在现代企业应用中,有很多应用和系统需要在生产环境中使用批处理来执行大量的业务操作。那么如何实现高效的、稳定的批处理任务就变得比较重要了。
本篇将介绍如何构建企业级批处理应用,以及如何选择具体的实现,包含标准、框架等。然后会着重介绍java平台下的几种实现,譬如jee7里包含的jsr-352、spring-batch、easy-batch。

批处理是什么
企业应用中经常需要以极高的效率自动地对海量数据信息进行各种复杂的业务逻辑处理。执行这种操作通常需要根据时间事件(如月末统计,通知或信件),或是定期处理那些业务规则超级复杂、数据量非常庞大的业务,也可能是从内部/外部系统抓取到的各种数据。在这个过程中一般需要格式化、数据校验、以事务的方式进行存储。企业中每天处理的事务量多达数十亿,这类工作就是批处理。
批处理应用有以下几个特点
非交互式、面向批处理、长时间运行
数据或计算密集型
顺序或并行执行
即时,计划或按需执行
批处理的流程分三个特定的阶段
读数据,数据来源于不同的存储或消息队列
业务处理,格式化、合并、转换等
归档结果数据,将输出结果写入不同的存储或消息队列
批处理设计原则
将对在线服务架构影响降到最低,尽可能使用公共模块
尽可能简化单个批处理应用中的逻辑
尽可能在数据存储的地方处理这些数据
尽可能少使用io这样的资源,多使用内存
监控应用程序io,避免不必要的物理io
在同一个批处理不要做两次一样的事
尽可能预先分配足够的内存
尽可能的加入数据校验以保证数据完整性
尽可能早地在模拟生产环境下使用真实的数据量,进行计划和执行压力测试
批处理包括
常规批处理
并发批处理
并行批处理
分区批处理
批处理健壮性需求
监控,可以监控执行中的状态
跳过,可以在任务执行遇到异常或者故障时候,进行选择性的跳过
任务重启,任务如遇到卡在某一步的时候,可以试着重启的方式继续从故障点开始往后执行
重试,在遇到某个异常的时候,可尝试重试来完成任务要求
技术选型
上文对批处理有了一些了解,那么我们该如何去实现呢?选择自己开发这样一套涵盖上述方方面面的框架,还是选择开源的框架、或者也有的Java EE支持部分?既然要选择,就应该明晓哪些点是你所关注的部分,以下介绍一些点以备选择参考。
可测试性,是否可以更方面对每个环节进行测试
组件化,是否具备一套完备的组件支撑
可观察性,是否方便监控各种状态
社区化,是否有良好的社区支持,产品更迭速度,方便遇到问题能够有较好的支持
可伸缩性,比如Multi-threaded、Partitioning、Parallel 、Remote 的支持
可配置性,是否支持良好的xml配置、以及java annotation等
可扩展性,比如对启动、重启任务有更多的扩展接口支持
几种实现
JSR-352、Spring Batch,Easy Batch、JBatch IBM (Glassfish, JEUS)、JBeret (Wildfly)都有一套对batch processing的实现,本文仅对Spring Batch的架构、决策器、伸缩性(批处理选项)、健壮性等方面进行介绍。
Spring Batch
SpringSource与Accenture合作开发了Spring Batch
Spring Batch借鉴了JCL(Job Control Language)和COBOL的语言特性
Spring Batch一款优秀的、开源的大数据量并⾏处理框架
Spring Batch可以构建出轻量级的健壮的并⾏处理应⽤,⽀持事务、并发、流程、监控、纵向和横向扩展,提供统⼀的接口管理和任务管理
Spring Batch 3.x对jsr-352有支持。
分层架构
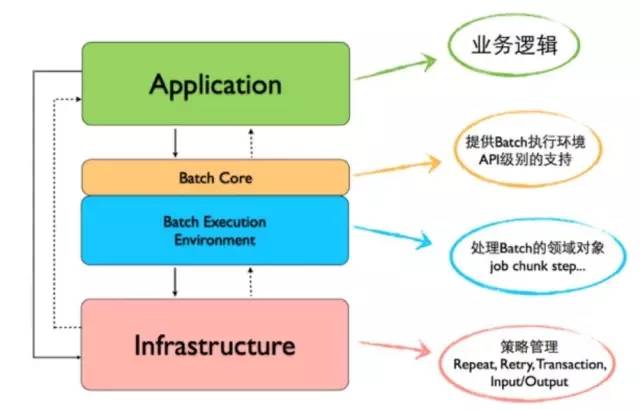
基础设施层,主要提供策略方面的支持,比如输入、输出、事务、重试等
批处理执行环境,主要提供批处理需要各种领域对象,比如Job、Step等
批处理核心组件,主要提供给应用层需要的api支持
业务应用层,开发各式的批处理业务
上下文
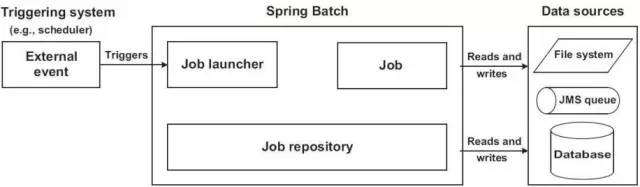
外部控制器调用JobLauncher启动一个Job,Job调用自己的Step去实现对数据的操作,Step处理完成后,再将处理结果一步步返回给上一层,这就是Batch处理实现的一个简单流程。
执行过程
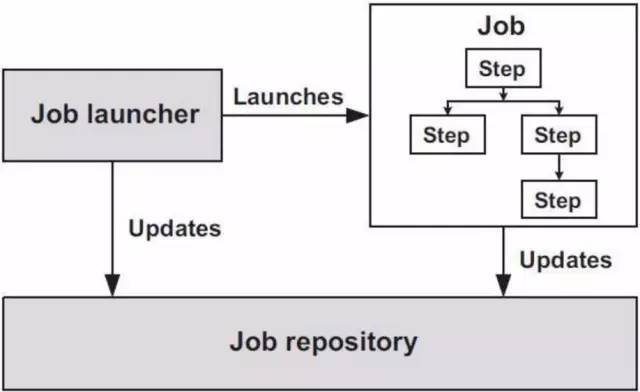
说明如下:
每个Batch都会包含一个Job。Job就像一个容器,容器里装了若干个Step,Batch中实际干活的也就是这些Step,至于Step干什么活,无外乎读取数据,处理数据,然后将这些数据存储起来(ItemReader用来读取数据,ItemProcessor用来处理数据,ItemWriter用来写数据) 。JobLauncher用来启动Job,JobRepository是上述处理提供的一种持久化机制(它为JobLauncher,Job,和Step实例提供CRUD操作)。
简单实现样例:
commit-interval="1">
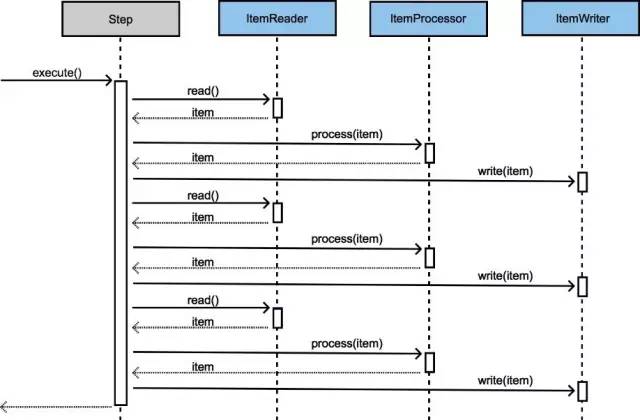
上面是一个最基本的配置,包含了批处理流程中的三个阶段,其处理流程如下图:
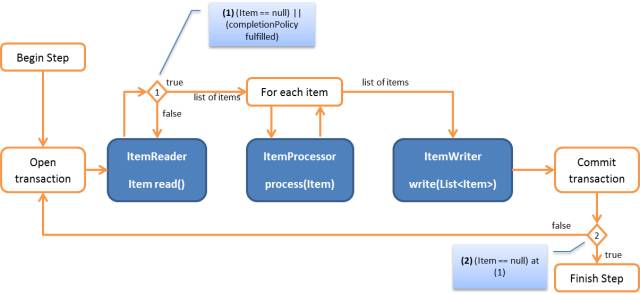
从特定的数据源取出数据的时候,read()操作每次只读取一条记录,之后将读取的这条数据传递给processor(item)处理,框架将重复做这两步操作,直到读取记录的件数达到batch配置信息中”commin-interval”设定值的时候,就会调用一次write操作。然后再重复上图的处理,直到处理完所有的数据。当这个Step的工作完成以后,或是跳到其他Step,或是结束处理。
详细的处理流程示意图:
批量提交次数为1,commit-interval="1"。
下面介绍具体组件。
领域对象
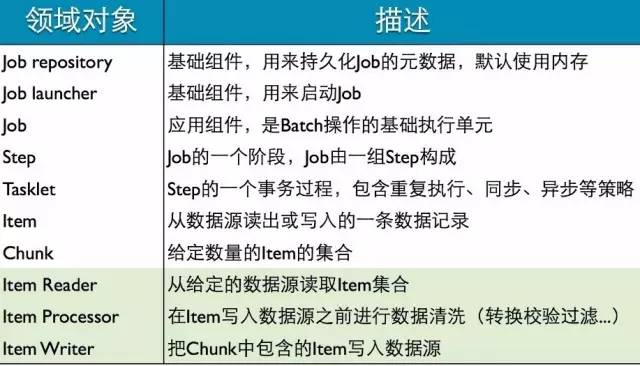
Job
Job -- 由⼀组Step构成,完成Batch数据操作的整个过程
Job Instance -- 特定的运行时Job实例,由Job launcher运行
Job Execution -- 某个Job实例的执⾏信息,包括执⾏时间、状态、退出代码等
Job实例和执⾏数据、参数等元数据信息都由Job repository进⾏持久化
启动Job, jobLauncher.run(demoJob, jobParameterBulider.toJobParameters());
JobParameters
JobParameters,就是Job运行时的参数。可以表示不同的JobInstance和给job传参数。
在启动job时,设置参数的key/value即可。
jobLauncher.run(job, new JobParametersBuilder()
.addString("inputFilePath", "/tmp/index.txt").toJobParameters()
如代码所示,参数inputFilePath传给Job了,在Job中如果需要使用参数信息,可以使用Spring注入的方式传给不同的使用对象。
需要设置Bean的scope属性为step。这是Spring Batch的一个后绑定技术,就是在生成Step的时候,才去创建bean,因为这个时候JobParameter才传过来。如果加载配置信息的时候就创建bean,这个时候JobParameter的值还没有产生,会抛出异常。
JobParametersIncrementer
同一个Job在batch启动后被多次调用的时候,需要创建一个新实例。JobParametersIncrementer接口提供了getNext方法,可以为parameters添加一个自增的值,以区分不同的Job实例。RunIdIncrementer就是Spring Batch框架提供一个实现类。使用方法如下:
class="org.springframework.batch.core.launch.support.RunIdIncrementer"/>
RunIdIncrementer的getNext方法实现如下:
public JobParameters getNext(JobParameters parameters) {
if (parameters == null) {
parameters = new JobParameters();
}
long id = parameters.getLong(key, 0L) + 1;
return new JobParametersBuilder(parameters).addLong(key, id).toJobParameters();
}
由代码可以看出,通过id值加一的方式来保证了每次创建的jobInstance的唯一性。
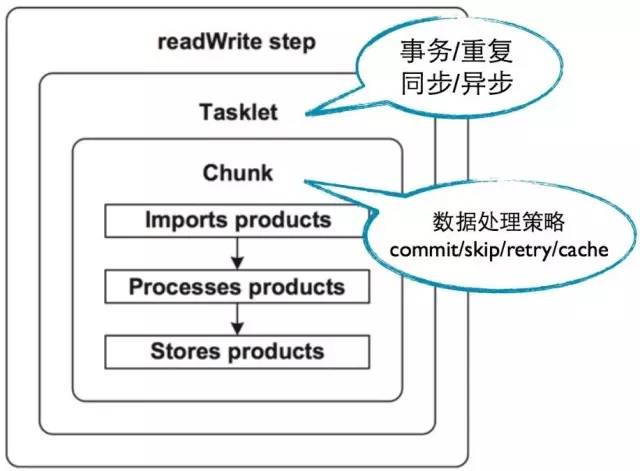
Step
Step是Job的一个执行阶段
Step通过tasklet和chunk元素控制数据的处理策略
一组Step可以顺序执行,也可以根据条件分段执行
Step的执⾏数据同样由Job repository进行持久化
DataSource
File
XML
Database
Message(JMS、AMQP)

决策器
前文的样例部分介绍了一步步执行的顺序Job,那么如何按Step执行结果来选择后续的Step呢?这里介绍的Decision就是一种按分支来执行的Job。如下图所示,可以看到返回为SKIPPER时候跳到generateReport这个Step,其他的都直接跳到clean这个Step。
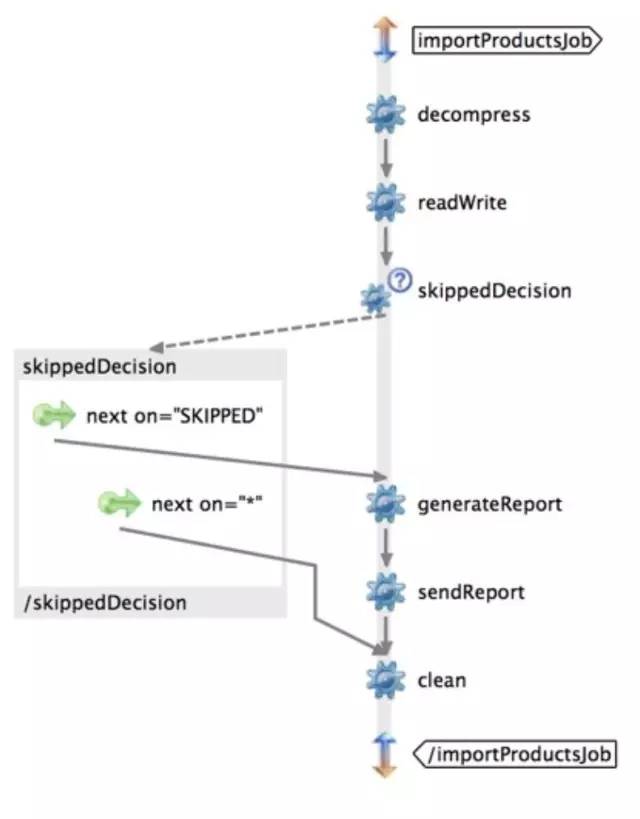
配置如下:
监控
Spring Batch提供了4种监控⽅式:
直接查看Job repository的数据库信息,所有的Batch元数据都会持久化到数据库中
使用Spring Batch提供的API自⼰构建监控数据
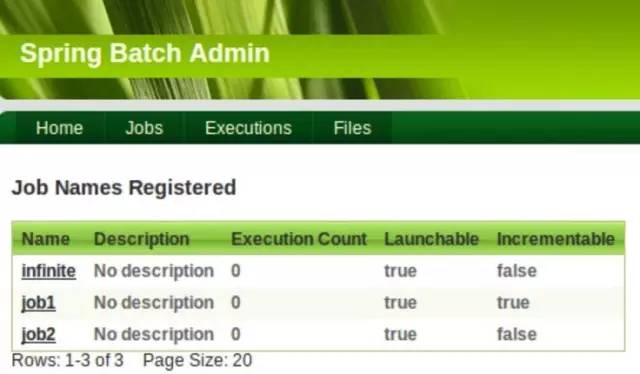
使用Spring Batch Admin,通过web控制台监控和操作Job
使用JMX的方式
spring batch admin提供的控制台:
健壮性
主要包含重启、跳过、重试等。
重启(restart)
在某个job执行发生异常时,可能执行完成了某些步骤,期望重启相同参数的该次job,就可以用restart参数来进行设置。
可配置参数allow-start-if-complete来设置开启重启,start-limit设置重启限制次数
重启相同job参数的job launch
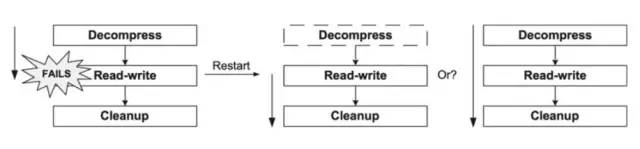
配置如下:
跳过(skip)
再发生非致命异常时候,比如某些值不符合格式要求,程序检查发生异常时。这样的情况一般选择设置跳过即可。
配置如下:
class="org.springframework.batch.item.file.FlatFileParseException" />
重试(retry)
发⽣瞬态异常,当发⽣瞬态失败的时候进行重试(例如遇到记录锁的情况),一般在Chunk的Step和应用程序中进行配置或处理。
配置如下:
commit-interval="5" retry-limit="3" skip-limit="3" >
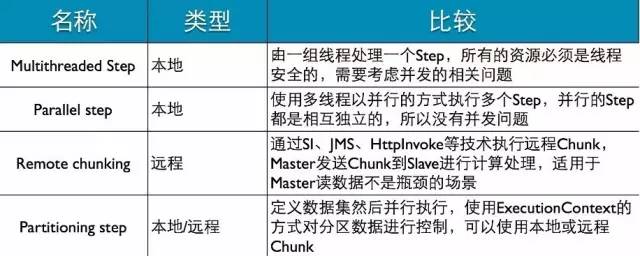
伸缩性
Spring Batch支持Multi-threaded、Partitioning、Parallel 、Remote四种伸缩方式。
Multi-threaded方式
单线程执行情况
前文已有部分介绍,当批量提交次数为1的情况。批量提交次数为多个, commit-interval="3"见下图。
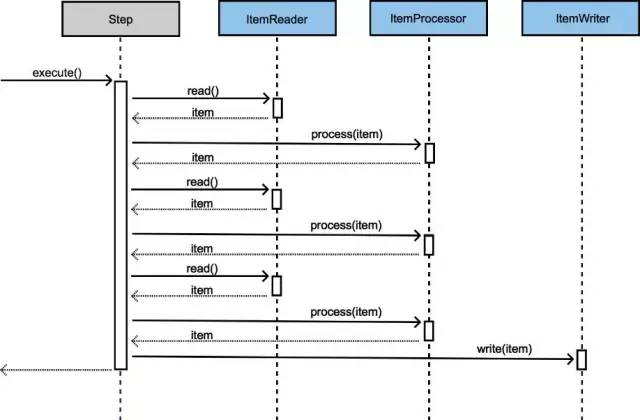
多线程方式
多个线程并行执行chunk。
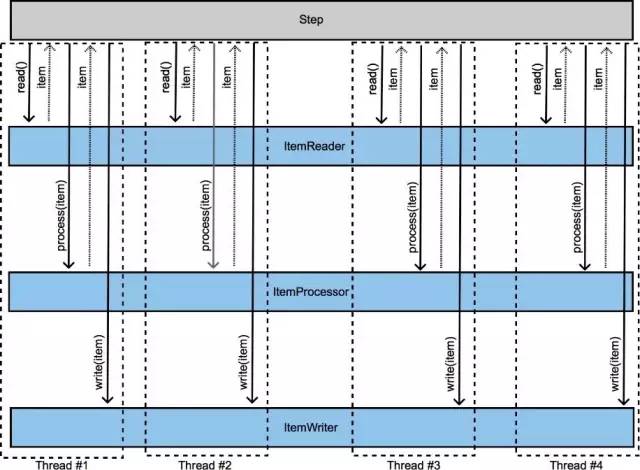
配置如下:
commit-interval="1000">
线程池的配置
需要注意的是,在多线程Step中,需要确保Reader、Processor和Writer是线程安全的,否则容易出现并发问题。Spring Batch提供的大部分组件都是非线程安全的,他们都保存有部分状态信息,主要是为了支持任务重启。
因此,使用多线程Step的核心任务是实现无状态化,例如不保存当前读取的item的cursor,而是同item的flag字段来区分item是否被处理过,已经被处理过的下次重启的时候,直接被过滤掉。多线程Step实现的是单个Step的多线程化。
Partitioning方式
分区主要包含:
数据分区
分区处理
方式基本上包含:
Local Partitioning
Remote Partitioning
Spring Batch提供了一个同一台机器上的Handler实现,在同一机器上创建多个Step Execution。
Local Partitioning
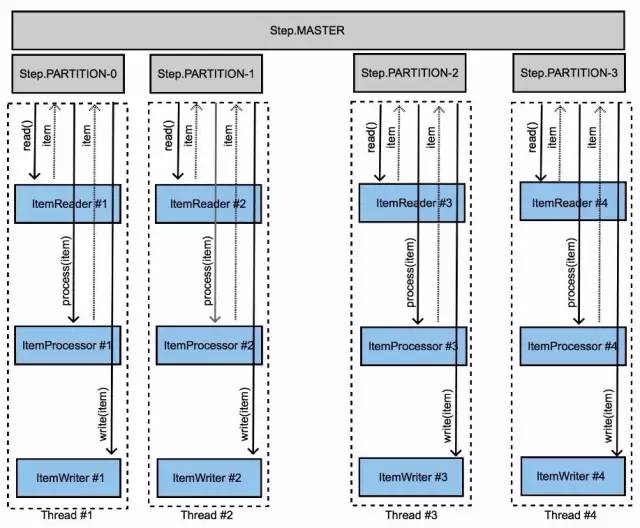
配置如下:
processor="itemProcessor" commit-interval="1" />
Remote Partitioning
处理远程分块来执行的方式外,在远程分块的同时还可以加上分区来实现远程分块分区的实现。
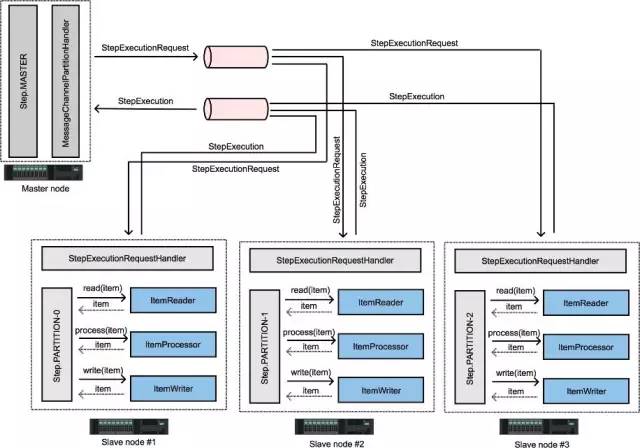
详细的实现以及配置就不做说明了,主要是用到spring integration来做消息集成。
Remote
使用远程分块的Step被拆分成多个进程进行处理,多个进程间通过中间件实现通信。
下面是一幅模型示意图:
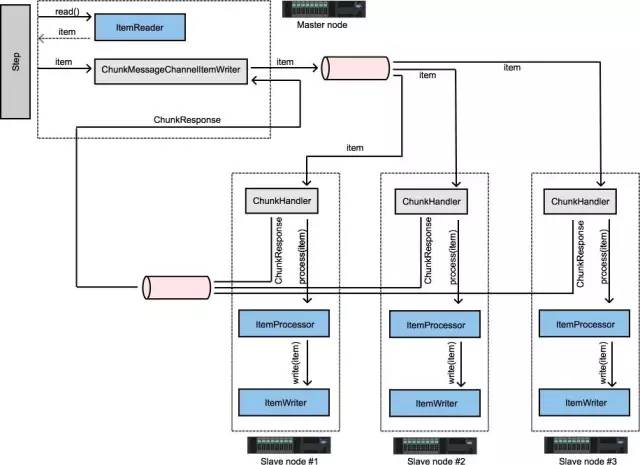
Master组件是单个进程,从属组件(Slaves)一般是多个远程进程。如果Master进程不是瓶颈的话,那么这种模式的效果几乎是最好的,因此应该在处理数据比读取数据消耗更多时间的情况下使用(实际应用中常常是这种情形)。
Parallel
需要并行的程序逻辑可以划分为不同的职责,并分配给各个独立的step,那么就可以在单个进程中并行执行。并行Step执行很容易配置和使用,如下图所示:
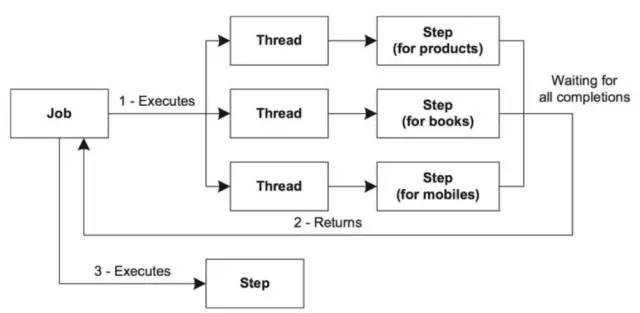
配置如下:
commit-interval="1000">
commit-interval="1000">
四种方式比较
前面对四种方式的实现方式和图示已做了简单介绍,下面我们再次看看四种方式的应用上的差异,做一个比较。
写在最后
以上为笔者在使用过程中的心得体会。目前spring batch 3.x 已涵盖了批处理的多方面的内容,包含对jsr-352也有较好的支持、也提供了丰富的接口,易于扩展,且上手相对容易,可是对annotation的配置方式支持不够全,期望后续的版本能够有改进。
参考:
选择正确的批处理实现
Horizontal and Vertical Scaling Strategies for Batch Applications
Spring Batch Behind the Scenes
本文作者:杨涛(点融黑帮),目前在点融网架构组从事应用架构相关工作。对微服务和docker技术有较多的实战经验。