1 PySpark简介
Apache Spark是用Scala编程语言编写的。为了用Spark支持Python,Apache Spark社区发布了一个工具PySpark。使用PySpark,您也可以使用Python编程语言处理RDD。正是由于一个名为Py4j的库,他们才能实现这一目标。
这里不介绍PySpark的环境设置,主要介绍一些实例,以便快速上手。
2 PySpark - SparkContext
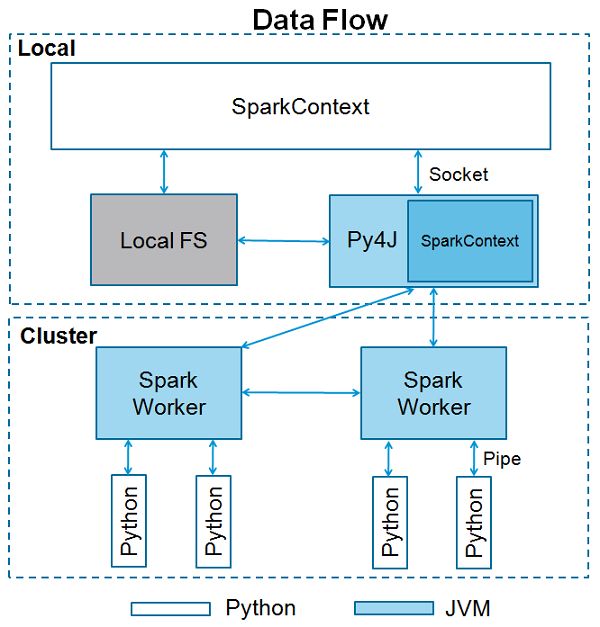
SparkContext是任何spark功能的入口点。当我们运行任何Spark应用程序时,会启动一个驱动程序,它具有main函数,并且此处启动了SparkContext。然后,驱动程序在工作节点上的执行程序内运行操作。
SparkContext使用Py4J启动JVM并创建JavaSparkContext。默认情况下,PySpark将SparkContext作为'sc'提供,因此创建新的SparkContext将不起作用。
以下代码块包含PySpark类的详细信息以及SparkContext可以采用的参数。
class pyspark.SparkContext (
master = None,
appName = None,
sparkHome = None,
pyFiles = None,
environment = None,
batchSize = 0,
serializer = PickleSerializer(),
conf = None,
gateway = None,
jsc = None,
profiler_cls =
)
以下是SparkContext的参数具体含义:
-
Master- 它是连接到的集群的URL。 -
appName- 您的工作名称。 -
sparkHome- Spark安装目录。 -
pyFiles- 要发送到集群并添加到PYTHONPATH的.zip或.py文件。 -
environment- 工作节点环境变量。 -
batchSize- 表示为单个Java对象的Python对象的数量。设置1以禁用批处理,设置0以根据对象大小自动选择批处理大小,或设置为-1以使用无限批处理大小。 -
serializer- RDD序列化器。 -
Conf- L {SparkConf}的一个对象,用于设置所有Spark属性。 -
gateway- 使用现有网关和JVM,否则初始化新JVM。 -
JSC- JavaSparkContext实例。 -
profiler_cls- 用于进行性能分析的一类自定义Profiler(默认为pyspark.profiler.BasicProfiler)。
在上述参数中,主要使用master和appname。任何PySpark程序的会使用以下两行:
from pyspark import SparkContext
sc = SparkContext("local", "First App")
2.1 SparkContext示例 - PySpark Shell
现在你对SparkContext有了足够的了解,让我们在PySpark shell上运行一个简单的例子。在这个例子中,我们将计算README.md文件中带有字符“a”或“b”的行数。那么,让我们说如果一个文件中有5行,3行有字符'a',那么输出将是→ Line with a:3。字符'b'也是如此。
注 - 我们不会在以下示例中创建任何SparkContext对象,因为默认情况下,当PySpark shell启动时,Spark会自动创建名为sc的SparkContext对象。如果您尝试创建另一个SparkContext对象,您将收到以下错误 - “ValueError:无法一次运行多个SparkContexts”。
在终端输入pyspark 启动PySpark Shell:
>>> logFile="file:////opt/modules/hadoop-2.8.5/README.txt"
>>> logData=sc.textFile(logFile).cache()
>>> numAs=logData.filter(lambda s:'a' in s).count()
>>> numBs=logData.filter(lambda s:'b' in s).count()
>>> print("Line with a:%i,line with b:%i" % (numAs,numBs))
Line with a:25,line with b:7
2.2 SparkContext示例 - Python程序
让我们使用Python程序运行相同的示例。创建一个名为demo.py的Python文件,并在该文件中输入以下代码。
from pyspark import SparkContext
logFile = "file:////opt/modules/hadoop-2.8.5/README.txt"
sc = SparkContext("local", "first app")
logData = sc.textFile(logFile).cache()
numAs = logData.filter(lambda s: 'a' in s).count()
numBs = logData.filter(lambda s: 'b' in s).count()
print("Line with a:%i,lines with b :%i" % (numAs, numBs))
然后我们将在终端中执行以下命令来运行此Python文件。我们将得到与上面相同的输出。
spark-submit demo.py

3 PySpark - RDD
在介绍PySpark处理RDD操作之前,我们先了解下RDD的基本概念:
RDD代表Resilient Distributed Dataset,它们是在多个节点上运行和操作以在集群上进行并行处理的元素。RDD是不可变元素,这意味着一旦创建了RDD,就无法对其进行更改。RDD也具有容错能力,因此在发生任何故障时,它们会自动恢复。您可以对这些RDD应用多个操作来完成某项任务。
要对这些RDD进行操作,有两种方法 :
- Transformation
- Action
转换 - 这些操作应用于RDD以创建新的RDD。Filter,groupBy和map是转换的示例。
操作 - 这些是应用于RDD的操作,它指示Spark执行计算并将结果发送回驱动程序。
要在PySpark中应用任何操作,我们首先需要创建一个PySpark RDD。以下代码块具有PySpark RDD类的详细信息 :
class pyspark.RDD (
jrdd,
ctx,
jrdd_deserializer = AutoBatchedSerializer(PickleSerializer())
)
接下来让我们看看如何使用PySpark运行一些基本操作,用以下代码创建存储一组单词的RDD(spark使用parallelize方法创建RDD),我们现在将对单词进行一些操作。
3.1 count()
返回RDD中的元素个数
----------------------------------------count.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "count app")
words = sc.parallelize(
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"
])
counts = words.count()
print("Number of elements in RDD -> %i" % counts)
执行spark-submit count.py,将会输出以下结果
Number of elements in RDD → 8
3.2 collect()
返回RDD中的所有元素
----------------------------------------collect.py - --------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "collect app")
words = sc.parallelize(
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"
])
coll = words.collect()
print("Elements in RDD -> %s" % coll)
执行spark-submit collect.py 输出以下结果
Elements in RDD -> ['scala', 'java', 'hadoop', 'spark', 'akka', 'spark vs hadoop', 'pyspark', 'pyspark and spark']
3.3 foreach(func)
仅返回满足foreach内函数条件的元素。在下面的示例中,我们在foreach中调用print函数,该函数打印RDD中的所有元素。
# foreach.py
from pyspark import SparkContext
sc = SparkContext("local", "ForEach app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
def f(x): print(x)
fore = words.foreach(f)
执行spark-submit foreach.py,然后输出:
scala
java
hadoop
spark
akka
spark vs hadoop
pyspark
pyspark and spark
3.4 filter(f)
返回一个包含元素的新RDD,它满足过滤器内部的功能。在下面的示例中,我们过滤掉包含''spark'的字符串。
# filter.py
from pyspark import SparkContext
sc = SparkContext("local", "Filter app")
words = sc.parallelize(
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
words_filter = words.filter(lambda x: 'spark' in x)
filtered = words_filter.collect()
print("Fitered RDD -> %s" % (filtered))
执行spark-submit filter.py:
Fitered RDD -> ['spark', 'spark vs hadoop', 'pyspark', 'pyspark and spark']
3.5 map(f, preservesPartitioning = False)
通过将该函数应用于RDD中的每个元素来返回新的RDD。在下面的示例中,我们形成一个键值对,并将每个字符串映射为值1
# map.py
from pyspark import SparkContext
sc = SparkContext("local", "Map app")
words = sc.parallelize(
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
words_map = words.map(lambda x: (x, 1))
mapping = words_map.collect()
print("Key value pair -> %s" % (mapping))
执行spark-submit map.py
Key value pair -> [('scala', 1), ('java', 1), ('hadoop', 1), ('spark', 1), ('akka', 1), ('spark vs hadoop', 1), ('pyspark', 1), ('pyspark and spark', 1)]
3.6 reduce(f)
执行指定的可交换和关联二元操作后,将返回RDD中的元素。在下面的示例中,我们从运算符导入add包并将其应用于'num'以执行简单的加法运算。说白了和Python的reduce一样:假如有一组整数[x1,x2,x3],利用reduce执行加法操作add,对第一个元素执行add后,结果为sum=x1,然后再将sum和x2执行add,sum=x1+x2,最后再将x2和sum执行add,此时sum=x1+x2+x3。
# reduce.py
from pyspark import SparkContext
from operator import add
sc = SparkContext("local", "Reduce app")
nums = sc.parallelize([1, 2, 3, 4, 5])
adding = nums.reduce(add)
print("Adding all the elements -> %i" % (adding))
执行spark-submit reduce.py:
Adding all the elements -> 15
3.7 join(other, numPartitions = None)
它返回RDD,其中包含一对带有匹配键的元素以及该特定键的所有值。
from pyspark import SparkContext
sc = SparkContext("local", "Join app")
x = sc.parallelize([("spark", 1), ("hadoop", 4)])
y = sc.parallelize([("spark", 2), ("hadoop", 5)])
joined = x.join(y)
final = joined.collect()
print( "Join RDD -> %s" % (final))
执行spark-submit join.py:
Join RDD -> [
('spark', (1, 2)),
('hadoop', (4, 5))
]
reference:https://www.tutorialspoint.com/pyspark/index.htm