1. StateMachine寻找公共祖先的算法

S3为我们需要切换到的状态,那么寻找S3与S5的公共祖先,步骤如下:
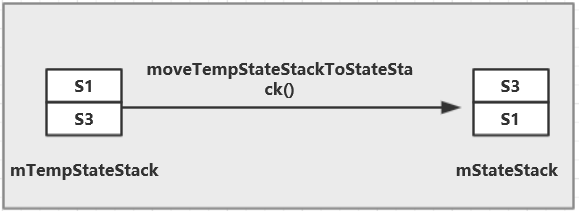
- 先将目的状态S3入栈mTempStateStack
- 根据目的状态S3往上回溯父节点,如果父节点未激活则入栈mTempStateStack,继续往上回溯,直至父节点为激活状态,处于激活状态的节点P1便是S3与S5的公共祖先。当然也存在没有公共祖先的情况,如目的状态为QuttingState。
入栈mTempStateStack是方便后续状态切换回调,找到公共祖先P1后,则回调用invokeExitMethods()从mStateStack的栈顶,向下依次调用相应State#exit方法,直至公共祖先P1,若无公共祖先,则全部调用exit方法。

接下来进入我们目的状态的enter流程,先将mTempStateStack整合至mStateStack,接着调用invokeEnterMethods从mStateStack的栈底到栈顶依次调用相应State的enter方法。
源码分析如下
StateInfo的关键数据结构:
//当前状态
stateInfo.state = state;
//当前状态的父节点信息StateInfo类型
stateInfo.parentStateInfo = parentStateInfo;
//当前状态是否激活,调用State#enter方法后会激活置为true
stateInfo.active = false;
发生时机:
在处理状态转换时,调用setupTempStateStackWithStatesToEnter(destState)中寻找公共祖先。
private void performTransitions(State msgProcessedState, Message msg) {
//省略状态机日志相关的代码
.............
//mDestState通过StateMachine#translationTo(IState state)赋值
State destState = mDestState;
if (destState != null) {
/**
* Process the transitions including transitions in the enter/exit methods
*/
while (true) {
if (mDbg) mSm.log("handleMessage: new destination call exit/enter");
/**找到mDestState与当前的初始状态的共同祖先,并设置mTempStateStack
*如果不存在共同祖先则返回null*/
StateInfo commonStateInfo = setupTempStateStackWithStatesToEnter(destState);
// flag is cleared in invokeEnterMethods before entering the target state
mTransitionInProgress = true;
//从当前初始状态到公共状态依次调用State.exit方法(不含公共状态)
//如果没有公共状态,则整个mStateStack中的State.exit都会被调用
invokeExitMethods(commonStateInfo);
.......
}
算法实现:
private final StateInfo setupTempStateStackWithStatesToEnter(State destState) {
/**
* Search up the parent list of the destination state for an active
* state. Use a do while() loop as the destState must always be entered
* even if it is active. This can happen if we are exiting/entering
* the current state.
*/
//逻辑上清空mTempStateStack,只是把栈的探头移动到0的位置,内容并未清除
mTempStateStackCount = 0;
StateInfo curStateInfo = mStateInfo.get(destState);
do {
mTempStateStack[mTempStateStackCount++] = curStateInfo;
curStateInfo = curStateInfo.parentStateInfo;
} while ((curStateInfo != null) && !curStateInfo.active);
if (mDbg) {
mSm.log("setupTempStateStackWithStatesToEnter: X mTempStateStackCount="
+ mTempStateStackCount + ",curStateInfo: " + curStateInfo);
}
return curStateInfo;
}
逻辑很简单,先将destState节点存入mTempStateStack,然后根据destState节点往上回溯,如果该节点为非激活状态则存入mTempStateStack,直到该节点的父节点为激活状态,如果没有公共节点那么往上回溯,返回值肯定是null。一旦没有公共祖先,那么invokeExitMethods()方法将会调用mStateStack栈中所有状态的exit方法,源码如下:
/**
* Call the exit method for each state from the top of stack
* up to the common ancestor state.
*从mStateStack的栈顶依次调用State.exit方法直至公共祖先(不含公共祖先)
*如果不存在公共祖先,即commonStateInfo为null,则整个状态栈都会调用exit
*/
private final void invokeExitMethods(StateInfo commonStateInfo) {
while ((mStateStackTopIndex >= 0)
&& (mStateStack[mStateStackTopIndex] != commonStateInfo)) {
State curState = mStateStack[mStateStackTopIndex].state;
if (mDbg) mSm.log("invokeExitMethods: " + curState.getName());
curState.exit();
mStateStack[mStateStackTopIndex].active = false;
mStateStackTopIndex -= 1;
}
}
2. 软件渲染模式下,invalidate导致父View重新渲染
在软件渲染模式下,子View的invalidate导致父View重绘有一个前提条件 —— 父View设置了backgroud
如果未设置background是不会导致父View重绘,只是会调用父View的dispatchDraw()来绘制child,并没有重绘自己。与调用invailidate同级的其他child,则会通过判断自己是否在需要绘制的dirty区域内,来决定自己是否需要重绘,在dirty区域之外则不进行重绘。
反观硬件加速绘制,无论父View是否设置backgroud,都不会重绘自己,所以这个问题可以转换为,为什么软件渲染在父View有设置了backgroud时,一定要重新绘制呢?
从源码的角度来看,只是因为设置了background之后,父View#mPrivateFlag中的SKIP_DRAW标志位为0(即false),这就导致了父View的重绘,但这也无法回答上面的问题,为何设置了background SKIP_DRAW标志位就一定要置为0呢?
参考老罗的博客,关于Dispaly List的文章,发现View的backgroud会被抽象为一个Background Render Node,具备自己的Display List,而软件渲染的子视图,则是先绘制在Bitmap上,然后在记录在父View的Display List当中。
目前关于问题2,原因并不知道,感觉background会被单独抽象成为一个Render Node会是一个突破口,因为它和从源码中提出的问题相关性很大。
3. native Heap内存模型
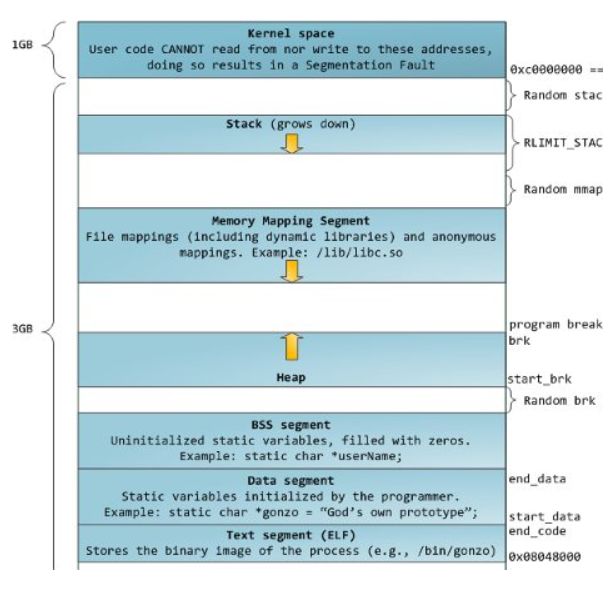
整体划分和JVM的内存划分差异不大,整体也主要包括堆区、栈区、以及方法区
逻辑层上的Heap模型

由图1可知,heap是可动态调整大小的,从低地址向高地址增长的,Linux通过一个break指针来表示当前已经映射分配的内存,break指针之后代表未映射的区域,访问这段区域程序会抛出bus error。rlimit则表示可动态映射分配的上限,可通过setrlimit和getrlimit方法对rlimit进行设置及访问。
要增加heap已映射区的大小,可调用如下方法,移动break指针
//直接移动break指针到指定位置
int brk(void*addr);
/**增量移动,返回上一次的break指针或者移动后的指针,
*但由于返回值并未明确指出是上一次的指针还是移动后的指针,
*所以返回值不能直接使用,
*需通过sbrk(0),来明确获取移动后的指针,
*这种情况下上一次指针和移动后的指针相等
*/
void *sbrk(intptr_tincrement);
图中带虚线的矩形代表页,Linux系统典型的内存页大小为4096B。由于操作系统是按页管理内存的,所以break指针可能并不位于页的边界。
物理层上Heap的组织实现
前面已经对heap整体划分有了一定了解,那么对于已经映射的区域,Linux是如何将他们组织起来,便于我们快速访问到我们分配的对象的呢?

原来是通过一个链表的组织起来的,链表中的节点包括meta-data和data区域,meta-data元数据区域,用来描述数据,如data区的大小,下一个块的指针,是否是空闲块,malloc函数返回的便是分配空间的pointer。
typedef struct s_block *t_block;
struct s_block {
size_t size; //data区大小
t_block next; //指向下一个块
int free; //是否是空闲块
}
查找分配
通过上面一小节了解到,在已经映射分配的区域中,是存在空闲块的,那么当我们重新malloc分配空间的时候,便可以复用那些空闲块,以节省内存。空闲块可能有多个,那么是如何决定复用那个空闲块的呢?
一般有二种算法:
First fit:从chunk链表头开始,依此向下查找空闲块,直到查找到一个size大于我们预期分配大小的空闲块,便返回。
Best fit:遍历整个chunk链表,使用数据区大小大于size且差值最小的空闲块作为此次分配的块。
Best fit具有较高的内存利用率(payLoad高),分配的空闲块非常接近我们想要的空间大小;而First fit具有更好的运行效率,不会遍历整个chunk链表。
参考文章:
Malloc_tutorial
Malloc函数实现原理