这个是在WGAN基础上又由蒙特利尔的学者提出的改进训练的WGAN,并且给出了在NLP方面的例子,很厉害。
直接把GAN应用到NLP领域(主要是生成序列),有两方面的问题:
1. GAN最开始是设计用于生成连续数据,但是自然语言处理中我们要用来生成离散tokens的序列。因为生成器(Generator,简称G)需要利用从判别器(Discriminator,简称D)得到的梯度进行训练,而G和D都需要完全可微,碰到有离散变量的时候就会有问题,只用BP不能为G提供训练的梯度。在GAN中我们通过对G的参数进行微小的改变,令其生成的数据更加“逼真”。若生成的数据是基于离散的tokens,D给出的信息很多时候都没有意义,因为和图像不同。图像是连续的,微小的改变可以在像素点上面反应出来,但是你对tokens做微小的改变,在对应的dictionary space里面可能根本就没有相应的tokens.
2.GAN只可以对已经生成的完整序列进行打分,而对一部分生成的序列,如何判断它现在生成的一部分的质量和之后生成整个序列的质量也是一个问题。
近几篇重要的工作:
1. 为了解决这两个问题,比较早的工作是上交的这篇发表在AAAI 2017的文章:SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient, 16年9月就放上了Arxiv上面了,而且也公布了源代码。
利用了强化学习的东西来解决以上问题。如图,针对第一个问题,首先是将D的输出作为Reward,然后用Policy Gradient Method来训练G。针对第二个问题,通过蒙特卡罗搜索,针对部分生成的序列,用一个Roll-Out Policy(也是一个LSTM)来Sampling完整的序列,再交给D打分,最后对得到的Reward求平均值。
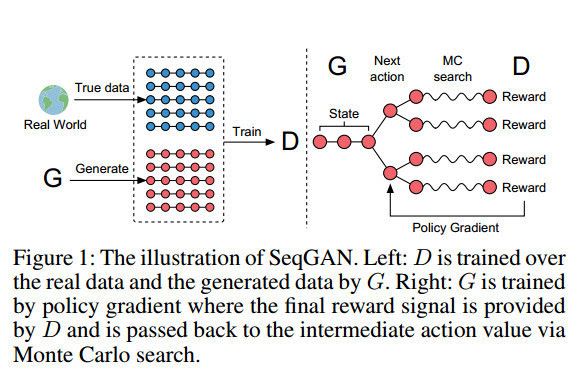
完整算法如图:

原文链接:https://arxiv.org/pdf/1609.05473v5.pdf
Github链接:LantaoYu/SeqGAN
2. 第二篇是C.Manning组大神Li Jiwei的文章:Adversarial Learning for Neural Dialogue Generation,用GAN和强化学习来做对话系统,如果我没有记错,这篇paper是最早引用SeqGAN的,有同学还说这篇是最早将RL用到GAN上的,主要是Jiwei大神名气太大,一放上Arxiv就引起无数关注。
如图,文章也是用了Policy Gradient Method来对GAN进行训练,和SeqGAN的方法并没有很大的区别,主要是用在了Dialogue Generation这样困难的任务上面。还有两点就是:第一点是除了用蒙特卡罗搜索来解决部分生成序列的问题之外,因为MC Search比较耗费时间,还可以训练一个特殊的D去给部分生成的序列进行打分。但是从实验效果来看,MC Search的表现要更好一点。
第二点是在训练G的时候同时还用了Teacher-Forcing(MLE)的方法,这点和后面的MaliGAN有异曲同工之处。
为什么要这样做的原因是在对抗性训练的时候,G不会直接接触到真实的目标序列(gold-standard target sequence),当G生成了质量很差的序列的时候(生成质量很好的序列其实相当困难),而D又训练得很好,G就会通过得到的Reward知道自己生成的序列很糟糕,但却又不知道怎么令自己生成更好的序列, 这样就会导致训练崩溃。所以通过对抗性训练更新G的参数之后,还通过传统的MLE就是用真实的序列来更新G的参数。类似于有一个“老师”来纠正G训练过程中出现的偏差,类似于一个regularizer。

原文链接:https://arxiv.org/pdf/1701.06547.pdf
Github链接:jiweil/Neural-Dialogue-Generation
3. Yoshua Bengio组在二月底连续放了三篇和GAN有关的paper,其中我们最关心的是大神Tong Che和Li yanran的这篇:Maximum-Likelihood Augmented Discrete Generative Adversarial Networks(MaliGAN),简称读起来怪怪的。。。
这篇文章的工作主要是两个方面:
1.为G构造一个全新的目标函数,用到了Importance Sampling,将其与D的output结合起来,令训练过程更加稳定同时梯度的方差更低。尽管这个目标函数和RL的方法类似,但是相比之下更能狗降低estimator的方差(强烈建议看原文的3.2 Analysis,分析了当D最优以及D经过训练但并没有到最优两种情况下,这个新的目标函数仍然能发挥作用)
2.生成较长序列的时候需要用到多次random sampling,所以文章还提出了两个降低方差的技巧:第一个是蒙特卡罗树搜索,这个大家都比较熟悉; 第二个文章称之为Mixed MLE-Mali Training,就是从真实数据中进行抽样,若序列长度大于N,则固定住前N个词,然后基于前N个词去freely run G产生M个样本,一直run到序列结束。
基于前N个词生成后面的词的原因在于条件分布Pd比完整分布要简单,同时能够从真实的样本中得到较强的训练信号。然后逐渐减少N(在实验三中N=30, K=5, K为步长值,训练的时候每次迭代N-K)
Mixed MLE训练的MaliGAN完整算法如下:

在12,梯度更新的时候,第二项(highlight的部分)貌似应该是logP(我最崇拜的学长发邮件去问过一作) 。至于第一部分为什么梯度是近似于这种形式,可以参考Bengio组的另一篇文章:Boundary-Seeking Generative Adversarial Networks
这个BGAN的Intuition就是:令G去学习如何生成在D决策边界的样本,所以才叫做boundary-seeking。作者有一个特别的技巧:如图,当D达到最优的时候,满足如下条件,Pdata是真实的分布,Pg是G生成的分布。
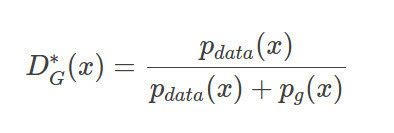
我们对它进行一点微小的变换:这个形式厉害之处在于,尽管我们没有完美的G,但是仍然可以通过对Pg赋予权重来得到真实的分布,这个比例就是如图所示,基于该G的最优D和(1-D)之比。当然我们很难得到最优的D,但我们训练的D越接近最优D,bias越低。而训练D(标准二分类器)要比G简单得多,因为G的目标函数是一个会随着D变动而变动的目标。
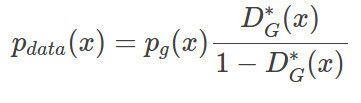
文章后面给出了如何求梯度的数学公式,这里就不贴了。
回到MaliGAN,作者给出了实验数据,比SeqGAN的效果要更好,看BLEU score.

原文链接:https://arxiv.org/pdf/1702.07983v1.pdf
4. 用SeqGAN做机器翻译,中科院自动化所在三月中旬放出了这篇文章:Improving Neural Machine Translation with Conditional Sequence Generative Adversarial Nets,这篇文章主要的贡献就是第一次将GAN应用到了NLP的传统任务上面,而且BLEU有2的提升。
这个模型他们称之为CSGAN-NMT,G用的是传统的attention-based NMT模型,而D有两种方案,一种是CNN based,另一种是RNN based,通过实验比较发现CNN的效果更好。推测的原因是RNN的分类模型在训练早期能够有极高的分类准确率,导致总能识别出G生成的数据和真实的数据,G难以训练(因为总是negative signal),
这篇文章的重点我想是4.训练策略,GAN极难训练,他们首先是用MLE来pretrain G,然后再用G生成的样本和真实样本来pretrain D,当D达到某一个准确率的时候,进入对抗性训练的环节,GAN的部分基本和SeqGAN一样,用policy gradient method+MC search,上面已经讲过了不再重复。但是由于在对抗性训练的时候,G没有直接接触到golden target sentence,所以每用policy gradient更新一次G都跑一次professor forcing。这里我比较困惑,我觉得是不是像Jiwei那篇文章,是用D给出的Reward来更新G参数之后,又用MLE来更新一次G的参数(保证G能接触到真实的样本,这里就是目标语言的序列),但这个方法是teacher-forcing不是professor forcing。
最后就是训练Trick茫茫,这篇文章试了很多超参数,比如D要pretrain到f=0.82的时候效果最好,还有pretrain要用Adam,而对抗性训练要用RMSProp,同时还要和WGAN一样将每次更新D的权重固定在一个范围之内。
原文链接:https://arxiv.org/pdf/1703.04887.pdf
5.最后3月31号放到Arxiv上的文章:Improved Training of Wasserstein GANs,WGAN发布之后就引起轰动,比如Ian在Reddit上就点评了这篇文章,NYU的又祭出了这篇,令WGAN在NLP上也能发挥威力。
在WGAN中,他们给出的改进方案是:
判别器最后一层去掉sigmoid
生成器和判别器的loss不取log
每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行
这里引用自知乎专栏:令人拍案叫绝的Wasserstein GAN - 知乎专栏
文章写得深入浅出,强烈推荐。
其中第三项就是机器翻译文章中也用到的weight clipping,在本文中,他们发现通过weight clipping来对D实施Lipschitz限制(为了逼近难以直接计算的Wasserstein距离),是导致训练不稳定,以及难以捕捉复杂概率分布的元凶。所以文章提出通过梯度惩罚来对Critic(也就是D,WGAN系列都将D称之为Critic)试试Lipschitz限制。
如图:损失函数有原来的部分+梯度惩罚,现在不需要weight clipping以及基于动量的优化算法都可以使用了,他们在这里就用了Adam。同时可以拿掉Batch Normalization。
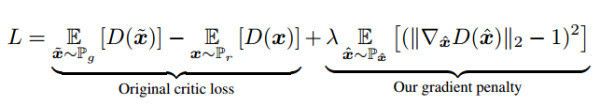
如图所示,实验结果很惊人,这种WGAN—GP的结构,训练更加稳定,收敛更快,同时能够生成更高质量的样本,而且可以用于训练不同的GAN架构,甚至是101层的深度残差网络。

同时也能用于NLP中的生成任务,而且是character-level 的language model,而MaliGAN的实验是在Sentence-Level上面的。而且前面几篇提到的文章2,3,4在对抗性训练的时候或多或少都用到了MLE,令G更够接触到Ground Truth,但是WGAN-GP是完全不需要MLE的部分。

原文链接:https://arxiv.org/pdf/1704.00028.pdf
github地址:https://github.com/igul222/improved_wgan_training
代码一起放出简直业界良心。
6. 3月31号还谷歌还放出了一篇BEGAN: Boundary Equilibrium Generative Adversarial Networks,同时代码也有了是carpedm20用pytorch写的,他复现的速度真心快。。。
最后GAN这一块进展很多,同时以上提到的几篇重要工作的一二作,貌似都在知乎上,对他们致以崇高的敬意。
原文参考:https://www.leiphone.com/news/201704/7IVQiiVMDR3XFfjt.html