概览
一个对象根据不同情况可以被划分成两种情况,当对象是一个非数组对象的时候,对象头,实例数据,对齐填充在内存中三分天下,而数组对象中在对象头中多了一个用于描述数组对象长度的部分
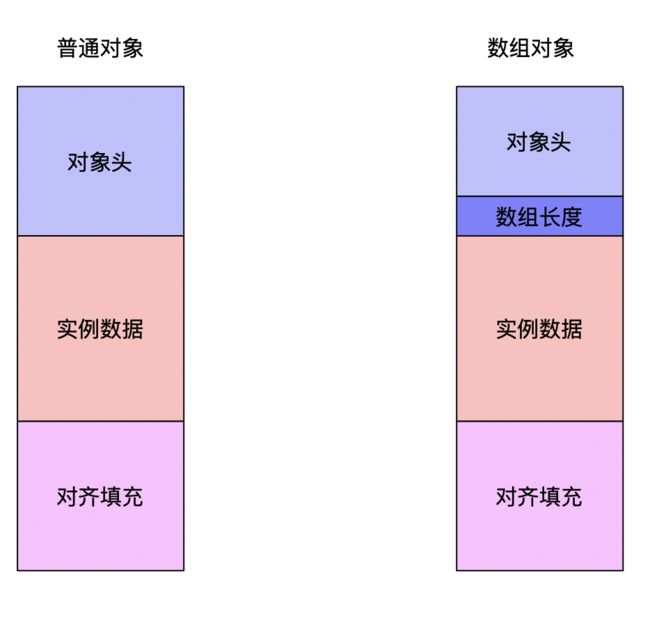
对象头
对象头分为两部分,第一部分称之为"Mark Word",第二部分是用于获取该对象类型的类型指针,如果是数组对象还包括记录数组长度的数据。
在不同的操作系统中,这些区域所占的内存也不同,在32位的系统中,MarkWord占用32bit的空间(也就是4字节)。类型指针和数组长度数据一样合作占用32bit的空间。
在64位的操作系统中,MarkWord占用64bit的空间,类型指针在不开启指针压缩(CompressedOOPs)的情况下是64bit(8 byte),而在开启指针压缩的情况下,仅剩32bit(4 byte)

Mark Word
这一部分存储的是对象自身的运行时数据,这一块儿内容的数据结构并不固定,它会根据对象的状态复用自己的存储空间,
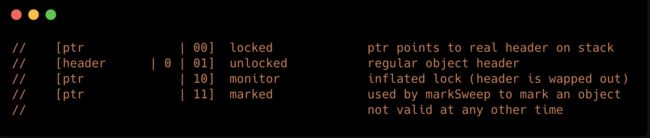
这是摘自markOop.hpp文件中的片段,其中表示了对象的以下五种状态:
| 标志位 | 偏向锁标识位 | 状态 |
|---|---|---|
| 01 | 0 | 无锁 |
| 01 | 1 | 偏向锁 |
| 00 | 无 | 轻量级锁 |
| 10 | 无 | 重量级锁 |
| 11 | 无 | GC Mark |
我们接下来接着去看MarkWord的结构:
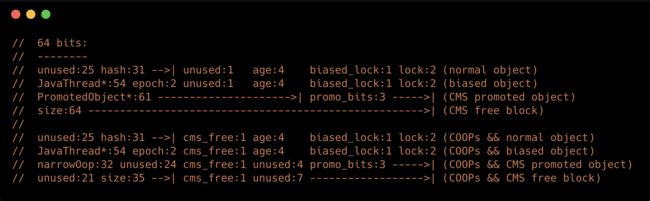
在这里我们可以看到,初始化的时候只是定义了无锁和偏向锁状态的结构(上半部分是没有开启COOPs-指针压缩的结构,下半部分是开启了指针压缩的结构),
当处于轻量级锁、重量级锁时,记录的对象指针,根据JVM的说明,此时认为指针仍然是64位,最低两位假定为0;当处于偏向锁时,记录的为获得偏向锁的线程指针,该指针也是64位;

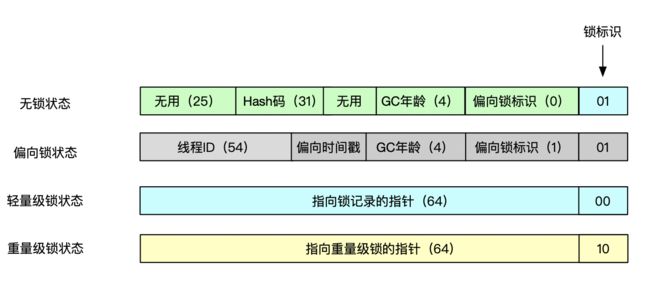
更多的内容我们就不再这里扩展了,根据反馈的情况,我会在后面并发编程中单开一篇来聊聊锁的进化之路。
类型指针
这个东西有时候会用到去确定该对象属于哪个类的实例,也有用不到的时候,这个要根据不同的虚拟机对于对象的定位实现算法的选择来进行(比如HotSpot JVM就使用该类型指针去获取该对象类型数据)
实例数据
实例数据是对象真正存储的有效信息,也是在程序代码中所定义的各种类型的字段内容,这里的字段内容不仅仅包括当前类的字段,也包括他的父类中所定义的字段。
这部分的存储规则遵循虚拟机分配策略参数和字段在Java源码中的定义顺序,HotSpot JVM默认的分配策略是long/double, int,short/char,byte/boolean,oops(普通对象指针,Ordinary Object Pointers)也可以理解为reference,关于指针压缩我们下节去说。
这里需要注意,在父类中定义的变量会出现在子类前,但是我们可以通过将CompactFileds参数设置为true,将子类中较小的变量插入到父类大变量的空隙中。
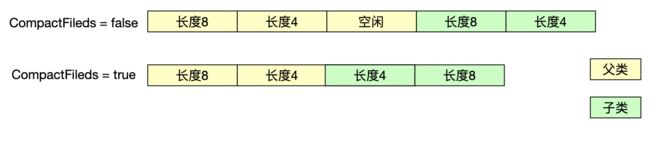
对齐填充
这部分内容并不是必须存在的,因为Hot Spot JVM中规定了对象的大小必须是8字节的整数倍,在C/C++中类似的功能被称之为内存对齐,内存空间都是按照 byte 划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是在访问特定类型变量的时候经常在特定的内存地址访问,这就需要各种类型数据按照一定的规则在空间上排列,而不是顺序的一个接一个的排放,这就是对齐。
内存对齐遵循两个规则:
假设第一个成员的起始地址为0,每个成员的起始地址(startpos)必须是其数据类型所占空间大小的整数倍
结构体的最终大小必须是其成员(基础数据类型成员)里最大成员所占大小的整数倍。
这里也就不难理解为什么JVM规定对象的大小必须是8字节的整数倍了,因为在64位系统下(不开启指针压缩),对象中存在很多占用8 byte的数据类型。但是同时也存在一些4 byte的数据类型,这时我们的Padding就起到了作用,去补充不满8 byte的部分,凑齐8的整数倍。
公众号
