最近图相关的理论很火热啊,耳边一直听到各种graph embedding,什么GNN、GCN,结果发现自己对这方面完全不了解,赶紧找几篇论文来读一读。今天这一篇就是大家不管听没听说但总觉得眼熟的node2vec。不用想,这个node2vec一定跟word2vec有血缘关系,所以熟悉word2vec的同学应该可以很快了解node2vec的思想。

不同于图像、自然语言这种欧式空间的数据,网络结构的数据——图,通常无法通过CNN或者RNN来处理,这就需要我们寻找其他的方法来处理图数据。图数据其实非常常见,例如社交网络关系、分子结构、论文互相引用的关系网络等等,所以如何表达网络节点的特征就十分重要,表达好了节点的特征,我们就可以用它做下游的分类、预测、聚类、可视化等等任务。
传统的特征表示方法:
1. 特征工程
这个是机器学习最苦最累最关键的活儿,之前处理图数据,需要请专家人工定义网络节点的特征,这里面涉及很多图论的知识和领域知识,所以特征工程十分麻烦。
虽然这种特征工程最后往往可以(在花费巨大人力物力之后)取得比较好的效果,但一个明显的问题是——泛化性能差!因为特征工程往往是针对特定任务的,你换一个任务,也许之前的特征就不管用了。
2.在任务中学特征
前面不是嫌累嫌麻烦嘛,那咱们就不自己定义特征,定义一个下游任务,把这些特征作为参数,喂大量数据让它自己去学!显而易见,你是省事儿了,机器可不省事儿。成千上万个节点、随便就上百的维度,轻轻松松让你增加几千万训练参数,这个计算开销可大了。而且,这还是有监督的方法,意味着依然在不同任务间的泛化性能较差。
3.隐模型法/降维/矩阵分解法
这一类方法不知道怎么叫才好,总的思想跟推荐系统中矩阵分解法十分类似,属于无监督学习。试着把原来的网络结构表达成一个巨大的系数矩阵,然后通过Factorization来得到隐表示,作为各个节点的表示向量。这一类方法主要的问题在于计算开销大,尤其是对于真实世界中的大型网络,搞一个矩阵分解也不是什么容易事儿。另外,实证表明这样的表示在很多预测任务上效果较差。
新的思路 & 本文方法
上面列举了传统的方法的各种问题。那么可以怎么设计一种新的思路来得到节点的表示呢?
作者们想到了那大名鼎鼎的词向量——word2vec。词向量方法从大量的无标注文本中学得词语的分布式表示,不仅蕴含了大量的信息,而且可以迁移到各种下游任务中。对于网络数据能否使用同样的方法呢?
网络中存在很多很多通路,将各个节点连成一条线,这些连线蕴含着节点之间的相互关系,就如同句子中各个词语的关系一样。因此,我们可以自然地想到——把这些节点序列当做句子,用word2vec的方法进行训练,就可以得到node的向量表示了!
这里的关键问题在于——如何生成node序列。这也是本文的重点。
如何生成node sequence
这里给出一个论文中的图来辅助说明:

这个图中,可以看到有两个明显的小团体,分别以u和s6为中心。如果这就是一个简单的社交网络关系的话,可以猜测u和s1,s2,s3,s4也许是同班同学这样的关系,同样s6和s5,s7,s8,s9也是类似的关系,但二者不是同一个班。然后u和s6也许是两个班的班长。
那么这个里面就有些意思了,我们在生成节点序列的时候,要有什么规则?
首先,我们要知道,节点放到一个序列中了,就说明你认为它们在某种意义上是相似的。
你既可以认为u跟s1,s2,s3,s4它们是相似的,它们是网络中直接的邻居,这时称为homophily;
也可以认为u应该跟s6更相似,这种称为结构相似,structural equivalence。
要想从一个节点去寻找它的直接邻居,就要通过BFS(广度优先搜索),而如果想找到那些结构相似的,我们就不能在邻居那里转圈圈的,就需要“走出去”,因此就需要通过DFS(深度优先搜索)。图中给出了两种方法的示意。
node2vec使用的方法——biased random walk
在网络的表示中,homophily和structural equivalence都十分重要,我们希望可以在生成序列的时候同时考虑这两种相似性。
并且,我们希望可以有参数让我们控制二者的一个偏重,这样在不同的任务我们可以灵活地调整。
看下图:

假设我们从t节点开始了一个random walk,现在到达了v节点。
现在的问题是下一步怎么走?
如果采取BFS策略的话,应该走到x1,因为v和x1都是t节点的直接邻居;如果采取DFS策略的话,应该走向x2或者x3,因为它们和t都中间隔了一步;当然,也可能又返回到了t节点。
于是作者设计了一个二阶转移概率算法:
两个节点之间的转移概率为:
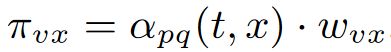
其中,w为两节点的边的weight,这个根据场景而设定。α为search bias,定义为:

一个节点的下一步怎么走,取决于它的上一步和下一步的关系。
有点拗口,我们逐一解释一下:
v是当前的节点,t是v的上一步所在节点,而x代表下一步的位置。
d(t,x)代表t和x之间的最短距离:
- 当d=0时,就是从v又回到t节点的意思,这个时候search bias为1/p,可以理解为以1/p的概率返回上一步;
- 当d=1时,则x为t的直接邻居,相当于BFS,这时的bias为1;
-当d=2时,则x是t邻居的邻居,相当于DFS,这时的bias为1/q;
作者称p为Return parameter,因为p控制着回到原节点的概率;成q为In-out parameter,因为它控制着BFS和DFS的关系。
这样,我们设置不同的p和q,就可以得到不一样偏重的node sequence。在训练模型的时候,可以使用grid search来寻找最优的p和q。也可以根据场景的需要来选择p和q。
如何学习节点特征
这里就是完全借用word2vec的方法。
总的目标函数是:

这里的f就是把节点u映射到特征空间的函数,N(u)是通过前面node sequence得到的u的近邻节点,相当于词向量训练中的上下文。
下面是具体如何计算:

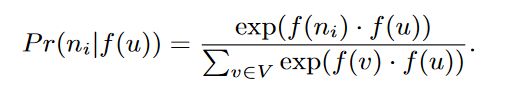
这一部分不想多讲,了解词向量的话这里十分好理解。
关于词向量,可以在我的专栏中找到相关的文章。
这样,我们就可以总结一个node2vec完整的算法框架了:

如何表示边的特征
上面已经学习到了各个节点(node)的特征,但是很多任务中我们是针对边(edge)的,因此我们也需要边的特征。
实际上,一条边不就是由两个节点决定的吗,因此可以用两个节点的特征来表示,作者给出了一些选项:

案例和实验:
1. 可视化
作者首先在一个人物关系网络上试了试node2vec,通过kmeans聚类,并做了一个可视化,看看node2vec得到的节点向量可以反映出网络的什么特点:
当作者设置p=1,q=0.5的时候,聚类的效果是这样的:
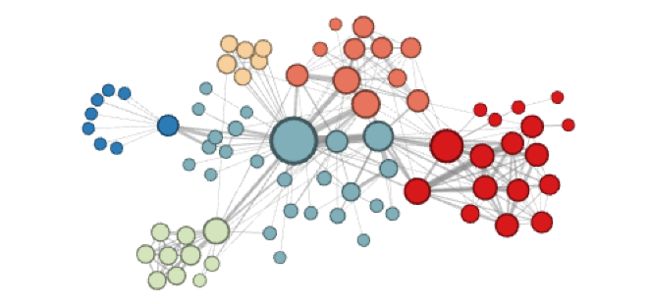
可见这个时候各个小社区、小团体被聚为一类。
当作者设置p=1,q=2的时候,聚类效果是这样的:
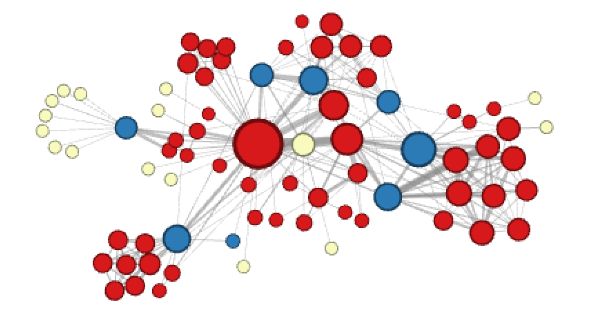
这个时候,可以发现各个社区之间的桥梁——蓝色节点,被聚成一类,因为它们有类似的结构特点,而那些淡黄色的点,是那些人物关系中比较边缘化的那些人。
所以可以看到,不同的p和q确实使node2vec刻画一个网络在不同方面的特点。
2. 节点分类(node classification)
这里先把使用的测试数据集和用于对比的模型列一下,由于比较好理解,我就不翻译了:
数据集:

对比模型:

实验结果:

3.连接预测(link prediction)
对于link,我们就需要构造边的特征的,具体构造方法上面也给出了。这里也是直接贴实验结果了:
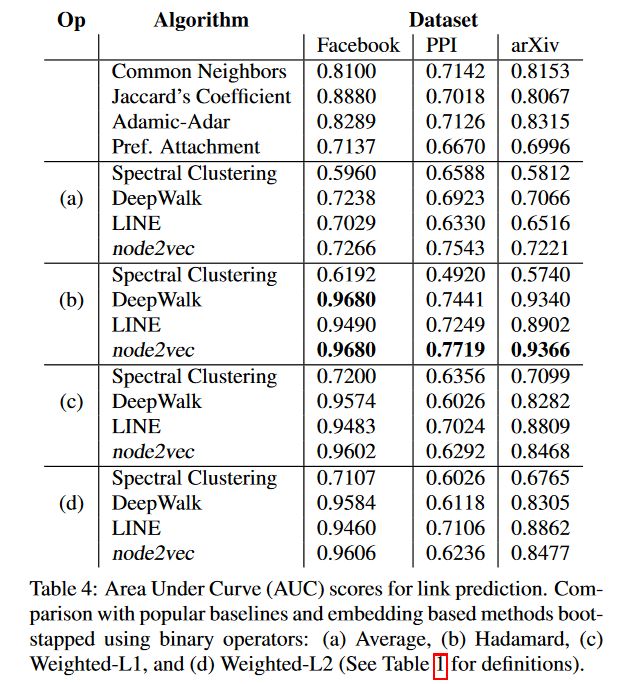
a,b,c,d分别代表四种edge feature生成的方法。
这些就大致是node2vec的内容,更多细节还是参见论文吧。
另外,斯坦福提供了现成的代码和训练方法,可以参见他们的官网:
http://snap.stanford.edu/node2vec/