像认真记录生活一样记录Bug.
未经允许,不得转载,谢谢~~
1. 从autograd.Variable中取Tensor
- BUG:
RuntimeError: copy from Variable to torch.FloatTensor isn't implemented
这个错误比较简单,就不给完整报错信息了。 - 问题分析:
错误语句:new_output[:,:,i,:,:]=temp2D_output
这里的new_output是Tensor类型,temp2D_output是Variable类型。
所以问题就变成了怎么样从autograd.Variable中取到Tensor - 解决方法:
上图:

这是autograd.Variable的结构图,忘记了可以看看这个
PyTorch入门学习(二):Autogard之自动求梯度
所以直接用Variable.data属性即可。
2. Pytorch的计算类型不匹配问题
- BUG:
Expected object of type torch.FloatTensor but found type torch.cuda.FloatTensor for argument #2 'weight' - 完整报错信息:
Traceback (most recent call last):
File "p3d_model.py", line 425, in
out=model(data)
File "/home/hl/anaconda2/lib/python2.7/site-packages/torch/nn/modules/module.py", line 325, in __call__
result = self.forward(*input, **kwargs)
File "p3d_model.py", line 299, in forward
x = self.maxpool_2(self.layer1(x)) # Part Res2
File "/home/hl/anaconda2/lib/python2.7/site-packages/torch/nn/modules/module.py", line 325, in __call__
result = self.forward(*input, **kwargs)
File "/home/hl/anaconda2/lib/python2.7/site-packages/torch/nn/modules/container.py", line 67, in forward
input = module(input)
File "/home/hl/anaconda2/lib/python2.7/site-packages/torch/nn/modules/module.py", line 325, in __call__
result = self.forward(*input, **kwargs)
File "p3d_model.py", line 166, in forward
out=self.ST_A(out)
File "p3d_model.py", line 120, in ST_A
x = self.bn2(x)
File "/home/hl/anaconda2/lib/python2.7/site-packages/torch/nn/modules/module.py", line 325, in __call__
result = self.forward(*input, **kwargs)
File "/home/hl/anaconda2/lib/python2.7/site-packages/torch/nn/modules/batchnorm.py", line 37, in forward
self.training, self.momentum, self.eps)
File "/home/hl/anaconda2/lib/python2.7/site-packages/torch/nn/functional.py", line 1013, in batch_norm
return f(input, weight, bias)
RuntimeError: Expected object of type torch.FloatTensor but found type torch.cuda.FloatTensor for argument #2 'weight'
从报错信息来看应该是:需要的输入参数类型为torch.FloatTensor,但实际上给定是torch.cuda.FloatTensor
- 错误历程
可以看到出错的语句为:self.bn2(x)
一开始一直以为是自己传入的x类型不符合要求,
def conv2_fyq(self,x):
deep=x.shape[2]
temp2D_output=self.conv2(x[:,:,0,:,:])
new_output=torch.Tensor(temp2D_output.shape[0],temp2D_output.shape[1],deep,temp2D_output.shape[2],temp2D_output.shape[3])
for i in range(deep):
temp2D_input=x[:,:,i,:,:]
temp2D_output=self.conv2(temp2D_input)
print (temp2D_output.shape) # (10, ,160,160)
new_output[:,:,i,:,:]=temp2D_output.data
print (new_output.shape) # (10, ,16,160,160)
# print (new_output)
result=new_output.type(torch.FloatTensor)
# print (result)
result=Variable(result)
return result
x = self.conv2_fyq(x)
x = self.bn2(x) #error
所以一直在修改函数conv2_fyq()函数的返回值,希望从torch.cuda.FloatTensor类型转为torch.FloatTensor,试过很多方法,比如:
result=result.cpu()- 借用
numpy array类型作为中转 - 使用类型转换
result=new_output.type(torch.FloatTensor)
解决方法
首先可以肯定的是由于张量类型不一致导致的;
查了很多资料发现本质是由于两个张量不在同一个空间例如一个在cpu中,而另一个在gpu中因此会引发错误。
print result发现为torch.FloatTensor类型,由此想到出现问题的是nn.BatchNorm3d中其他的参数类型为torch.cuda.FloatTensor.
所以最后的解决方案:将result转为torch.cuda.FloatTensor类型
result=new_output.type(torch.cuda.FloatTensor)参考文献
torch.Tensor类型的构建与相互转换
expected CPU tensor (got CUDA tensor)
PyTorch遇到令人迷人的BUG与记录
这一个小bug的解决也花了近2小时了~
虽然没有直接在参考文献中找到答案,但还是深受启发~
自己解决一个木有现成答案的问题还是挺有意思的哈哈哈哈,心里话是开心都是骗人的,过程最折磨人。
3. 数据集label取值问题
- BUG:
THCudaCheck FAIL file=/opt/conda/conda-bld/pytorch_1512378360668/work/torch/lib/THC/generated/../generic/THCTensorMathPointwise.cu line=301 error=59 : device-side assert triggered - 完整报错信息:
hl@hl-Precision-Tower-5810:~/Desktop/lovelyqian/CV_Learning/pseudo-3d-conv_S$ python P3D_train_fyq.py
hello
[1,1] loss: 4.593
[1,2] loss: 5.070
[1,3] loss: 4.854
[1,4] loss: 4.764
[1,5] loss: 4.807
[1,6] loss: 4.664
[1,7] loss: 4.797
[1,8] loss: 4.802
[1,9] loss: 4.808
[1,10] loss: 4.564
[1,11] loss: 4.509
[1,12] loss: 5.150
[1,13] loss: 4.323
[1,14] loss: 4.779
[1,15] loss: 5.295
THCudaCheck FAIL file=/opt/conda/conda-bld/pytorch_1512378360668/work/torch/lib/THC/generated/../generic/THCTensorMathPointwise.cu line=301 error=59 : device-side assert triggered
Traceback (most recent call last):
File "P3D_train_fyq.py", line 43, in
loss.backward()
File "/home/hl/anaconda2/lib/python2.7/site-packages/torch/autograd/variable.py", line 167, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph, retain_variables)
File "/home/hl/anaconda2/lib/python2.7/site-packages/torch/autograd/__init__.py", line 99, in backward
variables, grad_variables, retain_graph)
RuntimeError: cuda runtime error (59) : device-side assert triggered at /opt/conda/conda-bld/pytorch_1512378360668/work/torch/lib/THC/generated/../generic/THCTensorMathPointwise.cu:301
- 问题分析:
这个问题的错误跟源代码也没有多大的关系,可以直接看到是在用pytorch的backward时候出现了报错信息。
算了,还是贴一下源代码吧~~
#dataset
myUCF101=UCF101()
classNames=myUCF101.get_className()
# print (classNames)
#model
model = P3D199(pretrained=False,num_classes=101)
model = model.cuda()
# print (model)
#loss and optimizer
criterion=nn.CrossEntropyLoss()
optimizer=optim.SGD(model.parameters(),lr=0.001)
#train the network
for epoch in range(2): #loop over the dataset multiple times
running_loss=0
batch_num=myUCF101.set_mode('train')
for batch_index in range(batch_num):
# get the train data
train_x,train_y=myUCF101[batch_index]
# warp them in Variable
# train_x,train_y=Variable(train_x.cuda()),Variable(train_y.type(torch.LongTensor).cuda())
train_x,train_y=Variable(train_x).cuda(),Variable(train_y.type(torch.LongTensor)).cuda()
# set 0
optimizer.zero_grad()
# forward+backwar+optimize
out=model(train_x)
loss=criterion(out,train_y)
loss.backward()
optimizer.step()
# print statistics
running_loss+=loss.data[0]
print ('[%d,%d] loss: %.3f' %(epoch+1,batch_index+1,running_loss))
print >> f, ('[%d,%d] loss: %.3f' %(epoch+1,batch_index+1,running_loss))
running_loss=0.0
从代码来看就很简单的逻辑,就是用常规的思路对网络模型进行数据的输入,梯度清零,计算输出值,计算损失函数,然后反向求梯度并更新。
这个问题没有找到一模一样的情况,但是在下文给出的参考文献中找到了解决思路,即跟label有关。
也发现每一次出现错误信息的时间段不一样,即能成功训练的batch的数目不同,有的时候多,有的时候少。
所以想到把train_y给输出来,多运行几次之后发现每次出错都是在label中出现了101的时候,再回过来考虑这个问题。
本项目用的是UCF101数据集,共有101种类型,所以在读入label的时候自然就根据数据集制作者给出的label进行处理,取值为1-101. 但是PyTorch要求的范围为:0-100
- 解决方法:
101种className, 则正确的数据label范围:0-100 - 参考文献:
pytorch 问题汇总
Pytorch图像分割BUG心得汇总(一)
4.TypeError: only integer scalar arrays can be converted to a scalar index
- BUG:
TypeError: only integer scalar arrays can be converted to a scalar index - 情况说明:
给出相关的源代码
def test(dateset,model,model_state_path):
myUCF101=dateset
model.load_state_dict(torch.load(model_state_path))
classNames=myUCF101.get_className()
# test the network on the test data
batch_num=myUCF101.set_mode('test')
for batch_index in range(batch_num):
batch_correct=0
# get the test dat
test_x,test_y_label=myUCF101[batch_index]
# warp teat_x in Variable
test_x=Variable(test_x.cuda())
# get teh predicted output
out=model(test_x)
_,predicted_y=torch.max(out.data,1)
predicted_label=classNames[predicted_y]
batch_correct+= (predicted_label==test_y_label).sum()
print('bactch: %d accuracy is: %.2f' %(batch_index+1,batch_correct/float(len(test_y_label))))
print >> f, ('bactch: %d accuracy is: %.2f' %(batch_index+1,batch_correct/float(len(test_y_label))))
print ('Test Finished')
主要看这两行:
out=model(test_x)
_,predicted_y=torch.max(out.data,1)
predicted_label=classNames[predicted_y]
out是我取到的分类值; predicted是最有可能的label集合;classNames是具体的label。
- 错误分析:
1. 首先把predicted_y由cuda的longTensor改成numpy格式的。
predicted_y=predicted_y.cpu().numpy()
- 然后还是不行,就把predicted_y打印出来,发现是np.ndarray形式的,猜测可能需要转换为np.array()。
例如:
predicted_y=np.array(predicted_y,dtype=np.uint8)
这样依然没有解决问题,且网上提供的很多解决方案例如predicted_y=predicted_y.flatten()将多维数组转为展开成一维数组都行不通。
3. 既然提示需要直接使用np.array,所以我就定义了 a=np.arange(8),来测试classNames[a],发现还是一样的错误。到这里就觉得已经不是下标的问题了,所以才想到是不是classNames的问题。
然后才想到classNames不是array,而是list。所以我就将classNames做了一个从array到list的类型转换。
classNames=np.array(classNames)
到这里就就决问题了。
- 解决方法 :
# cuda.longTensor to numpy.array
predicted_y=predicted_y.cpu().numpy()
# ndarray to array
predicted_y=np.array(predicted_y,dtype=np.uint8)
# list to array
classNames=np.array(classNames)
总结来说,TypeError: only integer scalar arrays can be converted to a scalar index这个问题可以从下标和数组这两个对象来看,都需要是np.array类型的。
5.DataLoader处理数据集时候的数据问题
- BUG:
RuntimeError: invalid argument 2: cannot unsqueeze empty tensor at /opt/conda/conda-bld/pytorch_1512378360668/work/torch/lib/TH/generic/THTensor.c:601 - 完整报错信息:
Traceback (most recent call last):
File "UCF101_pytorch_fyq.py", line 182, in
for i_batch,sample_batched in enumerate(dataloader):
File "/home/hl/anaconda2/lib/python2.7/site-packages/torch/utils/data/dataloader.py", line 210, in __next__
return self._process_next_batch(batch)
File "/home/hl/anaconda2/lib/python2.7/site-packages/torch/utils/data/dataloader.py", line 230, in _process_next_batch
raise batch.exc_type(batch.exc_msg)
RuntimeError: Traceback (most recent call last):
File "/home/hl/anaconda2/lib/python2.7/site-packages/torch/utils/data/dataloader.py", line 42, in _worker_loop
samples = collate_fn([dataset[i] for i in batch_indices])
File "/home/hl/anaconda2/lib/python2.7/site-packages/torch/utils/data/dataloader.py", line 116, in default_collate
return {key: default_collate([d[key] for d in batch]) for key in batch[0]}
File "/home/hl/anaconda2/lib/python2.7/site-packages/torch/utils/data/dataloader.py", line 116, in
return {key: default_collate([d[key] for d in batch]) for key in batch[0]}
File "/home/hl/anaconda2/lib/python2.7/site-packages/torch/utils/data/dataloader.py", line 96, in default_collate
return torch.stack(batch, 0, out=out)
File "/home/hl/anaconda2/lib/python2.7/site-packages/torch/functional.py", line 62, in stack
inputs = [t.unsqueeze(dim) for t in sequence]
RuntimeError: invalid argument 2: cannot unsqueeze empty tensor at /opt/conda/conda-bld/pytorch_1512378360668/work/torch/lib/TH/generic/THTensor.c:601
- 错误分析:
这个问题大概可以看出来是DataLoader的问题,但是使用框架的时候具体到哪个函数,哪行代码就会比较麻烦。看报错信息的最后一行应该可以知道是空的Tensor引起的。
我们不用DataLoader的情况下,输出数据样本:
print (len(myUCF101))
for i in range (5):
sample=myUCF101[i]
print(sample['video_x'].size(),sample['video_label'])
得到如下所示:

可以看到与video_label会有关系。
- 解决方法:
超级感谢这篇资料的引导了:# Cannot Unsqueeze Empty Tensor
确实是由于video_label是标量引起的,最后做了改动,具体如下所说:
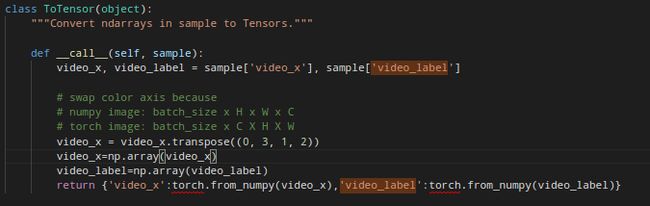 错误
错误
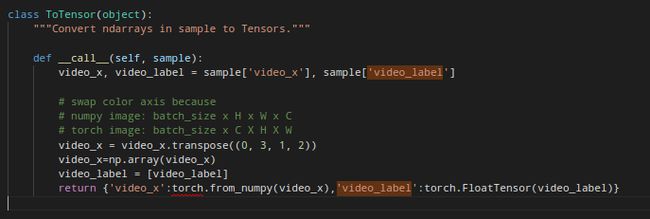
----------20180806更新----------
6. RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation
- BUG:RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation
- 完整报错信息:
/home/fuyuqian/anaconda3/lib/python3.6/site-packages/torchvision-0.2.1-py3.6.egg/torchvision/transforms/transforms.py:188: UserWarning: The use of the transforms.Scale transform is deprecated, please use transforms.Resize instead.
Traceback (most recent call last):
File "/home/fuyuqian/Projects/Temporal_Deformable_P3D/network_train.py", line 88, in
myTrainClassifier.train_network()
File "/home/fuyuqian/Projects/Temporal_Deformable_P3D/network_train.py", line 59, in train_network
loss.backward()
File "/home/fuyuqian/anaconda3/lib/python3.6/site-packages/torch/tensor.py", line 93, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File "/home/fuyuqian/anaconda3/lib/python3.6/site-packages/torch/autograd/__init__.py", line 89, in backward
allow_unreachable=True) # allow_unreachable flag
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation
- 错误分析:由于pytorch升级到pytorch0.4之后,与之前pytorch0.3的用法发生来了一些变化,比如最重要的在pytorch0.4中将Tensor与Variance都组合成了同一个东西,pytorch0.4不再支持inplace操作。
- 解决方法:基本网上我能看到的所有资料,可执行的方案主要有以下几点:
- 解决方案1:把所有的
inplace=True改成inplace=False - 解决方案2:将
out+=residual这样所有的+=操作,改成out=out+residual - 解决方案3: 将pytorch版本回退到0.3,或者添加一个pytorch0.3的conda环境。
此类问题的一点总结:以上的方案1与方案2其实都是在解决pytorch0.4不能处理inplace操作的问题。但是其实都不全。
举个简单的例子来理解一下inplace=True与inplace=False,就像所有的博客里给出的+=这个操作。x+=1是在x的基础上直接做加法操作的,这个就属于在原来的x上做扩展,是inplace=True的情况。而x=x+1就是先做加法,然后重新赋值,就是inplace=False。
但是我们要注意到+=只是inplace的一种操作,并不是把所有的+=替换掉就可以解决问题的。在这篇博客pytorch 学习笔记(二十二):关于 inplace operation中给出了完整的说明,非常建议看看。
总结一下:如果你的程序比较简短,情况比较简单,那么就直接改里面的+=这样的inplace操作。另外在修改的时候可以用variance.backward()来试试这个variance之前的代码是不是都已经正确了。 如果代码量比较大,那还是建议用conda再创建一个环境,用来安装pytorch0.3,简单省事。
- 创建一个名为
pytoch0.3的conda环境:conda create -n pytorch0.3 python=3.6; - 激活
pytorch0.3环境:source activate pytorch0.3,这时中断提示符前面会多一个pytorch0.3标记; - 要关闭
pytorch0.3环境,就用:source deactivate; - 在里面用conda安装0.3版本的pytorch:先在官网下载对应的版本
torch-0.3.1-cp36-cp36m-linux_x86_64.whl,进入目录用pip install torch-0.3.1-cp36-cp36m-linux_x86_64.whl命令安装pytorch,然后再用pip install torchvision安装torchvision。
7. 关于网络测试时候显卡溢出的问题
- 问题描述:我写了一个网络,用同样的BATCH_SIZE对模型进行训练没有问题,但是进行测试就会溢出。
- 问题思考: 在数据加载以及网络模型一样的前提下,分类任务的test只需要计算前向传播得到精度即可,都不需要梯度返回的过程,应该网络参数的大小比训练的时候要小才对。
- 问题解决: 在测试时候加上:
with torch.no_grad():语句即可。 - 原因分析:推断是测试的时候没有对网络参数的梯度进行优化。(未验证)
8. 关于同一个模型在测试时得到的结果不同--model.train()与model.eval()
- 问题描述:同样的一个网络结构,在多次测试的时候发现得到的结果会不一样。
- 问题思考: 一样的网络结构,一样的数据,排除数据加载中存在随机裁剪这样的问题之后就觉得这种情况一定是不合理的。
- 问题解决:如果你的网络中有BN层或者dropout层,那么就需要在测试的实时候加上语句
model.eval(),默认情况下是train()模式的,这样就不会出现上述的问题; - 原因分析: BN在训练时是根据mini_batch中的样本来得到均值和方差的,但是在test的时候我们需要的是对每个样本进行预测,所以取固定的均值和方差就可以了。而dropout则只是train的时候为了防止过拟合而用的,test的时候并不需要这一层。
----------20181117更新----------
9 关于cuda out of momery问题
- 问题描述:当需要用同一个网络对很多的输入进行计算输出的时候,可能会出现所有的变量都留在gpu中导致显卡溢出。
- 问题解决:将计算完之后的结果移到内存中,例如我想到的是网络输出的某一个
feature值,那么就用feature.cpu().detach()的方式将它移到内存中保存。
----------20190215更新----------
10. 关于多线程出现错误问题
- 问题描述:
当我用pytorch自带的dataloader多线程读取数据时,如果对读出的数据使用append()方法,会出现内存错误,程序异常终止的问题; - 相关代码:
trainloader_single = DataLoader(trainset,batch_size=1,shuffle=False,num_workers=NUM_WORKERS)
image_features=[]
image_labels=[]
for i, data in enumerate(trainloader_single):
# get the inputs
inputs, labels = data
inputs, labels = inputs.numpy(), labels.numpy()
img_feature = inputs.reshape(inputs.shape[1:])
img_label = labels[0]
print(i,img_feature.shape, img_label)
image_features.append(img_feature)
image_labels.append(img_label)
只要出现最底下的这两行append语句,就会出错。
- 解决方法:
最简单的方法就是直接改成单线程,但是我一直以为是设置num_works=1即可。
事实是需要将它设置为0:num_works=0来达到disable multi-processing的效果。
----------20190225更新----------
11. 关于多次网络交替求导的问题
- 问题描述:网络中存在多个sub-network,有2个甚至2个以上的loss需要分别对网络参数进行更新。(不是loss = loss1 + loss2这种情况),而是两个需要分别执行
loss1.backward()loss2.backward(). - 问题所在:两个loss可能会有共同的部分,所以在执行第一次
loss1.backward()完成之后,Pytorch会自动释放保存着的计算图,所以执行第二次loss2.backward()的时候就会出现计算图丢失的情况; - 错误信息:
RuntimeError: Trying to backward through the graph second time, but the buffers have already been freed. Please specify retain_variables=True when calling backward for the first time.
- 解决方法:
- 执行
loss1.backward(retain_graph=True)保留计算图; - 如果你不希望两次的梯度叠加,那么执行一次
net.zero_grad(); - 执行
loss2.backward() - 根据自己的情况对网络分别定义
optimizer,进行step()梯度更新;
- 参考资料:
- 推荐:https://blog.csdn.net/u011276025/article/details/76997425
- https://discuss.pytorch.org/t/runtimeerror-trying-to-backward-through-the-graph-a-second-time-but-the-buffers-have-already-been-freed-specify-retain-graph-true-when-calling-backward-the-first-time/6795
12. TypeError: unhashable type: 'numpy.ndarray'
- 问题描述:在将pytorch的longTensor转为numpy,并用于dict的key的时候,会出现这样的错误。其实程序输出已经是int了,但是还是会被认为是ndarray。
- 问题解决: 在原来的基础上加上
.item()
# classId = support_y[i].long().cpu().detach().numpy()
classId = support_y[i].long().cpu().detach().numpy().item()
13. from torch._C import * ImportError: numpy.core.multiarray failed to import
- 问题描述: 在新的虚拟环境Python=2.7中重新安装的pytorch,导入的时候会有问题。
- 错误信息:
>>> import torch
Traceback (most recent call last):
File "", line 1, in
File "/home/fuyuqian/anaconda3/envs/cmr/lib/python2.7/site-packages/torch/__init__.py", line 84, in
from torch._C import *
ImportError: numpy.core.multiarray failed to import
- 问题解决:
- 执行多次
pip uninstall numpy直到系统提示没有安装numpy; - 重新用
pip install numpy -U命令安装numpy; - 然后就可以正常导入torch了。
- 参考资料:https://github.com/pytorch/pytorch/issues/2731