本机搭建是建立在上一篇:在vm里搭建高可用Spark集群 里继续搭建的
十:安装Kafka
本机安装的是kafka_2.12-2.1.0.tgz 这个版本,本机是把kafka安装在node03,node04,node05 三个节点上组成一个kafka集群
10.1先把安装包上传到/usr/java目录下
解压: tar –xzvf /usr/java/kafka_2.12-2.1.0.tgz
赋权限: chmod 777 kafka_2.12-2.1.0
配置环境变量:
命令: vi ~/.bashrc
添加: export KAFKA_HOME=/usr/java/kafka_2.12-2.1.0
export PATH=$PATH:$KAFKA_HOME/bin
命令: source ~/.bashrc
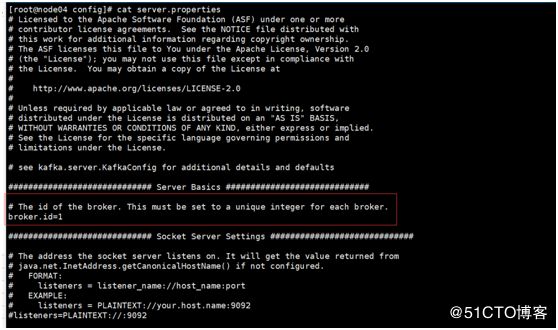
10.2在/usr/java/kafka_2.12-2.1.0/config路径下修改server.properties文件
主要修改三处:
broker.id的值,这个值不能重复,本机是把node05节点上设置的broker.id=0,node04节点上设置的broker.id=1, node03节点上设置的broker.id=2
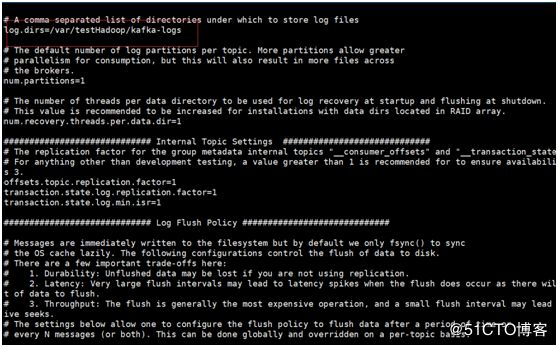
log.dirs 日志的路径本机是在放在/var/testHadoop/kafka-logs路径下,所以此处配置的:log.dirs=/var/testHadoop/kafka-logs
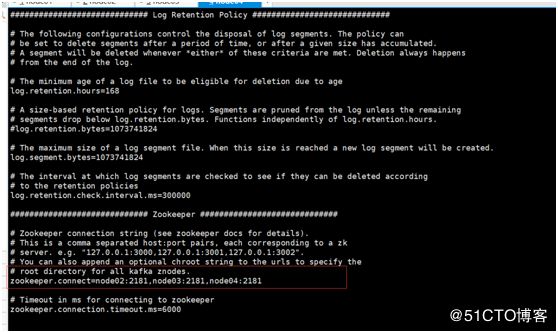
zookeeper.connect的路径,本机之前是在node02,node03,node04上搭建的zk集群,所以此处配置的:zookeeper.connect=node02:2181,node03:2181,node04:2181
10.3 node03,node04,node05 三个节点的kafka的server.properties都配置好后,分别启动kafka,启动命令:
在/usr/java/kafka_2.12-2.1.0/bin路径下执行命令: ./kafka-server-start.sh ../config/server.properties
使用脚本启动方式:
创建一个startKafka.sh名称的文本,编辑 vi startKafka.sh此文本
文本添加内容: nohup bin/kafka-server-start.sh config/server.properties> kafka.log 2>&1 &
保存退出此文本,然后直接执行./startKafka.sh 即可启动
使用后台方式启动:
同样的在/usr/java/kafka_2.12-2.1.0/bin路径下执行命令:
./kafka-server-start.sh -daemon ../config/server.properties
10.4 创建topic,此处创建一个名称为test01_topic的topic
在/usr/java/kafka_2.12-2.1.0/bin下执行命令:
./kafka-topics.sh –zookeeper node02:2181,node03:2181,node04:2181 --create --topic test01_topic –partitions 3 –replication-factor 3![]()
查看创建的或者说已有的topic,在node03,node04,node05下都可以查看
也是在bin路径下执行命令:
./kafka-topics.sh –zookeeper node02:2181,node03:2181,node04:2181 --list ![]()
10.5启动生产者命令:
本机是在node03节点上启动的,命令如下
也是在bin路径下执行命令: ./kafka-console-producer.sh –topic test01_topic –broker-list node03:9092,node04:9092,node05:9092
10.6启动消费者命令:
本机是在node05节点上启动的,命令如下
也是在bin路径下执行命令:
注意高版本的命令和低版本的命令不一样,本机使用的命令如下:
./kafka-console-consumer.sh –bootstrap-server node03:9092,node04:9092,node05:9092 –topic test01_topic![]()
低版本使用命令如下:
./kafka-console-consumer.sh –zookeeper node02:2181,node03:2181,node04:2181 –topic test01_topic
消费者命令后面如果跟家 --from-beginning的使用,带这个参数是从头消费,不带这个参数是实时消费
10.7 其它的一些命令:
可以在zookeeper bin下的zkCli.sh里进去可以看kafka信息
1)命令:ls /进来后有个consumers; 命令: ls /consumers 进里面后有个console-consumer-xxx; 命令: ls /consumers/console-consumer-xxx 进去有个offsets, 再进去(命令: ls /consumers/console-consumer-xxx/offsets),进来可以看到0,1,2的partition然后查看get /consumer/console-consumer-xxx/offsets/0 看里面内容;
2) ls /brokers/topics/test01_topic/
描述命令;
./kafka-topics.sh --zookeeper node02:2181,node03:2181,node04:2181 --describe
./kafka-topics.sh --zookeeper node02:2181,node03:2181,node04:2181 --describe --topic test01_topic
这个命令可以看到test01_topicde相关信息(包含副本在哪些节点 partition , leader ,replicas, isr)
查看组的状态:
[root@hadoop3 bin]# ./kafka-consumer-groups.sh --bootstrap-server node03:9092,node05:9092,node04:9092 --group groupFirst --describe
删除topic命令:
1)./kafka-topics.sh --zookeeper node02:2181,node03:2181,node04:2181 --delete –topic test_topic
操作完后可以 ./kafka-topics.sh --zookeeper node02:2181,node03:2181,node04:2181 –list 看到已经有删除标记了但还没有真正删除还可以继续消费
2)去每台节点上(元数据路径下 log.dirs)把元数据删掉 rm -rf test_topic
3)进入zkCli.sh 里删掉rmr路径。即: ls /brokers/topics/test01_topic里删掉 命令:rmr /brokers/topics/test_topic
4) 进入zkCli.sh ls /admin/delete_topics删除 rmr /admin/delete_topics/test01_topic
删除后重启即可
在bin路径下执行命令: ./kafka-run-class.sh kafka.tools.GetOffsetShell--broker-list node03:9092,node05:9092,node04:9092 --topictest_topic--time-l这个命令是查询test_topic生产了多少条数据,也可以理解offset值
[root@hadoop4 bin]# ./kafka-consumer-groups.sh --bootstrap-server node03:9092,node05:9092,node04:9092 --describe --group test_topic
可以查看出组内的消费
Zookeeper:存储原数据,broker,offset,topic, partition
十一:Flume的搭建
本机用的是apache-flume-1.8.0-bin.tar.gz版本,同时也是放在/usr/java路径下,本机的flume是安装在节点node06上的,主要是为了分开flume和kafka的
11.1解压: tar –xzvf apache-flume-1.8.0-bin.tar.gz
赋权限: chmod 777 apache-flume-1.8.0-bin
配置环境变量:
命令: vi ~/.bashrc
添加: export FLUME_HOME=/usr/java/apache-flume-1.8.0-bin
export PATH=$PATH:$FLUME_HOME/bin
命令: source ~/.bashrc
在路径/usr/java/apache-flume-1.8.0-bin/bin下执行 flume-ng version可以查看是否安装成功。
在路径/usr/java/apache-flume-1.8.0-bin/conf路径下flume-env.sh配置文件里的JAVA_HOME路径
11.2 在/usr/java/apache-flume-1.8.0-bin/路径下创建flumeConfig文件夹,在flumeConfig文件夹里创建文件sqoopDirToKafka.properties ,然后编辑sqoopDirToKafka.properties.内容如下:
Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#Describe/configure the source
a1.sources.r1.type = spooldir
#注解: /usr/java/flumeInputData/test01Topic .flume读取的是该路径下的数据文本
a1.sources.r1.spoolDir = /usr/java/flumeInputData/test01Topic
a1.sources.r1.inputCharset=UTF-8
a1.sources.r1.fileHeader = true
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = timestamp
a1.sources.r1.channels = c1
Describe the sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
#注解:要往kafka哪个topic里写入
a1.sinks.k1.topic = test01_topic
#注解:连接kafka集群的地址
a1.sinks.k1.brokerList=node03:9092,node04:9092,node05:9092
a1.sinks.k1.batchSize=2
a1.sinks.k1.requiredAcks=1
Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
Bind the source and sink to the channel
a1.sinks.k1.channel = c1
11.3启动flume,在/usr/java/apache-flume-1.8.0-bin/bin路径下
命令:
[root@node06 bin]# ./flume-ng agent -c /usr/java/apache-flume-1.8.0-bin/conf -f /usr/java/apache-flume-1.8.0-bin/flumeConfig/sqoopDirTafka.properties -n a1 -Dflume.root.logger=INFO,console
注意:此处命令中-n a1 这个地方的a1是sqoopDirToKafka.properties文件中a1.开头的即给配置文件起的别名。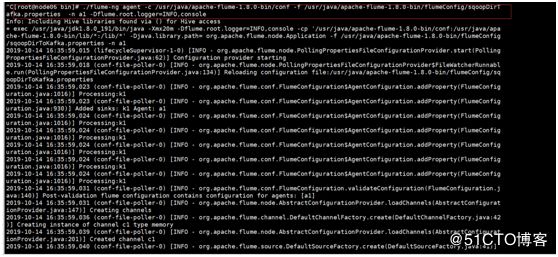
------------------------------------------------------------------------------------------------启动kafka集群,用idea开发工具,写kafka的生产者,消费者。在用idea开发kafka生产者,消费者前提是要配置本机的hosts(C:\Windows\System32\drivers\etc),由于代码里是用ip+端口的形式连接的,在kfaka集群中使用hostname,如果不配host会导致连接不上kafka集群。具体原因查看kafka源码(这个帖子不错可以看下: https://www.cnblogs.com/ldsggv/p/11010782.html)
生产者代码:
public class kafkaProduceTest01Topic {
public static void main(String[] args) throws InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.180.130:9092,192.168.180.131:9092,192.168.180.132:9092");/ props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);/
props.put("group.id","groupFirst");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer producer = new KafkaProducer<>(props);
for (int i = 0; i < 3000; i++){
String temp = "test"+i+" "+"tset"+i+" " +"kafka"+i;
producer.send(new ProducerRecord("test01_topic", String.valueOf(i), temp));
System.out.println("----test01_topic--" + i);
if(i%5 == 0){
Thread.sleep(2000);
} // Thread.sleep(2000);
}
producer.close();
}
}
消费者代码:
public class kafkaConsumerTest01Topic {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.180.130:9092,192.168.180.131:9092,192.168.180.132:9092");
props.put("group.id", "groupFirst");/ props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");/
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer
consumer.subscribe(Collections.singletonList("test01_topic"));
while (true) {
ConsumerRecords
for (ConsumerRecord
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}}
pom.xml配置:
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">;
kafakTest
com.test
1.0-SNAPSHOT
log4j
log4j
1.2.17
org.apache.logging.log4j
log4j-core
2.0-beta9
org.slf4j
slf4j-log4j12
1.7.25
org.apache.spark
spark-streaming-kafka-0-10_2.12
2.4.0
org.apache.spark
spark-core_2.12
2.4.0
org.apache.spark
spark-sql_2.12
2.4.0
org.apache.spark
spark-streaming_2.12
2.4.0
org.apache.spark
spark-hive_2.12
2.4.0
org.apache.kafka
kafka_2.12
2.1.1
org.apache.kafka
kafka-clients
2.1.1
com.thoughtworks.paranamer
paranamer
2.8
mysql
mysql-connector-java
8.0.13
src/main/java
src/test/java
org.apache.maven.plugins
maven-compiler-plugin
3.5
1.8
1.8