1、
使用 turtle 库的 turtle.fd() 函数和 turtle.seth() 函数绘制一个等边三角形,边长为 200 像素,效果如下图所示。请结合程序整体框架,根据提示代码完成程序。
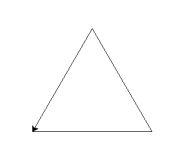
提示代码:
import turtle
d = 0
for i in range(____①____): turtle.fd(____②____) d = d + 120 turtle.seth(____③____)
import turtle as t
d = 0
for i in range(3):
t.seth(d)
d = d + 120
t.fd(200)
2、
请编写程序,生成随机密码。具体要求如下:
(1)使用 random 库,采用 0x1010 作为随机数种子。
(2)密码 abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890!@#$%^&* 中的字符组成。
(3)每个密码长度固定为 10 个字符。
(4)程序运行每次产生 10 个密码,每个密码一行。
(5)每次产生的 10 个密码首字符不能一样。
(6)程序运行后产生的密码保存在“随机密码.txt”文件中。
import random
random.seed(0x1010)
initial = "" #存放首字母
ls = [] #存放密码
while len(ls) < 10:
ret = ""
for i in range(10):
res = random.choice("abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890!")#从该字符串随机选一个
ret = ret + res
if ret[0] in initial: #如果该密码的首字母在首字母仓库存在
continue
else:
ls.append(ret)
initial += ret[0]
secret = '\n'.join(ls)
print(secret)
with open("随机密码.txt", "w", encoding = "utf_8") as f:
f.write(secret)
3、
根据输入正整数 n,作为财务数据,输出一个宽度为 20 字符,n 右对齐显示,带千位分隔符的效果,使用减号字符“-”填充。如果输入正整数超过 20 位,则按照真实长度输出。提示代码如下:
n = input()
____①____ #可以多行
输入输出示例
| 输入 | 输出 | |
| 示例 1 | |
|
n = input() # 请输入整数
print("{:->20,}".format(eval(n))) #数字格式化知识
4、
PyInstaller 库可以对程序打包,给定一个 Python 源程序文件 a.py,图标文件为 a.ico,将其打包为在 Windows 平台上带有上述图标的单一可执行文件,使用什么样的命令?
pyinstaller –i a.ico –F a.py
5、
使用 turtle 库的 turtle.right() 函数和 turtle.fd() 函数绘制一个菱形四边形,边长为 200 像素,效果如下图所示。请勿修改已经给出的第一行代码,并完善程序。
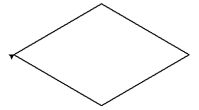
提示代码:
import turtle as t
#自己的思路
import turtle as t
d = 330
for i in range(1,5):
if i % 2 != 0:
t.seth(d)
d = d + 60
t.fd(200)
else:
t.seth(d)
d = d + 120
t.fd(200)
#答案
import turtle as t
t.right(-30)
for i in range(2):
t.fd(200)
t.right(60*(i+1))
for i in range(2):
t.fd(200)
t.right(60*(i+1))
6、
苏格拉底是古希腊著名的思想家、哲学家、教育家、公民陪审员。苏格拉底的名言部分被翻译为中文,部分内容分词结果由考生目录下文件 sgldout.txt 给出。对文件 sgldout.txt 进行分析,输出词频排名前五的词 (不包括中文标点符号) 和次数到 sgldstatistics.txt。
参照输出格式如下:
了:234
了:234
了:234
了:234
了:234
答案:
fo = open("sgldout.txt","r",encoding ="utf-8")
words = fo.readlines()
fo.close()
sym = ";。,“”: "
DictWords = {}
for ls in words:
if ls[:-1] not in sym: #学习一下
DictWords[ls[:-1]] = DictWords.get(ls[:-1], 0) + 1 #学习一下
L = list(DictWords.items())
L.sort(key = lambda s:s[1],reverse=True)
# 输出到文件
fo = open("sgldstatistics.txt", "w", encoding="utf-8")
for i in range(5):
fo.writelines(L[i][0] + ":" + str(L[i][1]) + "\n")
fo.close()
# print 输出
for i in range(5):
print(L[i][0] + ":" + str(L[i][1]))
7、
从键盘输入一个由 1 和 0 组成的二进制字符串 s,转换为十进制数输出显示在屏幕上,示例如下:
输入
请输入一个由 1 和 0 组成的二进制数字串:1101
输出
转换成十进制数是:13
s = input() # 请输入一个由1和0组成的二进制数字串:
d = 0
while s:
d = d + eval(s[0]) * pow(2, (len(s)-1))
s = s[1:]
print("转换成十进制数是:{}".format(d))
8、
使用 turtle 库的 turtle.circle() 函数和 turtle.seth() 函数绘制套圈,最小的圆圈半径为 10 像素,不同圆圈之间的半径差是 40 像素。效果如下图所示。
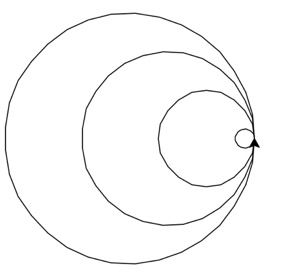
import turtle
r =10
head = 90
for i in range (4):
turtle.seth(90)
turtle.circle(r,360)
r = r +40
9、
从键盘输入一个中文字符串变量 s,内部包含中文逗号和句号。
问题1:(8分)计算字符串 s 中的中文字符个数,不包括中文逗号和句号字符。示例如下:
输入:
没有人不爱惜他的生命,但很少人珍视他的时间。
输出:
中文字符数为20。
问题2:(7分)用 jieba 分词后,显示分词的结果,用”/”分隔。并显示输出分词后的中文词语的个数,不包含逗号和句号。示例如下:
输入:
没有人不爱惜他的生命,但很少人珍视他的时间。
输出:
没有/ 人/ 不/ 爱惜/ 他/ 的/ 生命/ 但/ 很少/ 人/ 珍视/ 他/ 的/ 时间/
中文词语数为14
import jieba
s = input("请输入一句中文:")
s = s.replace(",","").replace("。","")
l2 = jieba.lcut(s)
print("/".join(l2))
# print(li)
print("中文词语数为:{}".format(len(l2)))
print("\n中文字符数为{}。".format(len(s)))
程序实现
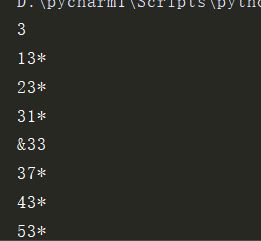
打印出1~1000之间包含3的数字:
如果3是连在一起的(如233)则在数字前加上&; .
如果这个数字是质数则在数字后加上*
li = []
for i in range(3,1001):
if i == 3:
print(3)
elif "3" in str(i):
li.append(int(i))
for j in li:
tag = 0
for k in range(2,j):
if j % k ==0:
tag = 1
if tag == 0:
print(str(j)+ "*")
elif "33" in str(j):
print("&"+str(j))
#精简之后
for i in range(3,1001):
if i == 3:
print(3)
elif "3" in str(i):
tag = 0
for k in range(2,i):
if i % k ==0:
tag = 1
if tag == 0:
print(str(i)+ "*")
elif "33" in str(i):
print("&"+str(i))