前言:ZIPKIN作为当前“分布式服务链路跟踪”问题的流行解决方案之一,正在被越来越多的公司和个人学习使用。其中很重要的一块,就是上报链路数据。那么知道服务端如何接收数据,以及我们该怎样上报数据到服务端就显得十分重要。虽然ZIPKIN官方也开源了一个客户端Brave,但是本文却并不想直接介绍Brave,而是想站在一个从零开发ZIPKIN客户端的角度,一层层分析解决如何自己写一个ZIPKIN客户端,直到最后引出Brave。本文最终想达到的效果,就是希望通过本文,能让大家对ZIPKIN的链路上报有一个详尽的理解和认识。
零行代码快速开始
ZIPKIN是Spring Boot服务,因此启动起来十分方便,直接运行ZIPKIN JAR包就可以了。ZIPKIN JAR包我们可以自行编译ZIPKIN源码获得,也可以从下面的仓库获取,这个仓库专门存放ZIPKIN各种编译好的JAR包,仓库地址为:
https://dl.bintray.com/openzipkin/maven/io/zipkin/java/
进入zipkin-server目录下载server jar包,比如下载2.11.5版本,运行jar包:
java -jar zipkin-server-2.11.5-exec.jar
这样本地就起了一个ZIPKIN服务,浏览器中输入http://localhost:9411/zipkin/,即可打开ZIPKIN首页,效果如下:

接下来,我们开始上报数据,现在我不想写任何代码,那么就用postman发起一次post请求上报数据吧:
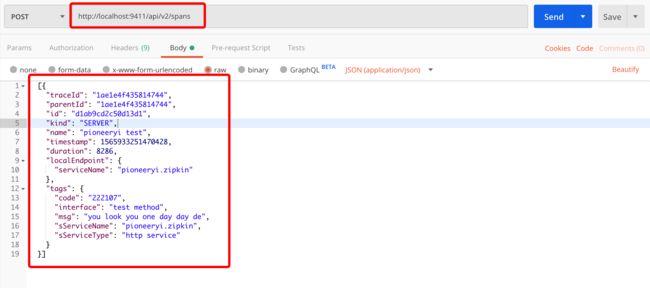
上报后在本地ZIPKIN服务上即可看到刚上报的数据效果:

没有任何一句代码,一个完整的ZIPKIN数据上报存储展示就完成了,那么我们来思考下:
1、如果自己写一个上ZIPKIN客户端,该如何写?
分析:要上传数据给服务端,那么必须要搞清楚,ZIPKIN服务端可以接受什么样格式的数据?支持的编码解码协议是什么?还有支持那些通信传输协议?
Task: 了解了服务怎么接收数据后,客户端的task也就明确了:
1)以ZIPKIN服务端支持的数据格式组织数据;
2)以ZIPKIN服务端支持的编解码协议编码数据;
3)以ZIPKIN服务端支持的传输协议上报数据。
2、基础ZIPKIN客户端完成后,如何适配各种组件?
描述:一个服务通常涉及多个组件,包括服务框架,消息中间件,各种数据库等,那么怎么上报这些组件的数据给服务端了,值得我们思考?
分析:其实最简单的方法就是采用一个装饰者模式包装一下组件接口,在其中加入上报的逻辑,但是这种方法局限很大,不灵活。除此之外,我们或许我们可以利用下拦截器技术,AOP技术,以及Agent,探针等技术做到无侵入上报数据。
服务端如何接收数据的?
要想自己写一个ZIPKIN客户端,必须搞清楚ZIPKIN服务端是怎么接收数据的,包括数据格式协议是怎样的?编解码协议是怎样的?还有支持那么传输协议?
ZIPKIN支持的数据格式是怎样的?
ZIPKIN是兼容OpenTracing标准的,OpenTracing规定,每个Span包含如下状态:
- 操作名称
- 起始时间
- 结束时间
- 一组 KV 值,作为阶段的标签(Span Tags)
- 阶段日志(Span Logs)
- 阶段上下文(SpanContext),其中包含 Trace ID 和 Span ID
- 引用关系(References)
OpenTracing规范与zipkin对应关系如下:
| OpenTracing | ZIPKIN |
|---|---|
| 操作名称 | name |
| 起始时间 | timestamp |
| 结束时间 | timestamp+duration |
| 标签 | tags |
| Span上下文 | traceId; id |
| 引用关系 | parentId |
| Span日志 | 无 |
除此之外,ZIPKIN SAPN还增加了其他几个字端:
| 字端 | 描述 |
|---|---|
| Kind kind | Spanl类型,比如是Server还是Client |
| Annotaion | 表示某个时间点发生的Event,Event类型:cs:Client Send 请求;sr:Server Receive到请求;ss:Server 处理完成、并Send Response;cr:Client Receive 到响应 |
| Endpoint localEndpoint | 描述本地服务信息,比如服务名,ip等,方便根据服务名检索链路 |
| Endpoint remoteEndpoint | RPC调用时,描述远程服务的服务信息 |
最终,包含兼容OpenTracing标准的字端,以及其本身的一些字端后,zipkin的span数据字端如下:
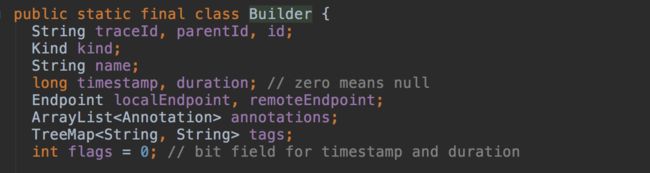
了解了ZIPKIN的数据字端格式后,我们再看看ZIPKIN支持的编解码协议。
ZIPKIN支持那些编解码协议?
Zipkin主要支持三种编解码协议,分别为JSON, PROTO3, THRIFT。
JSON编解码如下:
JSON_V1 {
public Encoding encoding() {
return Encoding.JSON;
}
public boolean decode(byte[] bytes, Collection out) {
Span result = this.decodeOne(bytes);
if (result == null) {
return false;
} else {
out.add(result);
return true;
}
}
public boolean decodeList(byte[] spans, Collection out) {
return (new V1JsonSpanReader()).readList(spans, out);
}
public Span decodeOne(byte[] span) {
V1Span v1 = (V1Span)JsonCodec.readOne(new V1JsonSpanReader(), span);
List out = new ArrayList(1);
V1SpanConverter.create().convert(v1, out);
return (Span)out.get(0);
}
public List decodeList(byte[] spans) {
return decodeList(this, spans);
}
}
JSON_V2 {
public Encoding encoding() {
return Encoding.JSON;
}
public boolean decode(byte[] span, Collection out) {
return JsonCodec.read(new V2SpanReader(), span, out);
}
public boolean decodeList(byte[] spans, Collection out) {
return JsonCodec.readList(new V2SpanReader(), spans, out);
}
@Nullable
public Span decodeOne(byte[] span) {
return (Span)JsonCodec.readOne(new V2SpanReader(), span);
}
public List decodeList(byte[] spans) {
return decodeList(this, spans);
}
}
THRIFT编解码如下:
THRIFT {
public Encoding encoding() {
return Encoding.THRIFT;
}
public boolean decode(byte[] span, Collection out) {
return ThriftCodec.read(span, out);
}
public boolean decodeList(byte[] spans, Collection out) {
return ThriftCodec.readList(spans, out);
}
public Span decodeOne(byte[] span) {
return ThriftCodec.readOne(span);
}
public List decodeList(byte[] spans) {
return decodeList(this, spans);
}
}
PROTO3编解码如下:
PROTO3 {
public Encoding encoding() {
return Encoding.PROTO3;
}
public boolean decode(byte[] span, Collection out) {
return Proto3Codec.read(span, out);
}
public boolean decodeList(byte[] spans, Collection out) {
return Proto3Codec.readList(spans, out);
}
@Nullable
public Span decodeOne(byte[] span) {
return Proto3Codec.readOne(span);
}
public List decodeList(byte[] spans) {
return decodeList(this, spans);
}
}
其中Json是默认支持的,也是使用起来最方便的,除此之外,还包括Thirft和Proto3可供开发者选择。
ZIPKIN支持那些传输协议?
Zipkin默认支持Http协议,除此之外,它还支持kafka,rabbitmq以及scribe协议:

他们的初始化过程如下:
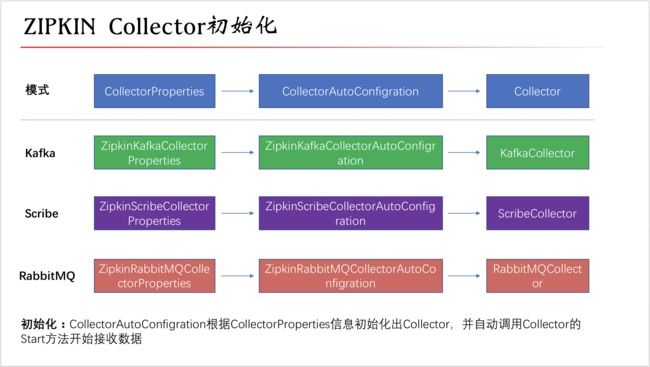
传输协议支持的编解码协议如下:

其中Scribe限定了只支持Thirft协议,而HTTP、Kafka和RabbitMQ则是三种协议都支持。
如何做到支持所有的编码解码协议了?ZIPKIN中提供了一个自动探测编解码的类SpanBytesDecoderDetector,其中核心方法如下:
static BytesDecoder detectDecoder(byte[] bytes) {
if (bytes[0] <= 16) { // binary format
if (protobuf3(bytes)) return SpanBytesDecoder.PROTO3;
return SpanBytesDecoder.THRIFT; /* the first byte is the TType, in a range 0-16 */
} else if (bytes[0] != '[' && bytes[0] != '{') {
throw new IllegalArgumentException("Could not detect the span format");
}
if (contains(bytes, ENDPOINT_FIELD_SUFFIX)) return SpanBytesDecoder.JSON_V2;
if (contains(bytes, TAGS_FIELD)) return SpanBytesDecoder.JSON_V2;
return SpanBytesDecoder.JSON_V1;
}
现在我们已经知道了zipkin服务接收的数据格式以及编解码协议和传输协议,那么接下来就可以写一个客户端了!
自己写一个ZIPKIN客户端
对于服务端如何接收数据,有了一个全面的认识后,我们就可以着手开始写一个ZIPKIN客户端了。
那么,首先定义客户端上报的数据格式,最简单的方式就是定义一个跟ZIPKIN服务端一样数据格式的Span就可以了:
@Setter
@Getter
public static class MySapn {
private String traceId;
private String parentId;
private String id;
private String name;
private long timestamp;
private long duration;
private Map tags;
String kind;
Endpoint localEndpoint, remoteEndpoint;
public static enum Kind {
CLIENT,
SERVER,
PRODUCER,
CONSUMER
}
public static class Endpoint {
String serviceName, ipv4, ipv6;
byte[] ipv4Bytes, ipv6Bytes;
int port; // zero means null
public Endpoint(String serviceName) {
this.serviceName = serviceName;
}
}
}
数据格式确定后,接着就编码数据,ZIPKIN支持三种编码方式,JSON、THIFT和PROTO3,为了简单方便,我们选择JSON协议编码Span数据。注意,ZIPKIN JSON字符串前后需要加括号。
数据编码后,接着上报数据,ZIPKIN默认支持HTTP协议方式,JAVA HTTP请求包很多,我们随便选择一种,比如选择Apach的HttpClient jar包,代码如下:
public class App {
private static final String serverUrl = "http://localhost:9411/api/v2/spans";
public static void main(String[] args) {
MySapn span = new MySapn();
span.traceId = "1ae1e4f435814744";
span.parentId = "1ae1e4f435814744";
span.id = "d1ab9cd2c50d13d1";
span.kind = MySapn.Kind.SERVER.toString();
span.name = "my client test";
span.timestamp = 1565933251470428L;
span.duration = 8286;
span.localEndpoint = new MySapn.Endpoint("My client");
Map tags = new HashMap<>();
tags.put("name", "pioneeryi");
tags.put("lover", "dandan");
span.tags = tags;
doPost(serverUrl, span);
System.out.println("Hello World!");
}
public static void doPost(String url, MySapn span) {
try {
HttpClient httpClient = new DefaultHttpClient();
HttpPost post = new HttpPost(url);
post.setHeader("Content-Type", "application/json");
post.setHeader("charset", "UTF-8");
String body = new Gson().toJson(span);
body = "[" + body + "]";
System.out.print(body);
StringEntity entity = new StringEntity(body);
post.setEntity(entity);
HttpResponse httpResponse = httpClient.execute(post);
System.out.print(httpResponse);
} catch (Exception exception) {
System.out.print("do post request fail");
}
}
}
maven pom如下:
org.apache.httpcomponents
httpclient
4.5.6
com.google.code.gson
gson
2.8.5
运行上面main方法,即可上报Span数据,打开zipkin首页:http://localhost:9411/zipkin/,搜索刚上报的Span的TraceId,展示效果如下:

一个最简单的,采用JSON编码数据,HTTP协议上传数据的客户端我们就完成了。为了用户调用方便,我们可以将上面的代码封装为一个接口供用户使用:
public void reportSpan(MySpan span)
但是这个太简陋了,我们只支持了一种一个编解码协议,一种传输协议,开始优化:
优化一:支持多种编解码,支持多种传输协议。这个时候就需要定一个上报接口类了,根据不同传输协议提供不同实现。编解码也是同样的,定义编码接口,根据不同编码协议提供不同实现。
此外,当前这个客户端是同步上报的,性能很差,因此必须改成异步上报,接着优化:
优化二:上报改成异步上报,队列+线程。
有了这两步优化后,client大体框架就初步成型了,写好了客户端后,怎么适配各个组件,做到无侵入上报也很重要,继续优化:
优化三:适配各个组件,比如Spring Boot,Kafak,MySql等等。
一个完整的Client,还是有很多工作要做的,这里咱就不继续深入优化开发了,直接看看官方的Brave怎么做的!
探究ZIPKIN客户端Brave
为了说明Brave的使用和上报过程,我们先写一个很简单的上报Demo,进行演示。Demo将上报一个“一父Span,两个子Span“的链路,demo如下:
public class TraceDemo {
public static void main(String[] args) {
Sender sender = OkHttpSender.create("http://localhost:9411/api/v2/spans");
AsyncReporter asyncReporter = AsyncReporter.create(sender);
Tracing tracing = Tracing.newBuilder()
.localServiceName("my-service")
.spanReporter(asyncReporter)
.build();
Tracer tracer = tracing.tracer();
Span parentSpan = tracer.newTrace().name("parent span").start();
Span childSpan1 = tracer.newChild(parentSpan.context()).name("child span1").start();
sleep(500);
childSpan1.finish();
Span childSpan2 = tracer.newChild(parentSpan.context()).name("child span2").start();
sleep(500);
childSpan2.finish();
parentSpan.finish();
}
}
其中 maven pom 引入如下包:
io.zipkin.brave
brave
5.3.3
io.zipkin.reporter2
zipkin-sender-okhttp3
2.6.0
启动zipkin 服务:
java -jar zipkin-server-2.11.5-exec.jar
然后在浏览器中输入:http://localhost:9411 ,即可打开zipkin首页,看到示例代码上报的效果图如下:
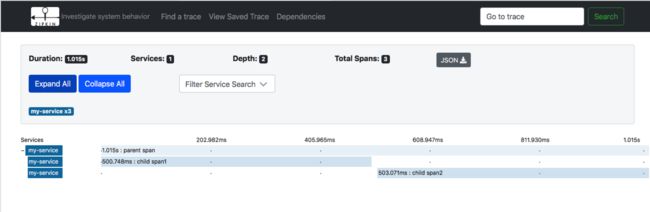
一个最简单的但是却是很完整的一个ZIPKIN链路上报演示,就如上面Demo所示,那么接下来分析一下整个链路的上报过程!
链路上报解析
自己开发一个客户端时,我们首先会封装一个Span类,Brave也不例外,它也定义了Span数据结构;那么定义好Span后,谁来负责构造Span了?
Brave中定义了一个类叫Tracer来完成构造Span的工作;Brave生成好了Span后,此时需要编码发送了,那么谁又来发送了?
Brave定义了Reporter组件,它支持异步发送以及多传输协议以及多编码协议发送Span数据。
看起来,各个组件已经完备了,组件有点多!此时需要那么一个人将这些组件组织起来,同时与服务端取得联系,开始打通整个流程了,这就是Tracing类的功能。
接下来详细讲解一下各个组件的功能,并根据Demo代码,将各个组件串起来,最终梳理清楚Brave上报的流程和原理。
Brave Span
Brave中Span相关类有:SpanCustomizer、NoopSpanCustomizer、CurrentSpanCustomizer、RealSpanCustomizer、Span、NoopSpan、RealSpan。
示例代码中,关于span的操作如下:
Span span = tracer.newTrace().name("encode").start();
try {
doSomethingExpensive();
} finally {
span.finish();
}
首先通过tracer生成一个span,最后,调用span.finish()上报,接下来就来看看span,以及这个finish干了什么。
咱们用的Span的实现子类为RealSpan,RealSpan两个核心方法start, finish:
@Override
public Span start() {
return start(clock.currentTimeMicroseconds());
}
@Override
public Span start(long timestamp) {
synchronized (state) {
state.startTimestamp(timestamp);
}
return this;
}
start方法主要记录开始时间,接下来看看finish 方法:
@Override
public void finish(long timestamp) {
if (!pendingSpans.remove(context)) return;
synchronized (state) {
state.finishTimestamp(timestamp);
}
finishedSpanHandler.handle(context, state);
}
这里交给FinishedSpanHandler来处理。FinishedSpanHandler是一个抽象类,他有如下子类实现:
- ZipkinFinishedSpanHandler
- MetricsFinishedSpanHandler
- NoopAwareFinishedSpan
- CompositeFinishedSpanHandler
我们主要关注ZipkinFinishedSpanHandler实现:
public final class ZipkinFinishedSpanHandler extends FinishedSpanHandler {
final Reporter spanReporter;
final MutableSpanConverter converter;
public ZipkinFinishedSpanHandler(Reporter spanReporter,
ErrorParser errorParser, String serviceName, String ip, int port) {
this.spanReporter = spanReporter;
this.converter = new MutableSpanConverter(errorParser, serviceName, ip, port);
}
@Override public boolean handle(TraceContext context, MutableSpan span) {
if (!Boolean.TRUE.equals(context.sampled())) return true;
Span.Builder builderWithContextData = Span.newBuilder()
.traceId(context.traceIdString())
.parentId(context.parentIdString())
.id(context.spanIdString());
if (context.debug()) builderWithContextData.debug(true);
converter.convert(span, builderWithContextData);
spanReporter.report(builderWithContextData.build());
return true;
}
@Override public String toString() {
return spanReporter.toString();
}
}
可见,上面最终是通过Reporter组件来上报数据的。那么Report是如何上报的了?
Brave Reporter
因为上报组件要支持多种编码协议以及多种传输协议,因此逻辑比较复杂,官方专门建了一个项目:zipkin-reporter-java
我们首先看看Reporter接口类定义:
public interface Reporter {
Reporter NOOP = new Reporter() {
@Override public void report(Span span) {
}
@Override public String toString() {
return "NoopReporter{}";
}
};
Reporter CONSOLE = new Reporter() {
@Override public void report(Span span) {
System.out.println(span.toString());
}
@Override public String toString() {
return "ConsoleReporter{}";
}
};
/**
* Schedules the span to be sent onto the transport.
*
* @param span Span, should not be null.
*/
void report(S span);
}
Reporter有三个子类实现,分别是CONSOLE,NOOP,和AsyncReporter。CONSOLE就是直接控制台打印出Span数据,一般用来调试差不多;NOOP是一个空实现,啥也不干;AsyncReporter是我们平时上报用的Reporter,他提供异步上报数据能力。
AsyncReporter
AsyncReporter is how you actually get spans to zipkin. By default, it waits up to a second before flushes any pending spans out of process via a Sender.
根据不同协议,Ayncreporter执行相应的build逻辑:
public AsyncReporter build() {
switch(this.sender.encoding()) {
case JSON:
return this.build(SpanBytesEncoder.JSON_V2);
case PROTO3:
return this.build(SpanBytesEncoder.PROTO3);
case THRIFT:
return this.build(SpanBytesEncoder.THRIFT);
default:
throw new UnsupportedOperationException(this.sender.encoding().name());
}
}
build方法详细逻辑,如下:
public AsyncReporter build(BytesEncoder encoder) {
if (encoder == null) throw new NullPointerException("encoder == null");
if (encoder.encoding() != sender.encoding()) {
throw new IllegalArgumentException(String.format(
"Encoder doesn't match Sender: %s %s", encoder.encoding(), sender.encoding()));
}
final BoundedAsyncReporter result = new BoundedAsyncReporter<>(this, encoder);
if (messageTimeoutNanos > 0) {
// Start a thread that flushes the queue in a loop.
final BufferNextMessage consumer =
BufferNextMessage.create(encoder.encoding(), messageMaxBytes, messageTimeoutNanos);
Thread flushThread = threadFactory.newThread(new Flusher<>(result, consumer));
flushThread.setName("AsyncReporter{" + sender + "}");
flushThread.setDaemon(true);
flushThread.start();
}
return result;
}
可以看到AsyncReporter的build方法中,启动了一个守护线程flushThread,一直循环调用BoundedAsyncReporter的flush方法:
void flush(BufferNextMessage bundler) {
if (closed.get()) throw new IllegalStateException("closed");
pending.drainTo(bundler, bundler.remainingNanos());
// record after flushing reduces the amount of gauge events vs on doing this on report
metrics.updateQueuedSpans(pending.count);
metrics.updateQueuedBytes(pending.sizeInBytes);
// loop around if we are running, and the bundle isn't full
// if we are closed, try to send what's pending
if (!bundler.isReady() && !closed.get()) return;
// Signal that we are about to send a message of a known size in bytes
metrics.incrementMessages();
metrics.incrementMessageBytes(bundler.sizeInBytes());
ArrayList nextMessage = new ArrayList<>(bundler.count());
bundler.drain(new SpanWithSizeConsumer() {
@Override public boolean offer(S next, int nextSizeInBytes) {
nextMessage.add(encoder.encode(next)); // speculatively add to the pending message
if (sender.messageSizeInBytes(nextMessage) > messageMaxBytes) {
// if we overran the message size, remove the encoded message.
nextMessage.remove(nextMessage.size() - 1);
return false;
}
return true;
}
});
try {
sender.sendSpans(nextMessage).execute();
} catch (IOException | RuntimeException | Error t) {
......
}
}
Flush方法的主要逻辑如下:
- 将队列pending中的数据,提取到nextMessage链表中;
- 调用Sender的sendSpans方法,发送到nextMessage链表中的Span数据到Zipkin;
这样,Reporter即做到了异步发送!
Sender
Sender组件完成发送Span到zipkin服务端的最后一步,即利用某个传输协议,将数据发送到zipkin服务端。
public abstract class Sender extends Component {
public Sender() {
}
public abstract Encoding encoding();
public abstract int messageMaxBytes();
public abstract int messageSizeInBytes(List var1);
public int messageSizeInBytes(int encodedSizeInBytes) {
return this.messageSizeInBytes(Collections.singletonList(new byte[encodedSizeInBytes]));
}
public abstract Call sendSpans(List var1);
}
其中核心的方法sendSpans是一个抽象方法,不同传输协议的Sender会提供具体的实现逻辑,其子类有:
ActiveMQSender、FakeSender、KafkaSender、LibthriftSender、OkHttpSender、RabbitMQSender、URLConnectionSender。
不同协议均按照自身协议规范执行发送逻辑,因为我们的Demo中用的是OkHttpSender,所以我们主要看看OkHttpSender是如何实现的。Demo中使用如下:
Sender sender = OkHttpSender.create("http://localhost:9411/api/v2/spans");
AsyncReporter asyncReporter = AsyncReporter.create(sender);
这里,通过AsyncReporter.create方法,我们将OkHttpSender注入到了Reporter中,那么接下来看看OkHttpSender的sendSpans方法实现:
@Override
public zipkin2.Call sendSpans(List encodedSpans) {
if (closeCalled) throw new IllegalStateException("closed");
Request request;
try {
request = newRequest(encoder.encode(encodedSpans));
} catch (IOException e) {
throw zipkin2.internal.Platform.get().uncheckedIOException(e);
}
return new HttpCall(client.newCall(request));
}
执行完这个方法后,会返回一个HttpCall,Reporter的flush方法中会调用HttpCall的execute方法,完成Http请求发送。
Brave Tracer
Span数据结构,包括发送Span的组件我们搞清楚了,那么谁来负责创建Span了?这就是Tracer的工作,他负责创建Span及提供Span的各种操作,主要方法如下表所示:
| 方法名 | 描述 |
|---|---|
| Span newTrace() | 创建一个Root Span |
| Span joinSpan(TraceContext context) | 公用一个SpanId,主要存在于RPC场景中 |
| Span newChild(TraceContext parent) | 创建一个子Span |
| Span nextSpan(TraceContextOrSamplingFlags extracted) | 基于请求的参数信息创建一个新的Span |
| Span toSpan(TraceContext context) | 通过TraceContext创建一个Span |
| Span currentSpan() | 获取当前Span |
| Span nextSpan() | 基于当前Span生成一个子Span |
Brave Tracing
现在Span有了,创建Span的组件有了,发送Span的组件也有了,那就只需要一个把他们组合起来的类似工厂的角色了,那就是Tracing,他的主要工作就是连接服务器,然后利用Tracer创建出Span,接着发送Span到zipkin服务端。
Tracing源码采用的Builder模式,再看看我们Demo中创建Tracing的代码:
Tracing tracing = Tracing.newBuilder()
.localServiceName("my-service")
.spanReporter(asyncReporter)
.build();
我们Tracing.newBuilder()创建了一个Tracing的Builder,然后指定了这个Tracing的服务名,使用什么Reporter,接着调用了Builder的build方法,我们看看build方法代码:
public Tracing build() {
if (clock == null) clock = Platform.get().clock();
if (localIp == null) localIp = Platform.get().linkLocalIp();
if (spanReporter == null) spanReporter = new LoggingReporter();
return new Default(this);
}
它调用了Tracing的默认实现,默认实现子类如下:
static final class Default extends Tracing {
final Tracer tracer;
final Propagation.Factory propagationFactory;
final Propagation stringPropagation;
final CurrentTraceContext currentTraceContext;
final Sampler sampler;
final Clock clock;
final ErrorParser errorParser;
Default(Builder builder) {
this.clock = builder.clock;
this.errorParser = builder.errorParser;
this.propagationFactory = builder.propagationFactory;
this.stringPropagation = builder.propagationFactory.create(Propagation.KeyFactory.STRING);
this.currentTraceContext = builder.currentTraceContext;
this.sampler = builder.sampler;
zipkin2.Endpoint localEndpoint = zipkin2.Endpoint.newBuilder()
.serviceName(builder.localServiceName)
.ip(builder.localIp)
.port(builder.localPort)
.build();
SpanReporter reporter = new SpanReporter(localEndpoint, builder.reporter, noop);
this.tracer = new Tracer(
builder.clock,
builder.propagationFactory,
reporter,
new PendingSpans(localEndpoint, clock, reporter, noop),
builder.sampler,
builder.errorParser,
builder.currentTraceContext,
builder.traceId128Bit || propagationFactory.requires128BitTraceId(),
builder.supportsJoin && propagationFactory.supportsJoin(),
noop
);
maybeSetCurrent();
}
从上面可以看到,主要干的工作有:
- 根据Spanreporter,生成FinishedSpanHandler,发送Span用;
- 根据FinishedSpanHandler以及其他默认信息生成Tracer;
OK,现在对于DEMO中的Brave的上报数据流程和原理是不是清楚了不少!
链路上报总结
Zipkin链路上报看起来很复杂,其实剥离各种封装,去除各种组件,其主线逻辑就是如下三步:
- 构造span对象,包括traceId,parentId,以及其自身的spanId等参数;
- 选一种编解码协议,比如JSON,或者THRIF,或者PROTO3对Span进行编码;
- 将编码后的span,通过利用一种传输协议上报到服务端;
还有一块未分析:Brave是如何Support各个组件的。因为本文内容较多,放到以后的文章分析!
后记
本文为我的调用链系列文章之一,已有文章如下:
深入探究ZIPKIN调用链跟踪——拓扑Dependencies篇
深入探究ZIPKIN调用链跟踪——存储检索篇
OK,ZIPKIN 链路上报分析到此为止,祝大家工作顺利,天天开心!