开篇之前,我们来说说Git这个东西。至于Git是个什么东西这种问题,我相信不用我说,点开这篇文章的你应该知道的。但是这里,我也不赶尽杀绝,用一句简单粗暴的概念简单介绍一下 :
Git,是一个版本管理工具。
那么关于Git的基本使用和一些基础概念,这里不是本文讨论的重点。本文也不是一篇Git的科普文,教你Git怎么用啊,环境怎么搭建啊,用Git有什么好处啊…..这种问题。如果你有这种问题,请关闭此页面,在浏览器地址栏输入http://www.google.com/
Good Luck~
作文初衷
恩…接触Git有些时日。大大小小的项目也做了不少,基本都是用Git在做代码管理。
在多人协作开发的时候,最最频繁的操作就是merge了。简单方便快捷。直到遇到一家对Git提交规范严格的公司——要求使用rebase来替代merge操作。
恩,基于这个原因,就去熟悉原本不怎么熟悉的rebase命令。过程中,踩了不少坑,走了不少弯路,特写下这篇文章,希望能对后来者有所帮助。
本文内容不深,会从实际的操作和例子出发,旨在为各位看官弄明白git rebase命令的各种相关的问题。
一般的Git协作流程
说是一般的,其实只是我本人见过的一些项目以来的Git的管理的流程。见识有限,给大家分享的,只是我实践过可行性比较好的方案。各位看官看完后可以做个参考,有什么不对的或者疑问,欢迎联系我,或者留言评论,先行谢过~~~
一个成规模的项目一般的Git的分支结构应该是这样:
master //对应线上产品的代码版本
dev //开发总分支
module1 //新feature分支
module2 //新feature分支
....
master :这个分支主要对应的线上的产品的代码,如果APP上线后收到反馈,出现了Bug,需要立马修复,那么基于这个分支新建一个新的分支去解决Bug。总之,这个分支总是映射现在的项目的线上的代码,正常情况下只合并dev上的代码。
dev:总的开发分支。当开发新版本的时候,细分的每个feature,都会去基于这个分支去新建一个分支,然后再去开发。
module:具体的功能分支。
新版本的开发应该是先由dev分支牵出各种module分支,各个module分支先后完成后再merge到dev分支(当然,这当中涉及到code reviewer之类的流程)。最终是从dev分支上打包测试。没有问题之后再merge到master上。恩,至少之前我就是这么干的。
merge 和 rebase简述
用过git的话应该都知道,git的世界里,分支是一个很基础的概念。可以让你在不干扰现有版本的情况下去做你想做的事情,事情做完之后再合并回你的主分支。
那么分支和分支之间的合并,也就是我们经常会用到的merge命令。
当你有两个分支,一个主分支master(当然,你可以叫任何名字),一个从master上牵出来的子分支branchA。当你想要将branchA的改动合并到master上时,你大概需要用如下两个命令:
git checkout master // 将当前分支切换到master分支
git merge branchA //合并branchA分支
那么,除了merge我们知道是合并之后,今天介绍另外一种合并的方式,上面的命令也可以这么写:
git checkout master // 第一步一样,切换到master分支
git rebase branchA //合并branchA分支
将上面的merge替换成rebase就好啦。然后你将看到,两种方式最后产生的结果并无区别,两个分支的内容确实合并在了一起。
合并的过程中可能会有冲突,这个时候需要你去手动解决冲突再次提交。
无论是merge还是rebase,都是一个主动的操作。
当你需要合并另一个分支的时候,就会将你要合并的分支(目标分支),合并到你当前所在的分支。
merge 和rebase 使用对比
rebase命令在中文的Pro.Git-zh_CN.pdf 中文手册中,翻译成衍合。乍一看不怎么好理解。
在一些我使用的git图形化工具软件的时候,rebase翻译成变基(比如本人使用的SourceTree)。

就真的不怕人想歪么….所以,更加不好理解。
那么rebase到底怎么理解呢?它跟merge又有什么区别?
先回答第二个问题,rebase和merge的作用都一样,能帮助你在当前分支合并另一个分支的内容。他们唯一的区别体现在这个分支的提交历史上。我们知道,你的每次一个commit,每一次merge都会在git的版本历史(版本树)中有明确的记录,像是脚印一样,这样方面我们浏览这个版本的前世今生。
rebase的操作会让你的版本一直保持一个比较干净的线性结构往下发展,而merge不会。
merge
好的,我们来写一个例子:
首先,我们在本地的一个随便找一个文件夹新建一个git仓库,恩…文件夹的名字就叫test好了。
git init
然后,我们先做一次提交,提交内容,我们随便新建一个文件
vi a.txt
git add *
git commit -m "first commit"
执行完上面的命令如果不出意外的话,这个工程如果使用你的第三方图形化工具来看的话,应该是这样(我这里用的是SrouceTree):
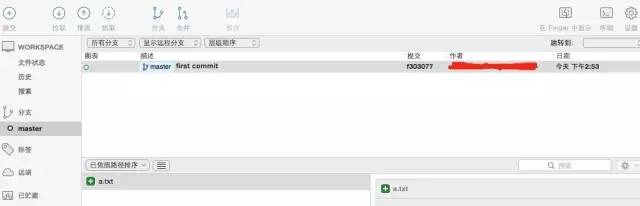
默认帮你创建了一个master分支,并且这个分支上有你的一个提交历史。
接下来,我们新建一个分支test,并且在这个分支上新建一个文件b.txt,然后提交,如果不出意外,你会得到这样:
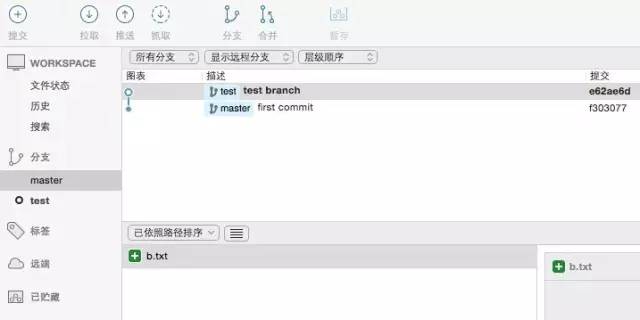
之后,我们分别在各自两个分支上做几次各自不同内容的提交,让两个分支的差异越来越大 :

恩,我们先在test分支上提交了一次,内容是
update b.txt
然后我们切回master分支,分别前后做了两次提交,内容分别是
update a.txt
create c.txt
OK ,那么现在的情况就是,master上有a.txt、c.txt两个文件。test分支上有a.txt(test从master新牵出的时候,就带了a.txt)、b.txt两个文件。
好的,现在我们按照传统的方式merge来将两个分支合并,看看结果怎么样:
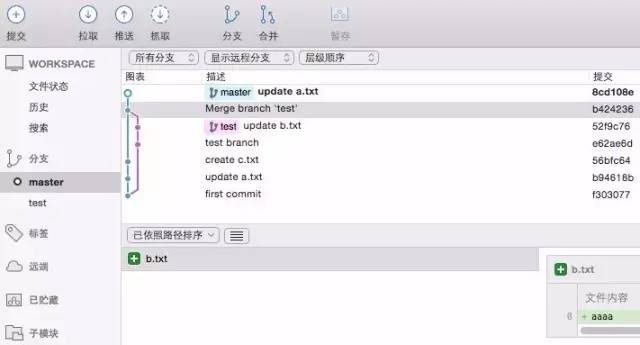
我们先在从master分支上执行了merge命令,合并了test分支上的内容,继而又继续提交了一次更新,更新内容为
update a.txt
以上,就是一个简单的merge操作的流程,经历了那么多的操作后,回顾整个版本库的提交历史可以发现,出现了两条线,一条蓝色(master)、一条红色(test)。
并且由于merge的操作,这两条分支存在两个交点,一个是从test牵出来的时候跟master产品的交点,一个是由merge操作,同master产生的交点。
rebase
好的,还是刚刚那个demo,让我们用rebase的方式来比较一下区别。
我们新建一个分支,叫做rebaseDemo,并且在这个新分支上做一些提交:

我们先在rebaseDemo上做了两次提交,一次新建了一个d.txt文件,一次修改了d.txt文件。
然后切换回master,做了一次提交,新建了一个e.txt文件。
先在我们执行一下rebase操作,看看会发生什么:
git checkout master // 切换回master
git rebase rebaseDemo // 执行rebase命令

当我们运行完rebase命令后再回去看我们发现,整个版本树的分支只保留了一条,也不会出现第二条分支,更别说分支交错的情况了。那我们来看看master上的内容:

确实合并了rebaseDemo中新建的文件d.txt。从结果出发,无论是merge还是rebase达到的效果其实是一致的。
小结
从结果来看,我们对比一下两个种方式产生的结果:

一目了然,使用rebase衍合操作更能产生干净的、线性的、可读性高的文件版本树。这对于文件的管理是非常有帮助的。
所以,当协作人员过多的时候,使用rebase来替换掉merge其实是有好处的。
如果你只是想弄懂merge和rebase有什么区别的话,那么看到这里,其实能够解答你的这个问题了。
如果你跟笔者一样,对这里面的原理有一些好奇心的话,那么不妨继续看下去,笔者将深入对里面的实现一一分析,引入自己的问题和看法。
深入细节
假设这是我们的一个版本树:
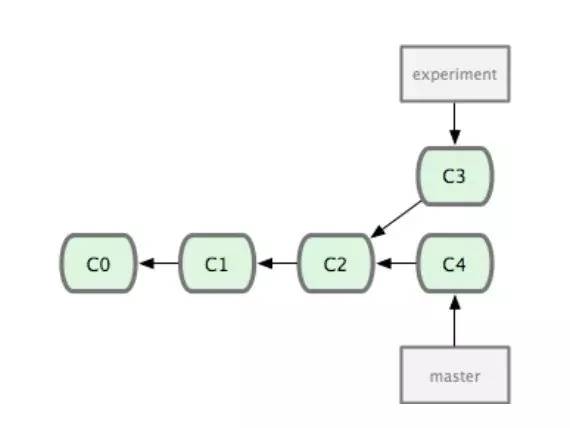
merge命令,它会把两个分支最新的快照(C3和C4)以及二者共同的祖先(C2)进行三方合并,达到整合分支的目的。像这样:
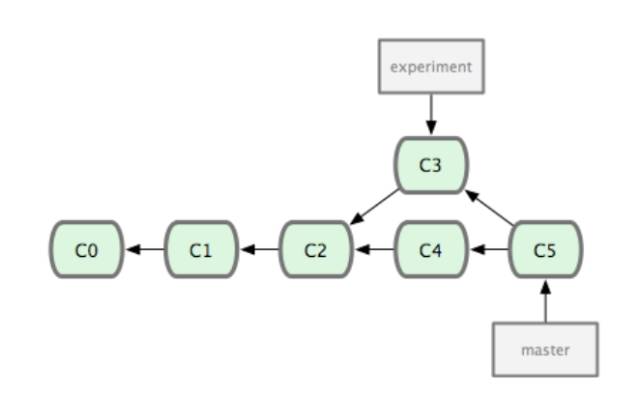
如果C4想要整合C3的分支,那么通过rebase的方式,其实就是C3里产生的变化的补丁重新在C4的基础上打一遍,相当于C3中提交的变动在C4中重新重新执行了一遍。
rebase会回到两个分支(当前所在的分支和你想要rebase的分支)的共同祖先,提取当前所在分支每次提交时产生的差异(diff),把这些差异分别保存到临时文件里,然后从当前分支转到你需要rebase的分支,依次序的使用每一个差异补丁文件。像这样 :

git rebase master // master 这里是C4
这个时候C3的分支处整个版本树的最前面,master落后一个版本,这个时候如果想让master保持最新的版本库内容,你需要切换回master分支并且执行
git merge [C3 branch name]
但是这个时候的merge其实只是把当前的[HEAD]指针往前移了一个单位而已,并没有做任何合并的动作,这种合并,一般称之为快进合并。
另外一种方式就是,当前分支是master,并且在master上执行了rebase其他分支的操作,这个时候如果rebase成功,则master分支就会领先目标分支一个版本。
但是在实际开发流程中,master一般不被允许这样直接去整合另外的分支。所以实际操作中,还是使用第一种方式。
还要merge做什么?
我们知道merge和rebase的区别,也知道使用rebase的种种好处,但是我们的还是要思考一个问题:
“rebase好处这么多,那是不是可以替代merge了?以后一直用rebase就好了。
如果你这样想,那就真的是too young too naive了。”

存在必定有它的道理,不然人家干吗弄两个命令出来。
事实上,在使用rebase的时候我们的遵循这样一个原则:
永远不要rebase那些已经推送到公共仓库的更新。
在rebase的时候,实际上抛弃了一些现存的commit而创造了一些类似但是不同的新的commit。如果这些commit推送到服务器上,你的小伙伴pull下来并在这个基础上进行开发并提交了新的commit,然后你用rebase重写这些commit再推送一次,你的小伙伴就不得不重新合并他们的工作,这样会对别人的理解造成困扰。
举个栗子:
新加入一个项目组,老大给了你项目的git地址。毫无疑问,第一步就是把项目clone到本地,然后你对这个本地仓库做了一些新的功能并且暂时提交到了本地:

总共提交了两个commit到你的本地(C2和C3)。
那么在你开发的时候,团队其他的小伙伴也在同时做着另外的开发,并且将这些改动合并提交到了服务器上。然后通知你,服务器上有些改动,你更新一下:

服务器上被其他小伙伴更新到了C6。
这个时候你本地还是基于C1更新到了C3。
这个时候你合并服务器的版本产生了C7。
看上去一切正常。但是如果这个时候,你的小伙伴觉得他之前的提交用的是merge,觉得稍微有些不妥,准备用rebase替换掉服务器上的提交历史,让提交历史看上去更友好:
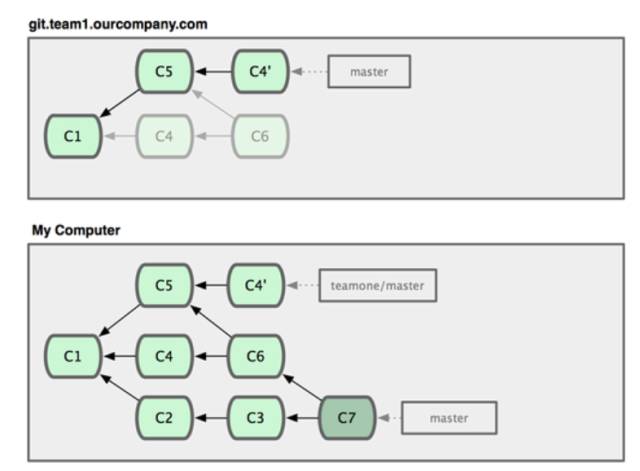
服务器上的提交用rebase覆盖了之后变成了C4。
这个时候对于你来说,需要再次合并这个新内容——即使内容没有什么改变。rebase会改变那些commit的SHA-1校验值,这样Git会把它们当做新的commit(尽管你的本地早已有了C4的内容)。
为了保持代码同步,你迟早需要并入其他小伙伴提交的内容。上面这种情况会让你的本地的提交历史里面同时出现C4和C4‘,这两个commit有不一样的SHA-1校验值,但却拥有同样的作者、日期和commit说明。这就是问题,这样的提交历史如果提交到了服务器,别的人再去合并你的代码到他们自己本地的电脑上,则每个人都会有这样一个莫名的提交。
关于rebase的使用,我们更应该把它当成一种在提交到服务器之前清理本地提交历史的手段,而不当成合并的唯一手段。
sourceTree使用rebase
容笔者啰嗦一下关于sourceTree的一些使用。英文好的可以移步去这个网址看一下。
Interactive rebase in SourceTree
写在最后
讲真,非常感谢屏幕前你的看完这篇冗长的文章。写的东西有人看,认真的看,没有什么比这个更欣慰的了。

关于rebase就讲到这里啦。总的来说是啰嗦了一点,但是笔者认为还是很有必要的。
很多时候,我们评价一段好的代码,看的是它的健壮性,可维护性,可拓展性…..
那么同样,一个优秀的工程师也是方方面面的,做项目不同于写demo,追求团队的效率,优化整个团队的工作习惯,正是作为一个团队成员,从这种一点一滴的小事去理解,去分享的。
本文作者:梁紫枫(点融黑帮),江湖诨名疯子。来自点融Clients团队。喜欢打扫房间和健身的巨蟹座男子。