g711原理pcm转alaw,pcm转ulaw,alaw转pcm,ulaw转pcm
本文参考
https://www.jianshu.com/p/512ce6566f8a g711编码原理
https://www.zhihu.com/question/53527092 量化与采样
关于二进制的基础知识
数与二进制
数
人们最开始数数用手指来算,人有10个手指头,所以用十进制代表人类常用的进制。十进制的个位能表示0~9共10种状态,9再加1,个位就会往前进1进到十位,十位变1,个位变0…代表10.
十位也能表示0~9,共10种状态,那么两位数一共能表示10 × 10 = 100种状态(0~99)
二进制基础:
二进制数在计算机中按位存储,逢2进1。
1位的二进制数能表示的状态有0 1 ===== 2种 = 2^1
2位的二进制数能表示的状态有00 01 10 11 ===== 4种 = 2^2
3位的二进制数能表示的状态有000 001 010 011 100 101 110 111 ===== 8种 = 2^3
由此可推出、
n位的二进制数能表示的状态有 ==== 2^n种
二进制数的计算机表示:分两种,有符号和无符号
无符号的二进制数在计算机中的表示都是正的。
例如: 4bit的无符号二进制数
0000 = 0
0001 = 1
0010 = 2
0011 = 3
0100 = 4
0101 = 5
0110 = 6
0111 = 7
1000 = 8
1001 = 9
1010 = 10
1011 = 11
1100 = 12
1101 = 13
1110 = 14
1111 = 15
共16种状态。
有符号的二进制数在计算机中的表示有正有负
例如: 4bit的有符号二进制数
0000 = 0
0001 = 1
0010 = 2
0011 = 3
0100 = 4
0101 = 5
0110 = 6
0111 = 7
1000 = -8
1001 = -7
1010 = -6
1011 = -5
1100 = -4
1101 = -3
1110 = -2
1111 = -1
共16种状态。正数是从0~7,负数从-1~-8
·「问题:」为什么1001是-7?符号位 = 1表示负数,那么1001不应该是-1么?
我们都知道+1 加 -1应该等于0,
如果1001 = -1,那么1001 + 0001 == 0 么?
显然不等于。
0001 + 1111才等于0
所以1111 = -1。而1001 = -7.
规定: 1 Byte(字节) = 8 bit(比特位)
为什么一个字节是8位?这个问题一般都是历史原因,感兴趣的可以上网去查一查,网上的说法有很多种。
关于计算机的进制:1GB = 1024MB = 1024 × 1024KB = 1024 * 1024 * 1024 B = 8 * 10243 bit
数字音频信号处理
数字音频处理概念
数字音频处理要做的大方向是把我们所听到的声音以数字的方式记录下来,让计算机进行处理。
先来简单说说声音这部分:
此时此刻你所能听到的动静就是声音,,这个声音是通过我的声带震动产生的,你之所以能听到是因为我的声带震动迫使着空气震动,声音在空气中以波的形式传播,空气震动迫使你的耳骨膜震动,从而听到声音。
怎么记录声音?
既然震动耳骨膜能让人听到声音,那么我们就用某个物体来模仿我们的耳骨膜来接收声音。例如:留声机中的振片就相当于人类的耳骨膜。
我们把振片接收的声音通过AD变换器转变为数字信号。
AD变换器(analogue digital) 模拟数字
模拟信号到数字信号分为3部:采样,量化,编码
采样:声音的模拟信号是一段连续的波形,数字信号是对波形进行采样得到的(采样:采集样本),一个点表示一个样本,采样所取得的数值是音频的模拟电压值。
量化:用数字化的值来表示电压,就要把电压值划分成若干等级,每个等级可表示为一个数值,这就是量化。量化简单的说就是对采样点进行近似值表示,分得级越多,数字音频质量就越高。通常电话语音用8位(256级)或CD用16位(65536级)。
编码:模拟信号转为数字信号说白了就是将模拟信号进行编码,将量化值以二进制的方式进行表示叫编码。
PCM
PCM(pulse code modulation脉冲编码调制)是把声音从模拟信号转成数字信号的一种技术。
也就是A/D变换器。
原理: 按照一个固定的频率去采样。所以对pcm来说有两个重要的指标:采样频率和量化精度。
【采样频率】:
刚才我们说样本是从波形中采集到的一个点。一次只能在波形中采一个样本。我们为了让计算机还原波形,必须要在规定时间内进行足够多次采样操作才能接近原波形。我们知道,频率 = 1 / 周期,画个源波形和采样波形。如果采样率为1Hz,那么周期为1,表示每一秒采一次样本,如果采样率是2,那么周期为0.5,表示每0.5秒采一次,波形就变成这样,可以推断出,在规定时间内,采样频率越高,声音还原的效果越好。咱们通信音频采样率一般为8000Hz,也就是1秒采8000次样本。
采样定理: 用大于信号最高频率两倍的频率,对周期信号进行采样,可以保证完全重构原始信号。
人的听力感知范围是20~20000Hz,信号最高频率是20000Hz,所以cd的采样频率大于40000Hz就能还原出人耳所能感知到到的所有声音,常见的比如44.1kHz,48kHz, 96kHz
之所以会取一个大于40k的采样频率比如44.1k、48k甚至更高的96k,可能是因为采样后需要量化,量化会有误差,为了缩小量化误差,要么提高采样频率,要么增加量化精度。
【量化精度】:
也就是刚才我们说的对电压值进行分级,一级表示一个数值,用这个数值去近似表示采样点,一个数值表示一个样本,量化精度越高,量化值就越接近采样点,越接近就越准确。
量化分为均匀量化和非均匀量化。
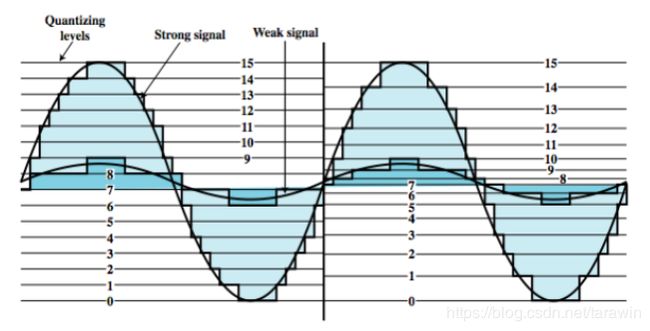
由图可知:均匀量化中,量化间隔均匀划分,无论电压信号强弱,每个样本的绝对误差都相等,结果导致振幅较低的地方失真严重,不适合弱信号(例如语音信号)。
非均匀量化,弱信号量化间隔密,强信号量化间隔疏。
如果按照非均匀量化,弱信号量化间隔密,能表示弱信号的量化值也就变多了,改善了弱信号失真的情况。
改善弱信号失真的方法有两种,一种是刚才说的,采用非均匀量化的方式,第二种就是提高量化精度。
同样的波形在相同的采样频率下比较分8位和分16位,明显是16bit能细化出更多不相同的样本值。
编码:
刚才我们说道,把量化值用二进制的方式表示叫编码。
有些编码方式不会对原始数据量进行压缩,所以原生16bitpcm样本是没经过压缩的编码数据。压缩是编码的一种。
数据压缩分为有损压缩和无损压缩,有损压缩虽说是有损,不影响正常收听。
压缩的方式有很多种:
- 在一个样本内部进行压缩。
- 相邻两个样本间取不相同的地方(做差)进行压缩,所以在播放时,后一个样本依赖于前一个样本。
- 将样本以块来处理,取平均值。
现在介绍第一种压缩方式——在样本内部进行压缩。
g711是一种由国际电信联盟制定的一套语音压缩标准,主要用于电话语音通信,而人声最大频率一般在3.4kHz,所以只要以8k的采样频率对人声进行采样,就可以保证完全还原原始声音。
g711的内容是将一个13bit或14bit的样本编码成一个8bit的样本。
g711标准主要分两种压缩方法:a-law和mu-law,
a-law:将一个13bit的pcm样本压缩成一个8bit的pcm样本。
mu-law:将一个14bit的pcm样本压缩成一个8bit的pcm样本。
【问题】:刚才不是说pcm是16位的么,怎么就变成了13bit14bit
【解答】:
13bit14bit取决于你A/D转换器的量化精度,对13bit精度的量化值进行编码,得到一个13bit二进制pcm样本值,也得用2字节也就是16bit去存,在这种编码规则下,13位14位和16位的样本都是用2字节来存,无法将他们区分出来,所以就看你是让高13位赋予意义还是让低13位赋予意义。
对于一个pcm二进制样本来说,高位代表强信号,低位代表弱信号。我最开始写代码取的是高13位,我用强信号去代表整个样本,结果就导致了弱信号解析不清楚,音频质量一般,声音有点小,感觉像是给你的耳朵盖上一层棉被听音乐。于是我就改取了低13位,采取放大弱信号的方式,整体运行出来的音质更好一些。
a-law
a-law采用13折线法编码,13折线是从“非均匀量化”基点出发,非均匀量化是精分低信号,粗分高信号。alaw编码的目标是将一个13bit的pcm样本压缩成一个8bit样本.
- 假设x/y的最大取值范围都是-1~+1.
- x/y轴分别代表量化级和分段序号(输入/输出)。所以13折线法的目的实际上是在给量化级分段,每段用一个固定的序号来表示。
- 将x轴不均等分成8段。按照每次1/2取分,分成8个段,7个点。
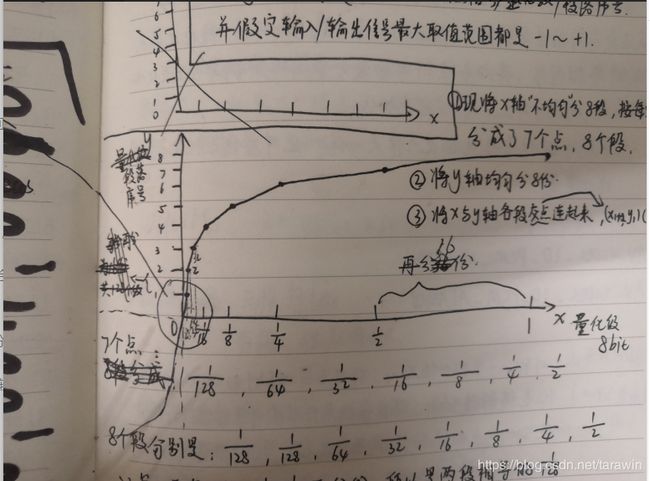
- 将y轴均匀分8份
- 将x/y轴各段交点连接起来
分成7个点:1/128,1/64,1/32,1/16,1/8,1/4,1/2
分成8个段:1/128,1/128,1/64,1/32,1/16,1/8,1/4,1/2(x轴每个点之间的间隔)
【由图可知】:
0~1/128段和1/128~1/64的距离相等(是1/64平分来的),所以这两段的斜率相同,可以将第一第二段看作一大段,所以实际上是分了7段不同的斜率。
因为取值是±1,所以反向还有一段一样的图,因为±1±2斜率相同,所以将其合成一大段,这时整个图总共有13段斜率不同的折线,这就是13折线法的由来。
x轴的量化我还没画完,实际上它是这样的。当我们在x轴每一段中再均等分16份,这时他就是128级,因为他是8bit,得分到256级为止,我就不在细化了。
可以看到折线的变化越来越平缓,当x值大时,有大范围的x都被量化成8,精度较低,当x值小时,折线变化剧烈,精度高。
在16bit的pcm中挑出13bit,经过了13折线法,生成了一个8bit的样本,
看表格第二纵列

压缩后的数据只有8bit,用char来存放,s是符号位,八段序号对应000~111(8段),abcd是从16bit的pcm中截取的有效样本。
看表格第一竖列一共有13bit,第一位是符号位,序号位是符号位之后碰到的第一个1之间的位数,包括这个1…序号位最多有7位,这7位从低位往高位数,第一位是1就对应1,第二位是1就对应2,第7位是1就对应7,全是0就对应0.
所以代码的难点只有在13位的pcm中找符号位之后的第一个1。(就这么简单)
看代码
关于位运算:
& 与 :同1则1
| 或 :有1则1
~取反:按位取反
^ 亦或:相同为1
<< 左移:×
>> 右移:/
十进制中想要把0010向左移一位
变成0100,是不是要 * 10^1,
所以十进制的0010 << 2,
就表示0010 * 10^2
同理,二进制的0010 << 1 是0010 × 2的1次方
代码流程:
- 取符号位。
- 找符号位后第一个1,获取序号位。将除了符号位以外的12位取出,传入函数中去找第一个一。
- 拼接符号位,序号位,样本位。
- 返回对偶位二进制位取反。

问题:负数变正数时为什么要-1?
解答:我们传进来的数是有符号数,例如4bit的有符号二进制表示是从0~7, -1~-8。把负数取绝对值变正数之后变成1~8,总体比0~7大1,所以-pcm变正后要-1.
查找第一个1:
【计算式】:
将除符号位外的12位进行与运算
1000 0000 0000 进行与运算,同1则1
,如果与出来的结果为0,那么表示这一位不是1,
如果与出来的数不为0, 则表示该样本的序号位是7,
函数返回所对应的序号.
flag二进制上的1右移一位变成
0100 0000 0000 以同样的方式进行与,
直到找到第一个1,找不到意味着全是0,返回0.
【记录式】:
若这12位pcm > 0111 1111 1111(0x7ff),
则表示这12位pcm的最高位是1(1xxx xxxx xxxx),
最高位是1对应的是序号7,返回7.
如果pcm < 0111 1111 1111,
让pcm与0011 1111 1111比较,
如果大于返回6, 小于的话就将最高位的1变为0
这时我们就能打出个表,从0x1f~0x7ff
当序号位 = 0时, pcm要右移一位才能把abcd都放在低4位
否则,序号位 = 几就右移几位,目的是将abcd放在低4位
最后就是把符号位,序号位,样本位放在8bit中该放的位置。
0xd5 = 1101 0101。
这就是alaw算法实现压缩。
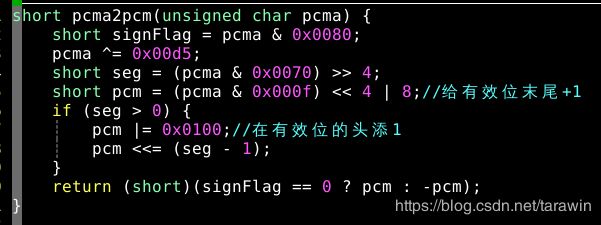
pcma转pcm代码
mulaw
mu-law:将14bit的pcm样本变8bit。不均匀量化
比alaw多一位
折线图我就不细讲了。
看表
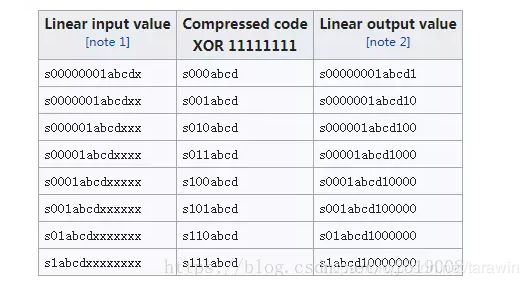
看第二纵列,依然是符号位s,序号位000~111(共8段),有效位abcd
看第一纵列,序号位最长是8. 序号位从低位往高位看,1在第1位代表0, 在第2位代表1,在第八位代表7.
规律:1在第n位代表n - 1
偏移表:

代码流程:
- 取符号位
- 将除符号位外的13位取出,找第一个一,获取序号位
- 拼接
- 全部取反

和alaw不一样的地方是mu-law整体会进行一个线性的偏移,
原本mulaw14bit的pcm样本除去一位符号位外还剩13bit,13bit二进制位有213种状态 = 8192,关于mulaw的相关文档上写着8159是mulaw的最大量化级。
偏移量为33.
所以为了方便计算机进行处理,给所有的样本都+33
为什么??!!
这一块我到现在都不是很懂,有哪个明白的大佬能帮忙解释一下么。。。。
pcm += (0x84 >> 2)这行代码是从sox源码中抄的。sox加33为什么用这么骚的操作?
直接加不好么?变成pcm += 0x21不是更直接么?
pcmu转pcm代码
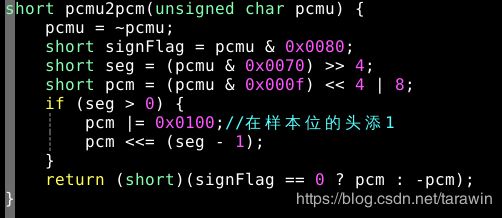
调制
编好码后进行调制,怎么调制才能播放?
三个条件一个都不能少。
- 声道数:单 / 立体
- 样本位数:一个样本的二进制位数。4bit、8bit、16bit、32bit
- 采样频率:表示一秒采集样本的次数。(一次一个样本)采样频率越高,样本数量越多,还原的越好。
像平时我们接触的什么mp3,wav格式的音频里面都记录着这三条基本信息,mp3,wav都是音频数据的装载容器,信息记录在容器的头部,播放器通过这些信息才知道要怎么解析这段音频数据。
pcm不是按一帧装一个样本来打包的,而是按照打包率进行打包,咱们组对音频的采样频率规定为8kHz,1帧有160个样本。
所以160/8000 = 0.02s的打包率,1s = 1000ms ,打包率 = 20ms,所以1s / 20ms = 50Hz,也就是一秒收50帧。
往常我们播放视频音乐时出现的xxkb/s是比特率,表示一秒钟处理的bit数。
比特率 = 样本位数 * 采样频率 * 声道数
以压缩后的8位pcm,采样频率为8000Hz,一帧有160个样本例。
一秒采8000个样本。一个样本占8bite,所以一秒收8bit * 8000个样本 * 1个声道数 = 64kb/s 的比特率。
一帧的播放时间 = 160 / 8000(打包率) * 1000ms