一、安装虚拟机及Ubuntu
虚拟机选择VirtualBox,操作系统选择Ubuntu的server版。
这两个软件都是免费的,可以在官网上用迅雷下载得到。
1 安装虚拟机
这个过程比较简单。直接双击以及下一步就搞定了。
最后记得在加载Ubuntu的iso之前设置下网络模式。在网卡2上记得配置Host-Only模式,这样可以让Windows通过SSH以及Samba去访问虚拟机。
另外还可以通过Ctrl+G来配置全局的网络环境。一般来说可以不用这么做。
2 安装Ubuntu
在virtualBox中加载ubuntu的iso后就可以启动安装程序。需要注意的是要选English语言,不然如果选中文简体会造成后面乱码的情况。虽然可能在SSH终端中不乱,但是为了省事还是选English吧。
另外在选择额外软件的时候记得把SSH和Samba都选上,不过如果错过了后面用adp-get安装也可以。
3 配置Ubuntu环境
通过安装和重启把Ubuntu装好后,接下来就是如何通过SSH以及Samba来使用ubuntu了。
3.1 配置eth1
eth0是让ubuntu通过虚拟机的NAT(网络地址转换)来直接访问外网。
eht1是让Windows通过Host-Only模式来连接Ubuntu,这样可以互相ping通并使用SSH以及Samba。
在ubuntu中ifconfig,可以看到eth1可能并没有启动起来。那么需要在/etc/network/interfaces中加入eth1的配置:设置为静态IP,并自动启动。
paul@spark-PC:~$ cat /etc/network/interfaces
# This file describes the network interfaces available on your system
# and how to activate them. For more information, see interfaces(5).
# The loopback network interface
auto lo
iface lo inet loopback
# The primary network interface
auto eth0
iface eth0 inet dhcp
#Virtualbox Host-only mode
auto eth1
iface eth1 inet static
address 192.168.56.101
netmask 255.255.255.0
#network 192.168.56.0
写好后再重新启动下网络:
paul@spark-PC:~$ sudo /etc/init.d/networking restart
此时再ifconfig,就可以看到eth1的网络信息了。
不过有可能你会很悲剧,发现上面这个命令在执行中显示stop fail,然后显然不能再次start,这时候你可以再试试sudo service networking restart,不过八九不离十还是不行。这时候索性来个痛快sudo ifdown -a && sudo ifup -a,这时候会显示网卡都关闭和打开好了。然后可能会发现依然不能正常和Windows通信。这时候再sudo reboot 吧,重启后应该就万事ok了。(再补充下,如果你一开始遇到这个问题,那么可能你需要以后每次打开虚拟机后都要reboot下,不然可能网络还是不通。)
然后可以在Windows中ping 192.168.56.101以及在ubuntu中ping 192.168.56.1看看互相是否都能ping通。
这时使用MobaXtermPro9建立SSH连接就可以和ubuntu在SSH上交互了。
3.2 配置Samba
配置Samba的用处在于后面可能会使用Windows的IDE。如果纯粹只是传输文件的话,其实MobaXtermPro已经可以轻松通过可视化sftp搞定了。
如果之前没有安装Samba,那么就sudo apt-get insall samba来安装下。
在自己的home目录中创建一个用于Samba分享的目录:
mkdir share/ //如果配置的共享目录不存在则创建
sudo chown -R paul.paul share/ //设置共享目录归属为 你的系统用户
sudo chmod 777 share/ //将共享目录属性设置为 777
说明:share你可以随便起个名字做为共享文件夹
为了以防万一:sudo cp /etc/samba/smb.conf /etc/samba/smb.conf.bak
然后在对/etc/samba/smb.conf修改,在文件最后添加:
[share]
path = /home/paul/share
available = yes
browseable = yes
public = yes
writable = yes
valid users = paul
create mask = 0700
directory mask = 0700
force user = paul
force group = paul
添加完毕后,再把用户添加进去
sudo smbpasswd -a paul //系统用户名字
重启samba服务器:
sudo testparm 验证一下配置参数有没有问题,如果有问题在回去修改
sudo /etc/init.d/samba restart(有可能在init.d下面没有samba这个服务。那么就换成smbd,或者用下面这两行命令)
sudo service samba restart
sudo service smbd restart
现在可以在Windows的映射网络驱动器中添加网盘了。
二、在Ubuntu下安装Spark
Spark基本不依赖于别的软件,只需要一个jdk7以及以上的环境就够了。当然后面用到Python以及Scala的时候还需要安装这两个。
1、安装jdk8
1、首先到Oracle官网上下载最新版的jdk,比如这次是jdk-8u121-linux-i586.tar.gz
2、将jdk-8u121-linux-i586.tar.gz拷贝到/usr/lib/jdk/目录下面,这里如果没有jdk文件夹,则创建该文件夹,命令:(可以使用Xmoba的sftp传输)
sudo mkdir jdk //创建文件夹jdk
复制到刚刚创建的目录后
sudo tar -zxvf jdk-7u51-linux-i586.tar.gz //解压缩文件
3、设置环境变量,用vim打开/etc/profile文件
sudo vim /etc/profile
在文件的最后面增加:
export JAVA_HOME=/usr/lib/jdk/jdk1.8.0_121
export JRE_HOME=/usr/lib/jdk/jdk1.8.0_121/jre
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
export CLASSPATH=$CLASSPATH:.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
保存并关闭文件
4、将系统默认的jdk修改过来
sudo update-alternatives --install /usr/bin/java java /usr/lib/jdk/jdk1.8.0_121/bin/java 300
sudo update-alternatives --install /usr/bin/javac javac /usr/lib/jdk/jdk1.8.0_121/bin/javac 300
sudo update-alternatives --config java
sudo update-alternatives --config javac
5、检测Java是否安装成功,
输入:
java -version
显示如下说明成功(具体jdk版本根据自己下载的可能不一样):
java version "1.8.0_121"
Java(TM) SE Runtime Environment (build 1.8.0_121-b13)
Java HotSpot(TM) Client VM (build 25.121-b13, mixed mode)
2、Spark的quick start
到了这里就开始真的接触使用spark了。最开始的quick start比较简单,就是把在官网上下载好的最新版本的预编译过的包安装解压出来就可以了。我自己下载的时候解压的最新版本是:tar -zxvf spark-2.1.0-bin-hadoop2.7.tgz
然后按照Spark官网的spark.apache.org/docs/latest/quick-start.html说明
进行一些操作,检查下是否有问题。比如./bin/run-example SparkPi 10 2>/dev/null如果能显示Pi is roughly 3.141059141059141就说明spark所需的环境都装好了。
3、 给Python配置pyspark
在单独使用python,代码中import pyspark时会遇到问题:不是无法加载pyspark就是py4j的库找不到。这需要在环境变量中告诉python这些包的路径。
在~/.bashrc中添加
export SPARK_HOME=/home/paul/tools/spark-2.1.0-bin-hadoop2.7
export PYTHONPATH=$SPARK_HOME/python/:$SPARK_HOME/python/lib/py4j-0.10.4-src.zip:$PYTHONPATH
这样Python中就可以任意使用了,而不是必须走spark的submit的bin了。比如don‘’t run your py file as:python filename.pyinstead use:spark-submit filename.py
接下来还要再研究用Java,(use Maven to compile an application JAR)
4、 在Windows中配置maven
为什么要在Windows中使用maven,主要是寄希望于win平台下编译产生的jar能够在ubuntu上提交给spark运行。
首先还是下载maven,我自己配合maven使用的IDE是IntelliJ IDEA。idea直接在官网下载最新版本即可,然后在http://idea.lanyus.com/上获得注册码完成注册。下载maven也是从官网下载最新版本然后解压。按照解压出来的README指示配置下环境变量就ok了。不过我自己还是按照网上的说法自己配的复杂一些的环境变量。
使用系统属性设置环境变量。
M2_HOME=C:\Program Files\apache-maven-3.5.0
M2=%M2_HOME%\bin
MAVEN_OPTS=-Xms256m -Xmx512m
添加字符串 “;%M2%” 到系统“Path”变量末尾
再运行mvn -version就可以看到mvn的一些基本信息了。
接下来开始在idea中创建maven的spark项目了。(可以在google中搜索spark maven看到很多示例)
首先在idea中选择新建一个project,然后在project中选择maven,但是在接下来的界面中不选择任何archetype,点击next。然后在GroupID中输入自己公司的名字,比如com.paulHome.app,artifactId输入firstSpark-App。版本号写1.0.继续next。project name和location随便填写,然后finish。
再紧接着显示出的pom.xml中在version之后仿照spark的quick start添加:

然后在选中src/main/java之后新建一个java类文件出来,比如取名叫firstSparkMain
然后输入spark的quick start的demo代码

期间先不要急着在idea中build,因为右下状态栏中显示还在下载一些依赖文件。这时候要等一等。如果不想等,那么可以cmd到这个工程目录下,用命令mvn package,然后你会发现还是需要下载,还是要等。(另外可以添加国内的镜像加速maven的下载依赖的速度。)
比如加载国内阿里的镜像:
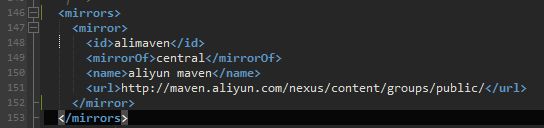
对于直接用命令mvn来说需要修改下载安装目录下的conf目录中的settings.xml文件。把mirror的配置修改为上面图片中的信息。对于使用idea来说,可以在file->setting中搜索maven。然后修改user settings file为修改后的xml,或者干脆使用自己下载的maven。不管哪种设置只要是把修改的setting配置上去就可以了。
这些搞定后,就可以通过命令行mvn package或者idea的build来生成jar了。(我这边由于第一次使用idea所以在scheme和代码的字体格式上也做了修改。)
使用命令行mvn是在工程目录下面的target目录下就生成了firstSpark-app-1.0.jar
使用idea是需要先在file->project structure->Artifacts中“+”来添加一个jar生成方式。然后通过build->build Artifacts..就在out目录下生成了一个firstSparkApp.jar(不过这个文件非常大有80M,比mvn生成的大不少)
至此这部分工作就大功告成了。接下来就是把jar放到ubuntu上运行了。
(第一次使用maven和idea:感觉maven太伟大了,idea比起eclipse来说也更有意思些)
5、在ubuntu的spark下运行
将生成的jar拷到ubuntu中,然后按照spark的quick start中的描述来运行:
比如./spark-2.1.0-bin-hadoop2.7/bin/spark-submit --class "firstSparkMain" --master local[4] firstSparkApp.jar
或者./spark-2.1.0-bin-hadoop2.7/bin/spark-submit --class "firstSparkMain" --master local[4] firstSpark-app-1.0.jar
第一个是idea生成的80多M的jar,第二个是mvn生成的只有3K多的jar。这两个都能正常运行,结果为:Lines with a: 62, lines with b: 30 暂时没有搞明白这两个jar的差别是啥。