最近因工作原因,需要处理一些数据,顺便学习一下动态图表的绘制。本质是使具有源头的流动信息能够准确找到其上下级关系和流向。
数据来源是csv文件 导入成为dataframe之后,列为其车辆的各部件供应商公司名称或其自身的属性。
导入后经过处理期望是看到整个工业的供应链和市场份额.
结果的部分截图:

数据来源:

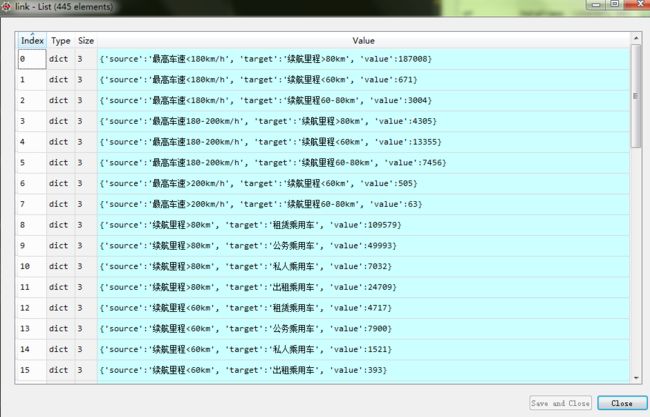
核心是将以上数据处理成接口需要的两个数据,一个是所有节点的名称。另一个是节点之间互相链接的值,见下图
NODE: 所有桑基图的节点集合

link: 每一个数据流的起始,结束,与值。
核心统计原理是:
先确定从左到右的统计大纲:在本次案例中为:

接下来就是找大纲序列中当前大类中对应下一级的小类的数目,例: 案例第一步即找最高车速段中 最高车速能力在<180km/h的筛选出来,同时找出低速度段且续驶里程>80km的数量.
统计代码:
# link 数据架构 link=[] for i in range(len(title)): temp0=list(class_item) for j in list(class_item[temp0[i]]): try: for k in list(class_item[temp0[i+1]]): df1=df[df[temp0[i]]==j] df2=df1[df1[temp0[i+1]]==k] temp_value=len(df2) if temp_value!=0: link.append({'source':j, 'target':k, 'value':temp_value}) del df1 del df2 except: continue
总代码:
# 数据架构 总领数据架构-品牌-车辆用途- import matplotlib.pyplot as plt from pyecharts import Pie,Bar,Page,Bar3D,Overlap,Line,Boxplot,Surface3D,Sankey,EffectScatter import pandas as pd import numpy as np df=pd.read_excel(r'C:\Users\wenzhe.tian\Desktop\数据分析\北理新能源数据v2\02_20190301\2EV_v2.xlsx','Sheet1') df_ori=df.copy() #数据处理部分 添加项目,替换重复 格式统一 去掉空格 等 df=df[df.技术类型.str.contains('EV',regex=False)] df=df.reset_index() df=df.drop('index',axis=1) #数据格式处理 df['车型分类']=df['车型分类'].fillna('nan') df=df[~df['车型分类'].isin(['nan'])] # 江淮ES8供应商数据大量缺失,故排除 也可drop df['电动汽车续驶里程(工况法,km)']=df['电动汽车续驶里程(工况法,km)'].fillna(0) df['车辆品牌']=df['车辆品牌'].map(str).replace('传祺(Trumpchi)牌','传祺(Trumpchi)牌') df['通用名称'][df['电动汽车续驶里程(工况法,km)']==0]='ES8' df['电动汽车续驶里程(工况法,km)'][df['电动汽车续驶里程(工况法,km)']==0]=355 df['电动汽车续驶里程(工况法,km)'][df['电动汽车续驶里程(工况法,km)']=='155(对应整备质量750kg),165(对应整备质量700kg)']=165 df['电动汽车续驶里程(工况法,km)'][df['电动汽车续驶里程(工况法,km)']==170203203]=255 df['电动汽车续驶里程(工况法,km)']=df['电动汽车续驶里程(工况法,km)'].fillna(0) df['最高车速']=df['最高车速'].astype(int) df['电动汽车续驶里程(工况法,km)']=df['电动汽车续驶里程(工况法,km)'].astype(int) df['最高车速段']=df['最高车速'].astype(str) df['续驶里程段']=df['电动汽车续驶里程(工况法,km)'].astype(str) #df['电池能量密度']=df['电池容量']*df['储能装置总成标称电压(V)']/df['储能装置总成质量(kg)'] df['整备质量(kg)'][(df['整备质量(kg)'].isnull()) | (df["整备质量(kg)"].apply(lambda x: str(x).isspace()))]=2390 # 去掉前后空格 title=list(df) df['储能装置单体质量(kg)']=df['储能装置单体质量(kg)'].astype(str) for i in title: try: df[i]=df[i].map(str.strip) except: continue #重复值处理 df=df.replace('比亚迪汽车工业有限公司,比亚迪汽车工业有限公司', '比亚迪汽车工业有限公司') df=df.replace('比亚迪汽车工业有限公司/比亚迪汽车工业有限公司', '比亚迪汽车工业有限公司') df=df.replace('山东德洋电子科技有限公司,山东德洋电子科技有限公司', '山东德洋电子科技有限公司') df=df.replace('深圳市大地和电气股份有限公司(软件)/深圳市大地和电气股份有限公司(硬件)', '大地和电气') df['最高车速段'][(df['最高车速']<=180)]='<180km/h' df['最高车速段'][((df['最高车速']<=200)& (df['最高车速']>180))]='180-200km/h' df['最高车速段'][(df['最高车速']>200)]='>200km/h' df['续驶里程段'][(df['电动汽车续驶里程(工况法,km)']<=60)]='<60km' df['续驶里程段'][((df['电动汽车续驶里程(工况法,km)']<=80)& (df['电动汽车续驶里程(工况法,km)']>60))]='60-80km' df['续驶里程段'][(df['电动汽车续驶里程(工况法,km)']>80)]='>80km' title=['最高车速段','续驶里程段','车辆用途','企业名称','车型分类','车辆品牌', '电机生产商','电动汽车整车控制器生产企业','电动汽车车载充电机生产企业','储能装置总成生产企业','车载能源管理系统生产企业'] #无效值处理 for i in title: df[i]=df[i].astype(str) df[i]=df[i].map(lambda x: x.replace('有限公司','').replace('股份','').replace('公司','').replace('分','').replace(' Company','').replace(' company','').replace('牌','品牌').replace('北京新能源汽车','北汽新能源')) df[i]=df[i].map(lambda x: x.replace('浙江','').replace('山东','').replace('广州汽车集团乘用车','广汽').replace('杭州','').replace('江西','').replace('合肥','')) df[i]=df[i].map(lambda x: x.replace('深圳市','').replace('永康市','').replace('珠海','').replace('郑州','').replace('软件:','').replace('硬件:','').replace('北京:','').replace('长沙市','').replace('金华市','')) df[i]=df[i].map(lambda x: x.replace('nan','北汽新能源').replace('(','(').replace(')',')').replace('()','').replace('/深圳市大地和电气','').replace('开发企业','').replace('生产企业','').replace('福建省汽车工业集团云度新能源汽车','云度新能源')) df[i]=df[i].map(lambda x: x.replace('电机1:华域汽车电动系统/电机2:华域汽车电动系统','华域汽车电动系统').replace('前:蔚然(南京)动力科技/后:蔚然(南京)动力科技','蔚然(南京)动力科技')) if i =='最高车速段': str_item='最高车速' elif i =='续驶里程段': str_item='续航里程' elif i =='电机生产商': str_item='MOT' elif i =='电动汽车整车控制器生产企业': str_item='MC' elif i =='电动汽车车载充电机生产企业': str_item='OBC' elif i =='储能装置总成生产企业': str_item='BAT' elif i =='车载能源管理系统生产企业': str_item='BMS' else: str_item='' df[i]=df[i].map(lambda x: str_item+x) class_item={} for i in title: class_item[i]=df[i].drop_duplicates() node=[] for i in title: for j in list(class_item[i]): node.append({'name':j}) # link 数据架构 link=[] for i in range(len(title)): temp0=list(class_item) for j in list(class_item[temp0[i]]): try: for k in list(class_item[temp0[i+1]]): df1=df[df[temp0[i]]==j] df2=df1[df1[temp0[i+1]]==k] temp_value=len(df2) if temp_value!=0: link.append({'source':j, 'target':k, 'value':temp_value}) del df1 del df2 except: continue sankey = Sankey("EV供应商链统计",width=6000, height=700) sankey.use_theme('roma') #roma wonderland sankey.add( "EV供应商统计", node, link, line_opacity=0.2, line_curve=0.3, line_color='source', sankey_node_gap=13, is_label_show=True, label_pos="right", is_legend_show =False, label_text_size=11 ) sankey.render('EV供应商统计_All.html') del sankey sankey = Sankey("EV供应商链统计",width=6000, height=1500) sankey.use_theme('roma') #roma wonderland sankey.add( "EV供应商统计", node, link, line_opacity=0.2, line_curve=0.3, # line_color='source', sankey_node_gap=13, is_label_show=True, label_pos="right", is_legend_show =False, label_text_size=12 ) sankey.render('EV供应商统计_All_v2.html')
(之前是用plotly,后来发现pyecharts接口稍微简单些,其实都差不多,但plotyly可以一些特殊地图绘制比pyecharts来的精细,所以看绘图需求吧)
附上链接:https://plot.ly/python/ https://pyecharts.org/#/zh-cn/intro 用于查阅需要绘制的图的种类