-
本次暂时只安装一个Cluster(集群)节点,那么所有的功能都集成到这台服务上
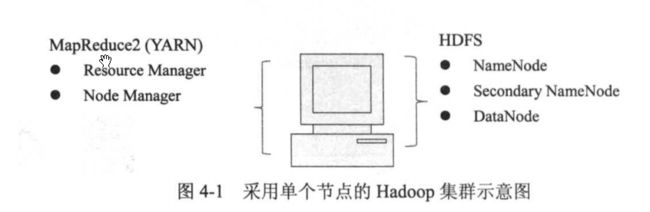 image.png
image.png
安装java
sudo apt-get update
sudo apt-get install default-jdk
java -version
openjdk version "1.8.0_222"
查询java安装位置
update-alternatives --display java
java - 自动模式
link best version is /usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java
链接目前指向 /usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java
link java is /usr/bin/java
slave java.1.gz is /usr/share/man/man1/java.1.gz
/usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java - 优先级 1081
次要 java.1.gz:/usr/lib/jvm/java-8-openjdk-amd64/jre/man/man1/java.1.gz
- 这里的链接目前指向就是java的安装位置
设置ssh无密码登录
- 无密码登录,并不是不需要密码,而是用的ssh key(秘钥)来验证
- 安装ssh
sudo apt-get install ssh
- 安装rsync
sudo apt-get install rsync
生成ssh key
hduser@hadoop:~$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
Generating public/private dsa key pair.
Created directory '/home/hduser/.ssh'.
Your identification has been saved in /home/hduser/.ssh/id_dsa.
Your public key has been saved in /home/hduser/.ssh/id_dsa.pub.
The key fingerprint is:
SHA256:leBtSdoVMKShUdCLSL2t1gb9eF4MdfabXKUo4r3rJ7k hduser@hadoop
The key's randomart image is:
+---[DSA 1024]----+
| .o++.=.o. |
| . .+.O =. o .|
| . ..=+.B. + o.|
| . + =oo . . o|
| =S= + . +|
| o = + o + |
| . . o + |
| = . |
| .E= |
+----[SHA256]-----+
- /home/hduser/.ssh/id_dsa.pub 就是产生的秘钥文件
- 查看产生的秘钥文件
hduser@hadoop:~$ ll ~/.ssh/
总用量 16
drwx------ 2 hduser hduser 4096 9月 14 18:54 ./
drwxr-xr-x 20 hduser hduser 4096 9月 14 18:54 ../
-rw------- 1 hduser hduser 668 9月 14 18:54 id_dsa
-rw-r--r-- 1 hduser hduser 603 9月 14 18:54 id_dsa.pub
- 将产生的key放在许可证中
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
下载安装Hadoop
- 首先去官网查看下Hadoop和spark 版本的对应关系
- 点击查看github上的spark的pom.xml的中的对应关系
- 可以查看到spark的版本为3.0:
org.apache.spark spark-parent_2.12 3.0.0-SNAPSHOT pom Spark Project Parent POM http://spark.apache.org/ - 同样,搜索关键字:
hadoop.version,可以知道hadoop版本可以选择2.7.4和3.2.0 - 所以本次我们需要下载2.7.4版本的hadoop和spark为3.0版本
- 打开hadoop-2.7.4,下载文件hadoop-2.7.4.tar.gz,输入命令:
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.4/hadoop-2.7.4.tar.gz
- 解压
sudo tar -zxvf hadoop-2.7.4.tar.gz
- 移动hadoop
sudo mv hadoop-2.7.4 /usr/local/hadoop
- hadoop目录分析
hadusr@hadusr:~$ ll /usr/local/hadoop/
总用量 148
drwxr-xr-x 10 20415 systemd-journal 4096 8月 1 2017 ./
drwxr-xr-x 11 root root 4096 9月 15 20:38 ../
drwxr-xr-x 2 20415 systemd-journal 4096 8月 1 2017 bin/
drwxr-xr-x 3 20415 systemd-journal 4096 8月 1 2017 etc/
drwxr-xr-x 2 20415 systemd-journal 4096 8月 1 2017 include/
drwxr-xr-x 3 20415 systemd-journal 4096 8月 1 2017 lib/
drwxr-xr-x 2 20415 systemd-journal 4096 8月 1 2017 libexec/
-rw-r--r-- 1 20415 systemd-journal 86424 8月 1 2017 LICENSE.txt
-rw-r--r-- 1 20415 systemd-journal 14978 8月 1 2017 NOTICE.txt
-rw-r--r-- 1 20415 systemd-journal 1366 8月 1 2017 README.txt
drwxr-xr-x 2 20415 systemd-journal 4096 8月 1 2017 sbin/
drwxr-xr-x 4 20415 systemd-journal 4096 8月 1 2017 share/
drwxr-xr-x 19 20415 systemd-journal 4096 8月 1 2017 src/

image.png
设置Hadoop环境变量
sudo gedit ~/.bashrc
export HADOOP_HOME=/usr/local/hadoop # hadoop的安装路径
export HADOOP_MAPRED_HOME=$HADOOP_HOME # 设置MAPRED环境变量
export HADOOP_COMMON_HOME=$HADOOP_HOME # 设置COMMON环境变量
export HADOOP_HDFS_HOME=$HADOOP_HOME # HDFS的环境变量
export YARN_HOME=$HADOOP_HOME # YARN的环境变量
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native # 链接库的相关设置
export PATH=$PATH:$HADOOP_HOME/sbin
export PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOME
export HADDOP_OPS="-Djava.library.path=$HADOOP_HOME/lib"
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64# 设置jdk的安装目录(参考上面查看步骤)
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
- 生效环境变量
source ~/.bashrc
修改Hadoop的配置文件
- 设置Hadoop-env.sh
sudo gedit /usr/local/hadoop/etc/hadoop/hadoop-env.sh
# 将JAVA_HOME设置为本机的java安装地址
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
- 设置core-site.xml
sudo gedit /usr/local/hadoop/etc/hadoop/core-site.xml
# 设置HDFS的默认名称,在使用命令调用时,可以用此名称
fs.defaultFS
hdfs://localhost:9000
- 设置YARN-site.xml
sudo gedit /usr/local/hadoop/etc/hadoop/yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
- 设置mapred-site.xml
用于设置Map和Reduce程序的JobTracker任务分配和运行情况
# 复制mapred-site.xml.template的模板文件
sudo cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml
# 编辑mapred-site.xml
sudo gedit /usr/local/hadoop/etc/hadoop/mapred-site.xml
#设置mapreduce作业是提交到 YARN集群
mapreduce.framework.name
yarn
- 设置hdfs-site.xml
sudo gedit /usr/local/hadoop/etc/hadoop/hdfs-site.xml
dfs.replication
2
设置blocks副本数
dfs.namenode.name.dir
file:/usr/local/hadoop/hadoop_data/hdfs/namenode
设置存放NameNode的数据存储目录
dfs.datanode.data.dir
file:/usr/local/hadoop/hadoop_data/hdfs/datanode
设置存放DataNode的数据存储目录
dfs.permissions
false
权限还是不要的好
创建并格式HDFS目录
- 创建namenode数据存储目录
sudo mkdir -p usr/local/hadoop/hadoop_data/hdfs/namenode
- 创建datanode数据存储目录
sudo mkdir -p usr/local/hadoop/hadoop_data/hdfs/datanode
- 将Hadoop目录的所有者更改为hdusr
sudo chown hadusr:hadusr -R /usr/local/hadoop/
- 将HDFS进行格式
hadoop namenode -format
启动Hadoop
- 启动HDFS
start-dfs.sh
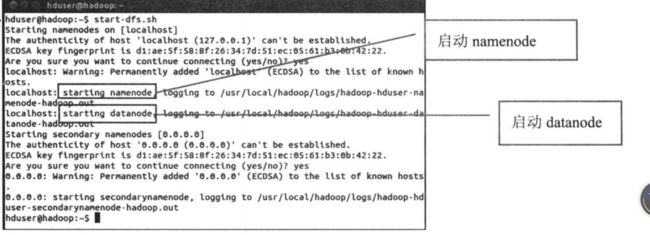
image.png
- 启动MapReduce的yarn框架
# 如果发现直接输入start-yarn.sh不行,直接进入到安装目录来运行
hadusr@hadusr:/usr/local/hadoop/sbin$ ./start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop/logs/yarn-hadusr-resourcemanager-hadusr.out
hadusr@localhost's password:
localhost: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-hadusr-nodemanager-hadusr.out
hadusr@hadusr:/usr/local/hadoop/sbin$
# 可以看到启动了nodemanager
- 查看当前运行的进程
hadusr@hadusr:/usr/local/hadoop/sbin$ jps
4020 NodeManager
3495 SecondaryNameNode
4135 Jps
3321 DataNode
3722 ResourceManager
3181 NameNode
- HDFS功能:NameNode,SecondaryNameNode,DataNode已经启动
- MapReduce(YARN):ResourceManager,NodeManager已经启动
打开Hadoop ResourceManager
- 浏览器输入:http://localhost:8088
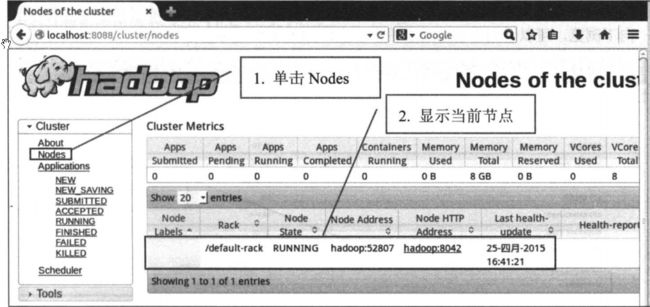 image.png
image.png
NameNode HDFS Web界面
- 浏览器输入:http://localhost:50070
-
可以看到当前显示了一个节点
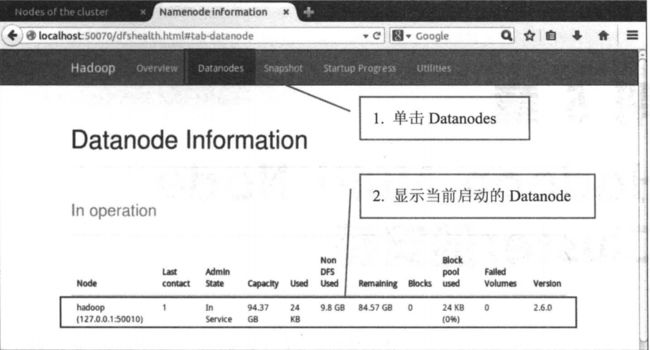 image.png
image.png