安装三大库
1、requests
2、BeautifulSoup
3、lxml
有的网站做了相应的反爬虫,不能用普通方法爬取网站数据。
这里我用python爬取了几个网站的数据,分别存入csv文件,mysql数据库,并用简单工具对数据进行了分析和可视化。具体代码和详解请参考
代码下载
有帮助到您,记得给颗
一、爬取糗事百科数据(pachong.py)
1、用python爬取糗事百科的用户地址,并且解析出地址的经纬度,在地图上通过热力图绘制出来
2、把数据保存到excel表中,再用BDP绘制出热力图
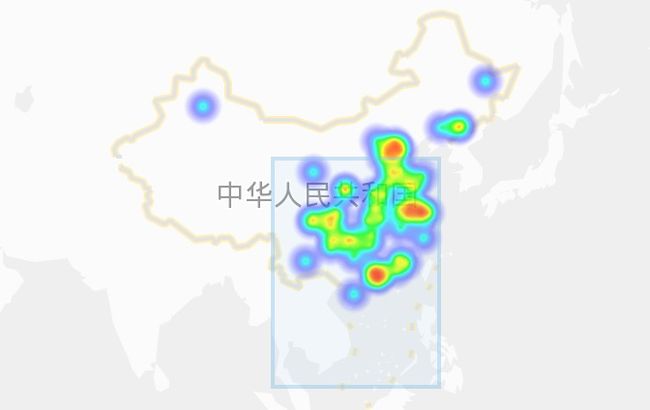
二、多进程快速爬取豆瓣电影250数据数据(multipelPrcessCrawer.py)
1、导入Pool进程池,开四个进程爬取豆瓣电影排行信息
2、存入mysql数据库中
三、lxml爬取小说数据(lxml-scrawer.py)
四、爬取《斗破苍穹》小说原文(doupo.py)
1、爬取《斗破苍穹》小说所有章节的内容
五、jieba统计词频(jiebatest.py)
1、导入jieba包,统计《斗破苍穹》词频
2、用wordart可视化


https://www.cnblogs.com/sss4/p/7809821.html
import requests
from bs4 import BeautifulSoup
res = requests.get("http://xa.xiaozhu.com/")
soup = BeautifulSoup(res.text,'html.parser')
prices = soup.select('#page_list > ul > li:nth-of-type(7) > div.result_btm_con.lodgeunitname > span.result_price > i')
for price in prices:
print(price)
输出本页所有的价格
page_list > ul > li > div.result_btm_con.lodgeunitname > span.result_price > i
酷狗排行榜top500数据爬取
import requests
from bs4 import BeautifulSoup
res = requests.get("http://xa.xiaozhu.com/")
soup = BeautifulSoup(res.text,'html.parser')
prices = soup.select('#page_list > ul > li > div.result_btm_con.lodgeunitname > span.result_price > i')
for price in prices:
print(price.get_text())
import requests
from bs4 import BeautifulSoup
import time
def get_info(url):
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text, 'lxml')
ranks = soup.select('span.pc_temp_num')
titles = soup.select('div.pc_temp_songlist > ul > li > a')
times = soup.select('span.pc_temp_tips_r > span')
for rank,title,time in zip(ranks,titles,times):
data = {
'rank':rank.get_text().strip(),
'singer':title.get_text().split('-')[0],
'song':title.get_text().split('-')[1],
'time':time.get_text().strip()
}
print(data)
if __name__ =='__main__':
urls = ['http://www.kugou.com/yy/rank/home/{}-8888.html'.format(str(i)) for i in range(1,24)]
for url in urls:
get_info(url)
time.sleep(1)
爬取小说内容保存到txt文件
import requests
import re
import time
f = open('/Users/jalynnxi/Desktop/doupo.txt','a+')
def get_info(url):
res = requests.get(url)
if res.status_code == 200:
contents = re.findall('(.*?)
',res.content.decode('utf-8'),re.S)
for content in contents:
f.write(content+'\n')
else:
pass
if __name__ =='__main__':
urls = ['http://m.doupoxs.com/doupocangqiong/{}.html'.format(str(i)) for i in range(1,1624)]
for url in urls:
get_info(url)
time.sleep(1)
f.close()
爬取糗事百科的用户信息
import requests
import re
import time
info_lists = []
def judgment_sex(class_name):
if class_name == 'womenIcon':
return '女'
else:
return '男'
def get_info(url):
res = requests.get(url)
ids = re.findall('(.*?)
',res.text,re.S)
levels = re.findall('(.*?)',res.text,re.S)
sexs = re.findall('.*?(.*?)', res.text,re.S)
laughs = re.findall('(\d+)',res.text,re.S)
comments = re.findall('(\d+) 评论',res.text,re.S)
for id, level, sex, content,laugh,comment in zip(ids, levels, sexs, contents, laughs, comments):
info = {
'id': id,
'level': level,
'sex': judgment_sex(sex),
'content': content,
'laugh': laugh,
'comment': comment
}
info_lists.append(info)
print (info)
if __name__ == '__main__':
urls = ['https://www.qiushibaike.com/8hr/page/{}/'.format(str(i)) for i in range(1,10)]
for url in urls:
get_info(url)
for info_list in info_lists:
f = open('/Users/jalynnxi/Desktop/qiushi.txt', 'a+')
try:
f.write(info_list['id']+'\n')
f.write(info_list['level'] + '\n')
f.write(info_list['sex'] + '\n')
f.write(info_list['content'] + '\n')
f.write(info_list['laugh'] + '\n')
f.write(info_list['comment'] + '\n')
f.close()
except UnicodeEncodeError:
pass
把数据写如excel
import xlwt
book = xlwt.Workbook(encoding='utf-8')
sheet = book.add_sheet('Sheet1')
sheet.write(0,0,'python')
book.save('test.xls')
爬取书名、作者、分类等信息存入excel
import xlwt
import requests
from lxml import etree
import time
all_info_list = []
def get_info(url):
html = requests.get(url)
selector = etree.HTML(html.text)
infos = selector.xpath('//ul[@class="all-img-list cf"]/li')
# infos = selector.xpath('/html/body/div[2]/div[5]/div[2]/div[2]/div/ul/li[1]')
# print (infos)
# '/html/body/div[2]/div[5]/div[2]/div[2]/div/ul/li[1]'
for info in infos:
title = info.xpath('div[2]/h4/a/text()')[0]
author = info.xpath('div[2]/p[1]/a[1]/text()')[0]
style_1 = info.xpath('div[2]/p[1]/a[2]/text()')[0]
style_2 = info.xpath('div[2]/p[1]/a[3]/text()')[0]
style = style_1 + '.' + style_2
complete = info.xpath('div[2]/p[1]/span/text()')[0]
introduce = info.xpath('div[2]/p[2]/text()')[0]
word = info.xpath('div[2]/p[3]/span/text()')[0]
info_list = [title, author, style, complete, introduce, word]
all_info_list.append(info_list)
if __name__ == '__main__':
urls = ['https://www.qidian.com/all?page={}'.format(str(i)) for i in range(1,3)]
for url in urls:
get_info(url)
header = ['title', 'author', 'style', 'complete', 'introduce', 'word']
book = xlwt.Workbook(encoding='utf-8')
sheet = book.add_sheet('Sheet1')
for h in range(len(header)):
sheet.write(0, h, header[h])
i = 1
for list1 in all_info_list:
j = 0
for data in list1:
sheet.write(i, j, data)
j += 1
i += 1
book.save('xiaoshuo.xls')