今天discussion课,讲的东西没想到就是我一直想学的。差一点没去上,因为之前几节课太无聊了。
主要讲了 Collections, Set, List, Queue, Map 这几种interface以及之间的关系。
我会在下面介绍。
首先先讲几个今天课上学到的东西,可能没那么关键,但也是以前自己的盲点。
编译器在编译的时候,到底做了什么。
这个我也很不清楚,但是有一些感受,说一下。
就是扫描整段的代码,然后汇集信息,生成一个 symbol table。同时生成汇编代码。然后将这两个东西交给汇编器,汇编器会根据汇编代码,去查symbol table。然后生成机器码,然后拷贝进一个大的框架,包含了其他的一些信息,所以会有linker的角色。最后拷贝进入内存,然后运行。
那么,对于这么一段代码,
int[] a = new int[5];
编译器是知道,他是 int 类型的。所以如果,
a[0] = "abc"; 编译器是知道他是错的。
同样,编译器知道数组的起始地址, [0,4],但是,不会进行边界检查,
所以, a[5] = 0; 在编译的时候是无法查出来的。
然后,
Object a = new Integer(5);
编译器是只知道, a是Object 类型的,不知道它含有Integer的特性。
那么,就进入到下一个问题,
- ArrayList
是如何在内存中表示的。
编译的时候,编译器知道, ArrayList 里面装的是 Integer,但是运行时是擦除的。
为什么编译的时候要知道?
防止你在这个arraylsit里面添加非Integer元素。因为运行时这样的错误你是无法检查出来的。所以,得在编译的时候,提前避免这种风险。
运行时,
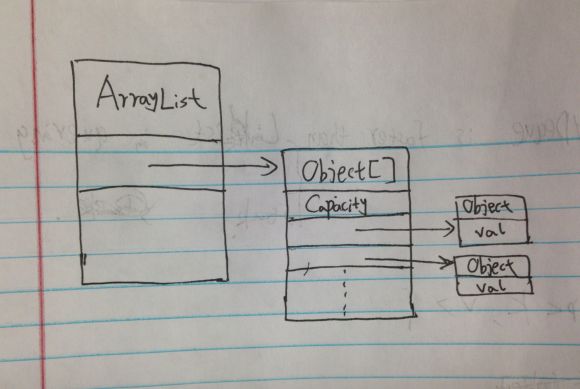
是这样一个 内存图。
这说明了什么,
ArrayList 有三个构造函数,

其中第一和第三个是常用的。
如果括号中没有数字,就默认初始化容量为10.否则, 就是指定的 capacity。
然后我们开始给arraylist add元素。
当元素个数超过capacity后,这个object[] 会 resize(), 扩大两倍,然后把原来的元素拷贝进来。
同样,如果是删减到一定程度的时候,也需要resize这个数组。缩小它。
所以,arrayList 作为一个链表的,他的效率并没有 linkedlist 高,因为他的本质还是数组,resize array , 而不是 链表。
然后这个概念,让我想起了另外一个细节,虽然和arraylist and linkedlist 的区别不一样,但是也有效率高低之分。
String vs StringBuilder
String 的本质,是一个 final char[] array, 只能被初始化一次。
所以每次给string新加一些元素的时候,都是重新new一个新的string,然后把旧的string 指针指向这个新 new的string,效率很低下。
而且,string的两种构造函数,
String temp = "abc";
String temp = new String("abc");
做出来的string是存放在不同地方的。
第一种,申明出来的string是直接存放在常量池中。
而第二种,申明出来的string,是直接存放在堆中的。
我对第一种到底有什么特性,不是很清楚。以后要去问一下。
而第二种,是存放在堆中的。然后string 类中用一个 int counter 来记录string的长度。
所以,string的最大长度只能小于等于 2 ^ 32 - 1,否则,int类型会overflow,产生无法估计的错误。
而StringBuilder 相比于string,一个很大的特点,就是它不是final类型的。
所以可以一直变化,所以给他加新元素,不需要重新创建一个string怎样怎样。。。。
直接添加就行,用 StringBuilder.append(); 好像不能用加号。
Java 中,两个string 相加,是新建一个string,把他们合在一起,还是把两者转换成stringbuilder,用apeend相加,然后再返回一个string?
总之,stringbuilder在相加这块,效率要高很多。
这是我老师给的一个简单总结。

说着说着又说远了。
下面就如第三个问题。
- Tree 的三种遍历方式。我对tree掌握的一直不是很好。所以这里再总结下,然后之后复习算法的时候,会把代码在复习下,写出来。
分为4种,
in-order
pre-order
post-order
level-order
前三种,是密切联系的。
in-order:
public void traverse() {
if (left != null)
traverse(left);
print(node);
if (right != null)
traverse(right);
}
pre-order
public void traverse() {
print(node);
if (left != null)
traverse(left);
if (right != null)
traverse(right);
}
post-order
public void traverse() {
if (left != null)
traverse(left);
if (right != null)
traverse(right);
print(node);
}
关键的 print,也是正好应了遍历的名字,
pre 最上面
in 中间
post 最下面
level-order
这叫组,层序遍历,其实不算是树的遍历方式。
方法就是新建一个队列,每次将弹出去的结点的左右子树,判断下是否为null,非null就插入队列。以后有时间再来实现。有好几道挺难的题出在这里面。
好,接下来,就开始讲重点。
Java Framework
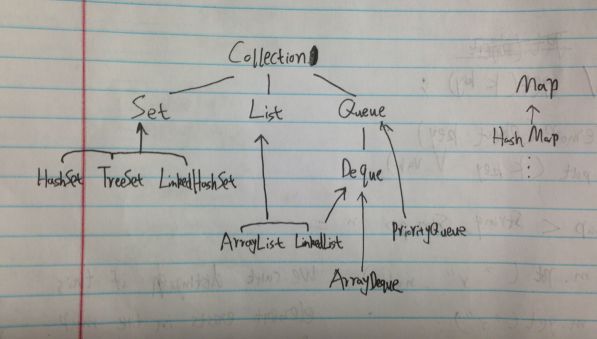
总结了下,他是长这个样的。
当然下面那些具体实现的类,可以忽略,总的interface,是这么一种结果。
下面一个个讲。
interface Collection extends Iterable {
int size();
boolean isEmpty();
boolean add(E e)();
boolean remove(Object e)();
boolean contains(Object e)();
boolean addAll(Collection)();
boolean removeAll(Collection)();
boolean retainAll(Collection)();
}
讲两个东西,
add的时候加入的是 E
但是remove的时候,移除的是 Object
TA感觉他自己也不是很明白,只说这里很奇怪,是Java的一个rule。
他说,加入的时候不需要比较,只需要加入同类元素,那么就用E。
但是移除的时候,需要比较,而且可能和其他类的元素比较,那么就只能用Object接受了。
iterator
interface Iterator {
boolean hasNext();
E next();
boolean remove(); // optional, not require to implement this method and
// it can only be used once after next();
}
上面这是Iterator 这个接口的定义。
然后可以用for循环来通过这个接口,取出这个容器里面的东西。
for (Iterator iter = Set.iterator(); iter.hasNext();) {
System.out.println(iter.next());
a.remove(); //right, can remove the string that is returned by iter.next();
a.remove() // wrong, will throw exceptions.
}
注意, for 循环,第三部分,留空,因为, i++的操作,iter.next(),做了。它相当于,做了两件事,返回当前值,并且,再往下指一格。
上面这个循环也可以等价于下面这个,更简单些。
for (String temp : Set)
System.out.println(temp);
然后最后介绍两个他的方法,之前我一直不会用。
Object[] toArray();
E[] toArray(E[] arr);
第一种比较好理解。
Object[] a = Set.toArray(); 会返回一个 Object[].
第二种,需要传进去一个 E[] 对象,然后java 会将 Object[] 拷贝进去,按照他需要的个数。
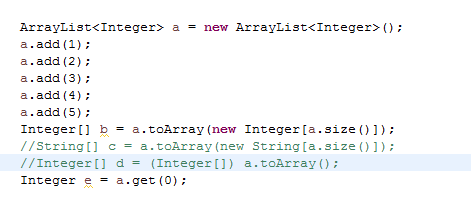
然后注意,正如上次,comparator 一样,传进去的泛型,必须是一个类,而不能是primitive type.
TA说,这里用到了Java的反射机制。这里不是很清楚,就不瞎说了。
注释的两句话都是运行时会出错的,第一个可以解释。
因为Object 本质是Integer类型的,不能强制转换成,String。
第二个就不能理解了。
刚刚已经说了, ArrayList里面存放的是一个 Object[]. 然后本质是Integer,为什么不能把它强制转换成Integer[]。 编译都是通过的,就是运行过不了。
同样的,既然运行时擦除泛型信息,为什么 a.get(0) 返回的东西不需要强制转换为Integer?
为什么我们是知道他的返回类型的?意思是说,运行时,已经强制转换过了?
但是运行时是没有
这里我会去问的,之后再在这里给出解释。
下面开始讲下一层结构。
Set
interface Set extends Collection {...}
--- math set abstraction: no duplicate elements
Set一个最大的特点是,不允许有重复元素。
所以他的一个很大的作用,就是去重复。
我用LinkedHashSet 将元素一个个输入进来,然后重复的就被覆盖了,
然后再一个个按照插入顺序输出来。可以去重复。
HashSet -> most performant, hashcode();
TreeSet -> search by BST(red-black tree), self-balanced
LinkedHashSet -> use Linked data structure, search in "insertion order"
List
interface List extends Collections {...}
E get(int i);
void set(int i, E e);
void remove(int i);
这几个方法没什么好讲的,下面讲下,他的两个代表性类。
ArrayList O(1) -> possitional access
O(n) -> insert/remove at head
LinkedList O(n) -> possitional access
O(1) -> insert/remove at head
刚刚上面已经详细解释过 ArrayList 运行原理了。
他的局限性在于,他的本质还是数组。所以不能很方便的进行插入删除。
他的插入删除,虽然复杂度只有1.但其实是伪装的,因为它只能在尾部插入删除。没什么用,但也可以满足一小部分的需求。
而linkedlist,就擅长插入删除。在头部插入删除复杂度是1.而普通的在任意位置插入删除,复杂度是线性的。而arraylist,在我看来,似乎根本就不能在任一节点进行插入删除。
所以,两者是截然不同的数据结构,虽然都披着List的外衣。
List可以包含重复的元素。他的特点在于, 有序性。
我们要获得element,都是一个一个获得的。似乎Set也可以一个一个获得。。所以感觉这也都是说说而已。主要就是用一个线,把所有数据串在一起,有一个开头,可以从这个开头,沿着这条线,开始找。
而,Set没有这条线,也没有这个开头,感觉要返回的话,都是返回一个迭代器。然后遍历。虽然也有一定的顺序性,但是没有这么直接强烈。
Queue
interface Queue extends Collection {...}
boolean offer(E e);
E peek();
E poll();
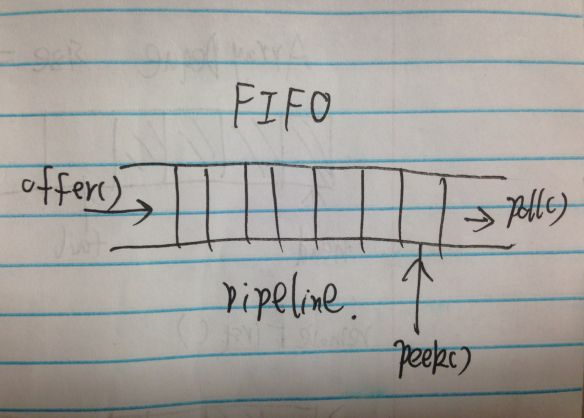
这就是Queue具体的模样。
然后具体讲一个PriorityQueue
他的优先级有两种计算方式。要么是元素自带的Comparable接口。
要么是,我们人工传入Comparator让他们进行比较
PrioirtyQueue
-> 1. natural ordering implements comparable interface
2. Comparator
Deque
interface Deque extends Queue {...}
-> doubly ended queue
addFirst
removeFirse
addLast
removeLast
有两个类继承了这个接口。
-LinkedList
-ArrayDeque
具体讲下, ArrayDeque
初始化的时候,会生成一个你指定长度的数组。
然后两个指针,
head = -1; //TA说的,我不太能理解,感觉不是这样的
tail = 0;
然后假设现在已经插入了四个元素。

如果选择删除一个元素,removeFirst()

如果选择插入一个元素, addFirst();

head 是可以移动到数组后面位置的。
当head == tail 时,就需要resize数组了
void addFirst(E e) {
head = (head - 1) % element.length;
<=> head = (head - 1) & (element.length - 1) // much faster because of bit manipulation
if (head == tail)
resize(array);
element[head] = e;
}
ArrayDeque is faster than Linkedlist in quering data
Map
interface Map {...}
V get(K key);
boolean remove(Object key);
boolean put(K key, V val);
Map独特于Collection interface 的地方在于,他是一次存一对元素,键值对。
然后他也有一些buggy 的地方。
Map = new ....
m.put("re", null);
String s = m.get("r");
/** we can't distinguish if this element exists in the map. Because you can insert null as your
val or if you can't find the key, it will also return null. We cannot distinguish it. */
Java 8
V getOrDefault(K key, V default)
// if it cannot find key, it will return value default rather than null, this can help
//but special code to test is buggy
上面是我做的课堂笔记,英文的,但是也不是很难,将就看看吧。感觉写完这篇文章快累死了。。。。
Collections
class Collections {...}
static methods
1.sort()
2.shuffle()
3.reverse()
...
然后TA讲了其中的sort()
static > void sort(List l);
static void sort(List l, Comparator c);
我现在其实还是无法理解,
这个前置的
日了狗了。。终于总结的差不多了。写了接近两个小时。。。
现在好饿。。。
Anyway, Good luck, Richardo!
HashTable vs HashMap
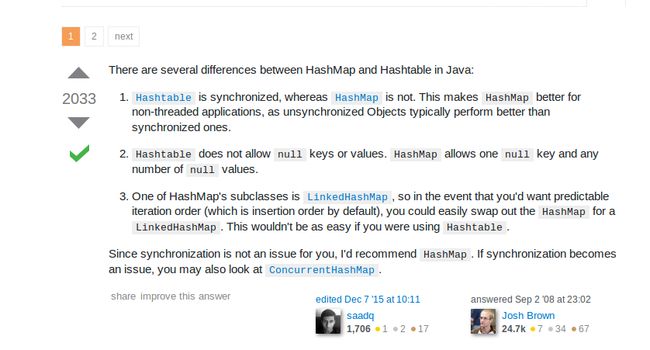
链接:
http://stackoverflow.com/questions/40471/differences-between-hashmap-and-hashtable
Anyway, Good luck, Richardo!