Abstract
阿尔茨海默病(AD)是最常见的神经变性疾病之一,具有常见的前驱性轻度认知障碍(MCI)阶段,其中记忆丧失是主要抱怨,随着行为问题和自我保健不足逐渐恶化。然而,并非所有临床诊断患有MCI的个体都进展为AD。一部分患有MCI的受试者要么进展到非AD痴呆症,要么在MCI阶段保持稳定而不进展为痴呆症。尽管目前还没有治愈性AD的治疗方法,但正确识别MCI期患者继续发展AD的个体是非常重要的,以便在不久的将来可以获得治愈性治疗。同时,也非常希望能够正确识别那些没有AD病理的MCI阶段的患者,这样他们就可以免于不必要的药理学干预,这些干预最多可能不会给他们带来好处,更糟糕的是,不利的副作用会进一步伤害他们。此外,在这些非AD病例中识别认知障碍的原因可能更容易和更简单,因此正确识别前驱AD也会对这些个体有益。氟脱氧葡萄糖正电子发射断层扫描(FDG-PET)捕获大脑的代谢活动,并且这种成像模式已经被报道在发生结构变化之前识别与AD有关的变化。使用FDG-PET成像设计分类器的先前工作一直很有前景。由于深度学习最近已成为一种强大的工具来挖掘特征并将其用于准确标记给定图像的群体成员,我们提出了一种新型深度学习框架,使用FDG-PET代谢成像来识别MCI阶段的受试者症状前AD并将其与其他MCI患者(非AD /非进行性)区分开来。我们的多尺度深度神经网络获得82.51%的分类准确度,仅使用来自单一模态(FDG-PET代谢数据)的测量值超过了最近文献中发表的其他类似FDG-PET分类器。
Introduction
阿尔茨海默病(AD)占所有类型痴呆症的约50-75%,影响了65岁以上的9人中的1人(Kawas,2003; Alzheimer's and Association,2011)。其特征是进行性认知衰退,如记忆缺失,注意力和执行功能。虽然目前还没有治疗AD的治疗方法,但有几种有希望的药物化合物处于发展的后期阶段,预计很快就会有一个突破性的治疗方法。迄今为止被推测为导致疾病改善治疗缺乏成功的原因之一是无法正确识别轻度认知障碍(MCI)阶段的个体,这些个体将从那些发展AD的人发展为AD。由于其他原因导致MCI症状。当对那些MCI症状不是由于AD导致明显有希望的治疗被认为是失败的那些人施用时,AD的潜在有希望的治疗可能不会显示益处。在MCI阶段识别前驱AD患者的另一个原因是疾病早期的干预可能有助于延缓发病和/或降低面临完全AD的风险,而疾病过程中的干预措施可能减缓疾病,但在已经发生之后不能逆转病理引起的神经元损失。因此,在MCI阶段诊断为症状前AD是一项极其重要的任务,当治愈性治疗可用时,这将变得更加重要和紧迫。对于那些MCI是由AD以外的原因引起的人来说,这种诊断也很有价值,因为这些其他原因可能更容易和更容易识别和管理。
氟脱氧葡萄糖正电子发射断层扫描(FDG-PET)提供了大脑代谢活动的定量测量(Mosconi等,2010)。 AD中的脑区域代谢异常被认为发生在结构性脑变化发生之前(Jack等人,2010; Jagust等人,2006)。此外,区域代谢异常被认为是AD患者功能和认知能力下降的基础(Landau等,2011; Kawachi等,2006)。因此,FDG-PET被认为是AD症状前诊断的潜在工具,具有可接受的敏感性和准确性(Cheng等,2015; Davatzikos等,2011; Albert等,2011; Chen等。 ,2010)。以前的研究试图找出患有症状前AD的受试者,但取得了有限的成功(Cheng等,2015; Davatzikos等,2011; Suk等,2014)。尽管付出了相当大的努力,但是先前开发用于识别渐进式MCI的自动化工具的尝试导致精度有限(低于80%),如表2所示(Suk等人,2014; Young等人,2013; Zhu等人。 ,2014; Lange等,2016; Cheng等,2015)。
深度神经网络最近已经成熟,并且在为识别任务提出的机器学习方法中提供了一些最佳性能(He et al。,2016; Krizhevsky et al。,2012)。深度学习网络也被应用于最近识别AD相关的进展模式。例如,刘等人。训练了一个Stacked Autoencoder来学习隐藏表示,然后用softmax输出层进行分类(Liu et al。,2014),Suk et al。结合深Boltzmann机器和支持向量机来识别AD患者(Suk等,2014),Ortiz等。使用深度学习结构的集合来投票分类(Ortiz等,2016)和Payan等。应用3D卷积神经网络进行NC,MCI和AD科目的多类分类(Payan和Monana,2015)。此外,多尺度处理是物体识别模式挖掘的自然延伸(Zhang et al。,2007; Lowe,2004)。通过将图像下采样到不同的尺寸并在不同的分辨率下提取特征,这种方法也被证明可以提高深度神经网络的分类性能(Tang和Mohamed,2012)。
我们还要注意的是,先前发布的在AD中使用FDG-PET图像的非深度学习分类方法通常使用小的测试数据集,包括有限的ADNI数据库子集,或者通过少于一百个图像呈现它们的验证,于最近的回顾结果可见(Rice和Bisdas,2017)。最近的另一篇Cochrane评价报告还列出了总共14项研究(在所有这些研究中总共分析了421名受试者),其中每项研究仅对数十名受试者进行了研究(Smailagic等,2015a)。相比之下,本文的标志之一是我们对几乎所有可用的ADNI受试者(N = 1051)进行分析,这些受试者在研究中准备本手稿时同时具有结构MRI和FDG-PET图像。最近的评论(Rice和Bisdas,2017; Smailagic等,2015b)进行了以展示为基础的研究,展示了他们在较小数字(大约几十到几百)的结果。因此,我们的论文对迄今为止为该项工作发布的最大数据集提出了最全面的方法验证。其次,我们的论文将是第一个利用深度学习开发多尺度FDG-PET分类器的论文。这些观察结果支持我们提交的新颖性和全面性。
总的来说,该论文的主要贡献:(1)我们提出了一种新的多尺度深度神经网络框架,以学习AD病理学代谢变化的模式,作为正常对照(NC)代谢模式的判别; (2)我们发现,通过从NC和AD个体转移样本,深层结构可以在早期诊断任务中获得更好的判别能力; 3)我们证明了具有不同验证设置的集合多个分类器可以使所提出的方法更加稳定和稳健,并提高其分类性能。此外,我们对我们的方法进行了全面验证,分析了1051名受试者采取的代谢措施,这些受试者的质量控制要求严格,包括专家手动编辑所有分段以确保准确性。到目前为止,我们的研究可能是第一个利用如此大量FDG-PET图像的研究,因此,这些结果表明了普遍性的良好潜力。
Methods
我们的框架可以分为两个主要步骤:(1)图像预处理和(2)使用深度神经网络进行分类。 在图像处理步骤中,我们执行T1 MR图像的分割,包括将较大的感兴趣区域(ROI)细分为较小尺寸区域的粗到细方法,以及FDG-PET的共同配准 具有相同受试者的T1 MR图像的图像在这些局部区域中提取代谢测量。 在分类步骤中,我们利用在多尺度特征上训练的深度神经网络来学习AD病理学的模式,并使用显示MCI个体分类表现的大群体进行实验。
Materials
用于制备本文的数据来自公众可获得的阿尔茨海默病神经影像学倡议(ADNI)数据库(http://adni.loni.usc.edu)。 ADNI于2003年作为公私合作伙伴关系启动,由首席研究员Michael W. Weiner博士领导。 ADNI的主要目标是测试是否可以将连续MRI,PET,其他生物标志物以及临床和神经心理学评估结合起来,以测量轻度认知障碍(MCI)和早期阿尔茨海默病(AD)的进展。
在正在进行的纵向ADNI研究中招募的1051名受试者的FDG-PET图像和结构MRI被下载并包含在本文中。受试者分为四类,即(1)正常对照(NC),(2)稳定轻度认知障碍(sMCI)类,(3)进行性轻度认知障碍(pMCI)类,和(4)临床诊断的那些与阿尔茨海默病(AD)。 NC组(N = 304)是没有任何认知投诉的受试者,在整个ADNI研究中仍然保持NC。 sMCI组(N = 409)是在基线时诊断为MCI症状的受试者,并且在制备该手稿时的整个ADNI研究中继续保持为MCI(中位随访时间为3年)。 pMCI组(N = 112)的受试者在基线时被诊断为MCI并且进展至可能的AD,中位时间转换为1年,因此这些图像被前瞻性地标记以指示他们将来进展至AD。可能的AD组(N = 226)受试者临床诊断为在基线时具有AD,并且随后在整个ADNI研究中保持AD的临床诊断。具有诊断变化的受试者(例如NC进展至MCI,或MCI恢复至NC)被排除在拟议研究之外。表1中描述了这些受试者的人口统计学和临床信息。在第二行中,括号中的数字是男性和女性受试者的数量,而其余三行代表年龄,教育年份和MMSE(Mini-精神状态考试)得分。每行中从左到右的两个数字是所有受试者的平均值和标准偏差。http://www.adni-info.org上描述了ADNI受试者群组,NC,MCI和AD的临床诊断,图像采集协议程序和采集后预处理程序的详细描述。
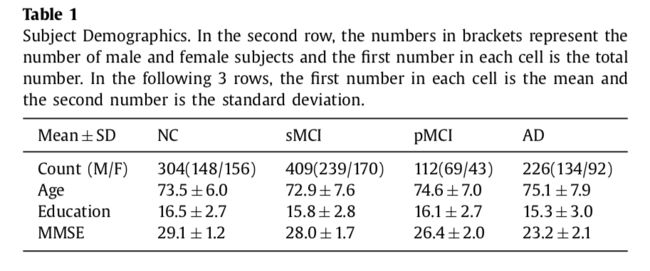
Image processing
最近的研究表明,深度学习的方法在解决许多图像识别问题方面是有效的,但大多数已发表的方法都归功于对大量数据样本(大约数百万)的训练。对于医学成像研究而言,这是一个相当大的障碍,例如,使用T1加权和/或FDG-PET成像等方式登记和扫描的受试者数量限制在最多几千人。因此,在这种较小的数据库上直接训练深度神经网络系统最有可能提供低于标准的分类精度和性能。然而,与典型的图像识别任务相比,图像可能具有高度的变异性和多样性,医学成像问题在更大程度上被标准化(相同的组织,例如,大脑),并且通常遵循严格标准化的协议,从而显示出不同受试者的成像异质性。这有利于减少充分训练所需的样本数量。事实上,我们在本文中的实验表明,随着ADNI提供的图像数量(1000个数量级),这种训练是实用的,可以带来出色的性能。
ROI segmentation
使用免费提供的具有默认参数设置的FreeSurfer 5.3软件包将每个T1结构MRI图像分割成灰质和白质(Fischl等,1999)。 Freesurfer进一步将灰质细分为85个皮质和皮层下感兴趣解剖区域(ROI)。尽管在处理ADNI等数据库中出现的各种解剖学配置时存在巨大的稳定性,但有些情况下Freesurfer输出可能包含错误,例如由于不正确的大脑掩模,皮质,皮层下或白质细胞包裹引起的错误。 - 大约10%的案例中的错误。由于此类错误可能会在测量中注入未知的可变性,因此我们通过训练有素且专业的神经病理学家对每个脑图像的每个FreeSurfer分段进行手动质量评估。此外,通过手动编辑校正脑膜,白质,皮质或皮质下分割中的任何错误,并重新运行Freesurfer,直到T1 MR图像分割变得准确,然后包括在分析中。
Patch parcellation
由Freesurfer提供的T1 MR图像分割中的每个ROI内的体素进一步细分为不同大小的较小区域,在此表示为“补丁”。由于每个ROI(例如枕叶皮层)可能非常大,因此在ROI中提取新陈代谢的平均值可能会导致由于AD导致的信号变化的灵敏度降低,因为在大量体素上进行平均。然而,如果没有先验知道可能发生变化的位置以及它们的定位程度,最佳方法是多尺度方法所建议的方法,其表明信号是从较小的子区域以多个尺度提取的(精细的)尺度)到较大的子区域(粗尺度),并且这些子区域可以同时用于检测由于疾病或病症引起的变化。因此,我们选择这些补丁的大小在每个ROI中包含500,1000和2000个体素。将每个ROI细分为自身以及许多不同大小的较小单元导致整个大脑的1488,705和343个总数补丁,分别针对每个规模。确定补丁的大小以保持足够的详细信息以及避免过大的特征维度,考虑到本研究中只有有限数量的数据样本。用于此细分的技术是先前发布的技术,其中每个ROI可通过k均值聚类算法使用其空间坐标进行聚类(Raamana等,2015)。该子细分执行一次,在所选模板中,代表性表面可视化显示在图1的左图中。由于ROI具有不同的大小,将每个ROI细分为预定的固定数量的补丁将导致他们的细分大小不同。因此,为了解决这个问题,我们首先预先定义每个补丁(500,1000,2000)中的体素数量,然后根据ROI大小计算每个ROI需要多少个聚类(k值)。这种方法具有以下优点:针对整个大脑中的不同ROI提供均匀的贴片尺寸密度(ROI中的贴片/ ROI中的体素),导致大脑中每个ROI的相同尺度的信号聚集。在模板T1 MR图像FreeSurfer分割进一步细分为多尺度贴片后,该模板MRI被注册到每个目标MRI空间,通过高维度高度精确的非刚性配准方法逐个贴片进行二元分割图像配准。 (LDDMM(Beg等,2005))被认为是领先的注册工具之一。利用分段模板和目标ROI之间的计算的注册图,所选模板的逐片分割向前传播到每个目标,其中这些通过在这些补丁内平均来用于FDG-PET信号聚合。
Coregistration
然后使用FSL-FLIRT程序(Jenkinson等,2002)基于归一化的互信息共同配准每个目标的FDG-PET图像和颅骨剥离的MRI扫描。 使用归一化相关作为成本函数,并将自由度(DOF)设置为12.目视检查每个共同配准的准确性,并且记录并校正共同配准中的任何错误。 然后利用估计的模态间配准图将目标MRI的斑块分割转移到目标FDG-PET域。
Normalization
提取每个贴片中FDG-PET图像的平均强度作为代谢特征。 之前已经注意到,从不同个体获取的FDG-PET图像的强度可能具有不同的“基线”值,使得在没有标准化的个体之间进行比较以校正该基线的不同是不一致的。 遵循该领域的标准方法,脑干是用于内部正常化的区域,因为它被认为最不可能受到AD的影响。 因此计算脑干区域中的平均强度并用于划分每个受试者的脑中所有其他ROI的代谢测量值。
Visualization of metabolism measures
用补片大小作为2000个体素提取的整个数据集的代谢特征在图1中显示为右图。该可视化中的每一列是一个主题,并且每行代表在主题上测量的相同补丁。 在列入NC,sMCI,pMCI和AD的临床诊断类别后,显示列(个体)。 这是所有1051个受试者同时采集的新陈代谢测量分布的精确可视化,并用于突出每个受试者的每个区域的一致代谢模式。 此外,由于任何预处理步骤中的潜在错误,任何个体的代谢测量中的任何异常值都可以在视觉上被检测到,因此这也用于对整个数据库中的测量进行视觉质量控制。
Multiscale Deep Neural Network
在图像处理之后,我们开发了一种多尺度深度神经网络(MDNN),它将多尺度贴片代谢特征作为输入,如图2所示。对于每个主体,有三个不同的输入特征向量,分别为1488,705和343用分别由500,1000和2000个体素组成的贴片提取的尺寸。 MDNN由四个深度神经网络(DNN)组成,第一阶段有三个,第二阶段有一个。 MDNN的培训分为三个步骤。首先,第一阶段的三个DNN独立地训练,具有在不同尺度下提取的代谢特征。然后将三个DNN的输出连接为输入向量,以在第二阶段训练DNN。最后,将MDNN的所有参数与作为输入的三种代谢特征一起调整。如果我们使用N来表示输入要素维度,则对于每个单个DNN,前两个隐藏层的大小设置为3N和3 / 4N,对于最后一个层,隐藏单位的数量设置为100为DNN在第一阶段,在第二阶段DNN为50。选择单元的数量以最大化在第一层中探索跨越不同贴片的非常广泛的可能隐藏相关性的机会,并逐渐减少后续层中的特征的数量以避免过度拟合。
Network training
对于每个单独的DNN,训练包含两个步骤,无监督预训练和监督微调,如图3所示。
无人监督的预训练。对于每个DNN,我们将其预先训练为堆叠自动编码器(SAE)。 Autoencoder是一种人工神经网络,用于学习输入数据的生成模型。它学习隐藏层(编码器)中的潜在表示,并重建输出层(解码器)中的数据。如果网络由多个编码器层组成,后跟几个解码器层,则它将成为堆叠自动编码器。对于输入数据x,隐藏层中的潜在表示可以显示为:y = s(W x + b),其中W是权重矩阵,b是偏差项,s是我们使用的激活函数在这项工作中纠正了线性函数max(0,x)。重建通过类似的变换发生:z = s(W'y + b'),其中我们用绑定权重W'= W T约束它。平方误差1/2 || x - z || 2用于计算反向传播的重建误差。如图2所示,对于每种特征,我们使用了三层SAE。我们不是一起训练所有隐藏层,而是使用贪婪的分层训练(Bengio et al。,2007),它一次训练一个隐藏层。
•监督微调。 在使用贪婪的逐层预训练初始化参数之后,我们仅保留三个编码器层并为每个DNN添加softmax输出层。 网络被监督微调为多层感知器(MLP)与标准的主题标签。 交叉熵用作梯度体面反向传播的损失函数,其定义为:
其中N是输入样本的数量,j表示样本类,xi,yi是特征向量和第i个样本的标签,h表示网络函数。
整个MDNN训练的成本函数与方程式相同。 (1)除了使用不同的输入特征向量。 所有训练步骤都采用相同的反向传播方法。 使用小批量梯度下降最小化成本函数(Bengio,2012); 将训练集随机分成几个小批量或子集,每批50个样本。 在每次迭代中,仅使用这些小批量中的一个用于最小化。 在将所有样本用于训练之后,我们重新排序训练集并将其再次划分,使得每个不同回波中的批次将不具有相同的样本。
Reducing chances of over-fitting
深度神经网络可能过度拟合给定的样本,因此,在没有任何正则化的情况下训练它将导致小的训练误差和可能的大的泛化误差。我们采用了两种技术来防止过度拟合:(1)辍学(Srivastava等,2014),以及(2)提前停止。
•辍学策略。在深度神经网络的训练中,辍学是防止过度拟合的流行策略。通过在每个隐藏层之后插入一个dropout图层,我们可以选择保留为下一层的单位百分比。对于训练,在每次迭代中随机丢弃一半隐藏单元,而保留另一半隐藏单元以将特征提供给下一层。为了测试,保留所有单元以对受试者进行分类。通过避免训练每个训练样本上的所有隐藏单元,这种正则化技术不仅防止了对训练数据的复杂协同适应,而且减少了计算量并提高了训练速度。
•早期停止策略。早期停止是我们应用于防止过度安装的另一种技术。当使用梯度下降等迭代方法训练深层架构时,改善网络与训练集的匹配将在开始时提高性能,但在某一点上,它将开始增加泛化误差,同时减少训练误差。为了防止这种情况,早期停止通常用于在过度拟合之前提供适当迭代次数的指导。在这项工作中,我们将训练数据随机分成训练集和验证集,网络参数仅通过训练集的数据进行优化,而验证集仅用于确定早期停止时间点:网络的迭代验证集的泛化误差最小。值得一提的是,训练集,验证集和测试数据是截然不同的;网络的性能仅在测试集上进行评估。
Instance-transfer learning
转移学习是缺乏数据样本时最常用的解决分类问题的方法之一(Pan and Yang,2010)。通过将与目标组相关的其他源组的实例引入到训练中,它扩大了训练集并用于提高分类准确性。通常需要优化算法来找到最相关的实例或重新加权来自其他组的实例(Zhang et al。,2014)。然而,在这项工作中,那些进展为AD的MCI可能处于潜在AD病理的早期阶段。此外,如图1的右图所示,在该pMCI组中发现了类似的代谢模式,如图1的右图所示。因此,AD组可以直接用于扩大pMCI训练集。考虑到这两个群体的相似性和相关性。另一方面,可以将NC个体添加到sMCI组以增加可能不具有AD病理学的个体库。交叉验证实验证明了我们使用这种方法背后的基本原理,即使用转移实例训练的网络显示出比没有特别在sMCI中使用转移实例的网络与用于检测前驱AD的pMCI分类任务相比更好的判别能力。在MCI集团中。
Ensemble classifiers
由于本研究中数据样本数量有限,特别是对于pMCI受试者,我们只能随机选择一小组数据进行验证,以保留足够的数据用于培训和测试。如此少量的验证样本可能无法代表整个数据集,并可能使网络偏向于在验证集上过度拟合。为了设计包含更好的鲁棒性,稳定性和普遍性的算法,选择了一个集合分类器框架。在这个框架中,我们培训了10个独立的网络,而不是培训一个网络,以便对最终的分类结果进行“投票”。从数据集中随机选择训练数据后,进一步分为10组。在训练阶段,9组用于训练网络,另一组用于验证。这些步骤重复10次,每组用于验证,从而产生10个不同的网络。在测试阶段,将测试数据馈送到每个网络,并生成属于每个类的样本的概率。对于每个样本,我们总结了来自10个网络的概率以确定分类结果。实验表明,集合多个网络使分类器更加鲁棒和稳定,并在统计上提高了分类精度。
Experimental setup
建议的网络是使用开源深度学习工具箱Tensorflow构建的(Abadi等,2015)。三个二元分类实验,(i)NC与AD,(ii)sMCI与pMCI和(iii)sMCI与pMCI以及来自NC和AD的转移学习,用于测试所提出的网络架构。进行十次交叉验证以测试每个训练网络的分类结果的普遍性。简言之,将可用数据集随机分成10个子集,其中9个用于训练,其余用于测试。为了防止过度拟合,选择训练数据的子集作为验证集并用于提供停止网络优化的指导(内部分类器优化循环)。如上所述,该训练过程重复十次,以训练十个不同的网络以“投票”以获得最终的分类结果。学习率分别设定为10-1和10-4,用于预训练和微调。使用准确度,灵敏度和特异性的标准测量来评估所提出的分类器的性能。
Results
表2中显示了交叉验证实验的平均准确度,灵敏度和特异性以及当前可用的现有技术方法的结果。 此外,我们还将结果与使用支持向量机(SVM)构建的标准分类器(Chang和Lin,2011)和使用主成分分析(PCA)的维数降低进行了比较(Wold等,1987) )在相同的多尺度功能上。 选择PCA特征向量的数量以保持95%的方差。 径向基函数用于SVM,因为它在分类任务中具有优越的性能。 表2的最后三行来自sMCI vs pMCI实验,其中实例从NC和AD组转移用于训练。
Multiscale classification
分类实验是通过使用包括500,1000和2000个体素的不同贴片尺寸以粗到精的方法在几个尺度上提取特征来进行的(表3),从而在整体中产生1488,705和343个贴片。 大脑,分别。 正如所料,分类结果对不同分类实验中不同的斑块大小敏感,表明感兴趣的信号位于不同的空间尺度。 这些结果列于表3中。
Ensemble classifier design
如方法部分所述,此处提供的分类结果来自分类器集合而不是单个分类器。在这个集合中,训练多个网络,然后对最终的分类结果进行“投票”。具有或不具有集合分类器的分类性能如图4所示。从左到右的三个图分别代表NC与AD,sMCI与pMCI和sMCI与pMCI的分类实验,其中分别来自NC和AD组的转移实例。 y轴绘制分类精度,x轴代表不同的实验。在x轴上,'ensemble'表示来自集合分类器的结果,数字1到10表示没有集合分类器的实验。在每个非整体实验中,我们还进行了10次交叉验证实验,但是我们不是训练10个网络对最终结果进行“投票”,而是随机选择验证集并训练单个分类器。图4中显示的结果显示了交叉验证实验的平均值和标准偏差。
Discussion
Comparison with state-of-the-art methods
我们将我们研究中获得的结果与标准SVM和PCA + SVM方法以及Suk等人最近提出的最新方法进行了比较。 (2014),Young等。 (2013),朱等人。 (2014),Lange等。 (2016)和Cheng等人。 (2015)关于NC与AD的分类,以及sMCI与pMCI(在MCI阶段检测前驱AD)。虽然不同研究中使用的数据并不相同,但它们都来自ADNI数据库,因此它们共享一个类似的获取和预处理程序,允许进行比较。
对于使用FDG-PET代谢测量的NC组与AD组的分类,我们提出的方法,精确度为93.58%,比之前公布的最佳方法高出1.28%(Zhu et al。,2014 )。此外,该结果还与之前使用多模式研究(FDG-PET +结构MRI)报道的95.35%的准确度相当(Suk等,2014)。为了将MCI阶段的个体区分为sMCI或pMCI组,我们提出的方法(没有转移学习)的表现明显好于(比现有的最先进方法高出至少10%)。此外,与将FDG-PET测量结果与其他方式相结合的多模式方法相比,使用单一模态(代谢FDG-PET)的方法对于sMCI与pMCI任务相比仍然高5.63%(Young et al。, 2013; Suk等,2014)。
使用在训练阶段从NC和AD受试者转移的实例,我们的方法在sMCI与pMCI分类任务中的准确性被发现为82.51%,这不仅比先前的最佳结果高出约10.91%(Cheng等人。,2015)使用单一模态,但也比以前的多模态方法高3.11%。即使只使用单一模态而没有NC和AD科目,我们的方法的准确性比Cheng等人的方法更高(2.15%)。 (2015)使用多种形式与NC和AD科目的转学习。对于使用相同多尺度特征的SVM和PCA + SVM实验,基于PCA的特征选择提高了SVM的分类性能。但与提出的深度神经网络相比,PCA + SVM的准确度降低了6%,这表明在这种情况下MDNN性能更优越。
总之,我们的实验表明,与过去的研究相比,我们提出的基于深度学习的方法显示sMCI和pMCI之间的分类准确性更高,无论是使用单一模式还是多模式研究(Suk等,2014)。无论从NC与AD实验获得的转移学习的应用如何,我们的准确性结果也是优越的(Cheng等,2015)。这些结果表明,提出的方法的优越性表明FDG-PET模式作为一项独立调查的潜力,无论转移学习的使用(Cheng et al.,2015; Suk et al.,2014)用于区分pMCI个体与在MCI个人中。
Multiscale classification
在AD与NC分类实验中发现,随着贴片尺寸的增加,精度普遍降低,表明AD的变化可能局限于较小的尺度,并且在使用较大尺寸的贴片时趋于平均。我们没有观察到其他分类实验的类似模式(sMCI vs pMCI和sMCI vs pMCI使用转移学习)。因此,发现使用较小尺寸的斑块来提取新陈代谢特征并不总能恢复较高的辨别力信息,并且可能sMCI与pMCI情况下的信号甚至更精细地定位,并且可能需要在每个ROI中使用甚至更小尺寸的补丁。然而,与单一尺度特征相比,使用所有多尺度特征的组合分类性能(包括从每个单一尺度特征获得的判别信息)产生了更高的精度结果。这表明在连锁多尺度特征上训练的网络(图2)仍然能够学习本文中使用的从小到大的补丁大小的隐藏模式。未来的工作可能包括在系统优化框架中学习每个分类实验中信号存在的规模,以找到最佳分类性能的最佳尺寸特征。
Ensemble classifier
图4中的结果表明,通过训练和验证集的不同划分,各个分类器的分类精度(中间图像的第二和第四个条)可能有多达8%的差异。 ,表明每个单一分类器的性能不稳定,普遍性降低。 在所有三个实验中,集合分类器的准确性高于单个分类器的平均值,这表明具有不同训练和验证集的分集的集合分类器可以产生更稳健和稳定的分类器,因此可以改善分类 性能更好的普遍性。
Conclusion
在本文中,我们使用多尺度贴片FDG-PET深度学习功能提出了一种新的AD早期诊断框架。所提出的框架利用转移学习方法和集合分类器策略来改善深度神经网络在区分sMCI和pMCI主体的任务中的性能。在1051名受试者的FDG-PET图像的大型数据库上进行的实验提供了支持三种断言的证据。 (1)所提出的方法,使用仅来自单一FDG-PET模态的特征,能够胜过在sMCI和pMCI分类任务中采用多模态特征的现有方法。 (2)所提出的网络可以从多尺度特征中学习判别模式,以提供具有更好判别性能的更健壮的分类器。 (3)使用不同验证集的集合多个分类器可以使网络更加健壮和稳定,并在统计上提高其分类性能。
对于未来的工作,将所提出的框架扩展到包含来自多种模态的信息是自然的,假设所得到的深度神经网络将从多个模态数据中学习更多信息,从而进一步改进所获得的分类准确度。尽管sMCI vs pMCI实验常用于验证近期研究(包括我们的研究)中方法的鉴别能力,但我们只能知道那些sMCI受试者在研究进展中时保持稳定并且可以转化为AD或其他神经退行性疾病。在将来。因此,临床诊断的sMCI受试者的基本事实可能不完全准确,因此可能在分类中引入噪声/偏倚。幸运的是,随着更多数据的收集,分类系统将更好地捕获这些和其他噪声和可变性来源,我们提出的深度学习集合分类器可能非常适合这种情况。
Acknowledgments
这项工作得到了国家科学工程研究委员会(NSERC),加拿大卫生研究院(CIHR),迈克尔史密斯健康研究基金会(MSFHR),加拿大大脑,太平洋阿尔茨海默氏症研究基金会(PARF)的支持。该项目的数据收集和共享由阿尔茨海默氏病神经影像学倡议(ADNI)(国家卫生研究院资助U01 AG024904)和DOD ADNI(国防部颁发号W81XWH-12-2-0012)资助。 ADNI由国家老龄化研究所,国家生物医学成像和生物工程研究所资助,并通过以下方面的大量贡献:AbbVie,阿尔茨海默氏症协会;阿尔茨海默氏症药物发现基金会; Araclon Biotech; BioClinica,Inc。;生物遗传; Bristol-Myers Squibb Company; CereSpir,Inc。; Cogstate; Eisai Inc。; Elan Pharmaceuticals,Inc。;礼来公司;欧蒙; F. Hoffmann-La Roche Ltd及其附属公司Genentech,Inc。; Fujirebio公司; GE Healthcare; IXICO有限公司; Janssen Alzheimer Immunotherapy Research&Development,LLC。;强生药业研发有限责任公司; Lumosity; Lundbeck公司; Merck&Co.,Inc。; Meso Scale Diag- nostics,LLC。; NeuroRx研究; Neurotrack技术;诺华制药公司;辉瑞公司; Piramal成像;施维雅;武田制药公司;和过渡治疗学。加拿大卫生研究院正在提供资金支持加拿大的ADNI临床站点。国家卫生研究院基金会(https://fnih.org)为私营部门的贡献提供了便利。受助组织是北加利福尼亚州研究和教育研究所,该研究由南加州大学阿尔茨海默氏症治疗研究所协调。 ADNI数据由南加州大学的神经成像实验室传播。
References
...