlink 改变下 链表 移动元素 前后的 prev 和next 就好了 理论上来说 是Linked remove 快点
实验下:
static final int N=50000;
static long timeListByPrev(List list){
long start=System.currentTimeMillis();
Object o = new Object();
for(int i=0;i可以看出 差距很大 四舍五入 差100倍 (本机测试 不代表任何基准)