Output输出
在程序或者内存中处理完的数据,大多时候都要输出,或者重定向输出到其他地方,可以是另外一个线程输入,缓冲池,文件等等。大多数情况下程序或者业务都有这样的需求,输出同样也是占用计算机资源的一种处理过程。那么就看看java中对字符和字节的输出是如何进行处理的呢?其实多数输出类都可以与上面描述的输入类进行类比,非常相似,只是将输入变成输出而已。
OutputStream字节输入流
就如同InptuStream是流向程序的字节流般,OutputStream则是从程序或者内存中流向外部资源文件,网络,数据库等等的字节流。通过IPO这个流程,就能将一端输入源中的字节流动到程序中进行处理,然后再将处理后的字节流又写入其他输出源。数据从哪里来,到哪里去,这个需要清楚知道。下面通过字节输出流的类图来大致看看有那些子类和那些应用场景:
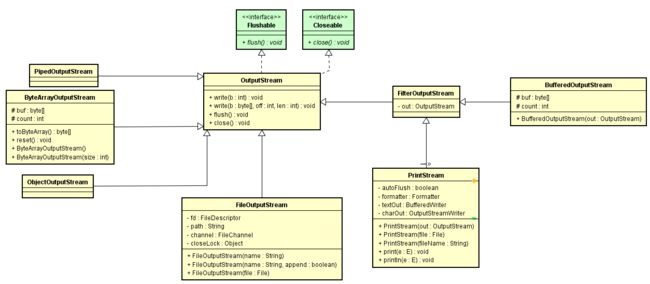
从图中的基类OutputStream可以看到,作为一个字节输出流,具有那些基本的功能特性:
public abstract void write(int b) ;//将一个字节写入到输出流中
public void write(byte b[]) ;//将b字节数组中数据写入到字节输出流中
public void write(byte b[], int off, int len);//将b中指定长度字节写入到输出流中
public void flush();//刷新输出缓冲区
public void close();//关闭输出流
可以看到,作为字节输出流,我们可以通过write方法将需要的字节数据,写入到字节输出流中,那么当我们调用close或者强制使用flush刷新缓冲区的时候,多数情况下,就可以将字节输出流输出到磁盘源资源文件中。在输出流中,我们需要注意的flush机制,这个是与输入流很大的不同。而像输入流中的针对文件,线程,使用缓冲区等使用场景都有对应的操作类,而flush是针对输出流的概念。
看看文件字节输出流的基本使用:使用FileOutputStream连接输出文件资源句柄,然后将字节数据写入buf字节输出,再将这个字节数组中数据写入文件输出流中,当调用write方法后,就会将字节输出流输出到文件中。当双击打开文件,会对这些字节进行解码,得到写入的原始字符串。
@Test
public void outputStreamTest(){
FileOutputStream fos;
try {
//设置字节流输出源文件,false代表不追加写入文件,全部重新写入
fos = new FileOutputStream("C:/Users/XianSky/Desktop/output.txt",false);
String str = "hello";
byte[] buf = str.getBytes();//要写入文件的字节数据
System.out.println(System.getProperty("file.encoding"));//UTF-8
System.out.println(Charset.defaultCharset().name());//UTF-8
System.out.println("写入字节数:>>"+buf.length);//5个字节,每个英文对应一个字节
fos.write(buf, 0, buf.length);//字节流根据系统编码后,触发真正的磁盘写入
System.out.println();
// fos.flush();
fos.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
通过源代码,大致看看FileOutputStream是如何将字节数据输出到文件中的:
//FileOutputStream.java
/*
* 通过该文件字节输出流构造器中的初始化配置可以知道,
* 将文件描述句柄FileDescriptor初始化完成,并检查文件数据写入方式,是否是追加写入。
* 然后对文件资源的多线程加上锁,防止多个线程同时对该文件进行读写操作。
* 最后,通过native本地方法open来进行与操作系统交互,打开指定的文件资源,触发真正的磁盘写入。
*/
public FileOutputStream(File file, boolean append)
throws FileNotFoundException
{
String name = (file != null ? file.getPath() : null);
SecurityManager security = System.getSecurityManager();
if (security != null) {
security.checkWrite(name);
}
if (name == null) {
throw new NullPointerException();
}
if (file.isInvalid()) {
throw new FileNotFoundException("Invalid file path");
}
this.fd = new FileDescriptor();
this.append = append;
this.path = name;
fd.incrementAndGetUseCount();
open(name, append);//native方法
}
/*
* 在上面通过open与操作系统交互连接文件操作句柄后,
* 就能通过内地方法writeBytes将b字节数组中的字节数据
* 写入到文件中。
*/
public void write(byte b[], int off, int len) throws IOException {
Object traceContext = IoTrace.fileWriteBegin(path);
int bytesWritten = 0;
try {
writeBytes(b, off, len, append); //native方法
bytesWritten = len;
} finally {
IoTrace.fileWriteEnd(traceContext, bytesWritten);
}
}
//底层将字节写入文件的方法,触发真正的磁盘写入实现
private native void writeBytes(byte b[], int off, int len, boolean append)
throws IOException;
可以看到,对文件的输出操作,会涉及到资源的加锁,与操作系统的交互,因为磁盘上文件是操作系统进行管理的,可以在native本地方法中,调用操作系统对文件的操作api,这样我们就能将程序与输出文件连通,就能往这个通道中写入字节数据,最后输出到文件端中,完成对文件触发真正的磁盘写入 。。。
当程序中处理的数据比较大和多的时候,利用字节缓冲区来对文件的写入效率会更快,节省每次写入对操作系统资源的占用与协同花费的时间与资源。
这样,可以只是通过一次操作系统调用,打开输出文件,完成对文件真正的磁盘写入。就像河上的一条桥一样,固定住这个连通通道,我们就能将大量的输出,每次按照固定长度,从一端运输到另外一端,当所有的数据都运输完成之后,就可以关闭这座桥,而不是每次运输一次数据就打开关闭这座桥一次。
@Test
public void bufferedOutputStreamTest() throws Exception{
//每次写入,是追加到文件最后
OutputStream os = new FileOutputStream("C:/Users/XianSky/Desktop/output.txt",true);
BufferedOutputStream bos = new BufferedOutputStream(os);
String[] src = {"heihei","haha","xixi"};//通过这个字符数组模拟大量数据,每次只是将一个字符字节写入到缓冲区
byte[] buf = new byte[1024];
/*
* 注意,这里每次调用write方法后,都是将src中的每个字符串
* 的字节数据写入到bos内部的缓冲区中,并没有直接写入到文件
* bos缓冲区的默认大小是8192个字节=8k。
*/
for(String s : src){ //每次最多运输1024个字节到缓冲区
buf = s.getBytes();
bos.write(buf, 0, buf.length);
buf = null;
}
/*
* 当所有要输出的字节数据,都成功写入到bos的字节缓冲区后,
* 通过显示调用flush或者close方法,都一次性将bos中
* 缓冲区的字节数据输出写入到文件中。
*/
bos.flush();
bos.close();
}
当在flush方法处打断点测试时候,上面循环将字符数组数据转换成字节写入到BufferedOutputStream的缓冲区中时候,人为打开输出文件,发现其实还并没有数据在文件中。当调用flush或者close后,再次打开文件就发现数据已经被写入了。缓冲区默认大小是8192个字节,下面通过源代码看看这个缓冲输出类是如何写入字节数据的:
public
class BufferedOutputStream extends FilterOutputStream {
protected byte buf[];//缓冲区
protected int count;//缓冲区有效字节个数
public BufferedOutputStream(OutputStream out) {
this(out, 8192);//默认8k字节缓冲区大小
}
...
//带有缓冲区的字节输出流的写入方法
public synchronized void write(byte b[], int off, int len) throws IOException {
if (len >= buf.length) {
/*
* 若是要写入字节缓冲的字节数量大于缓冲区数量,
* 则先刷新缓冲区,然后通过内部关联的无缓冲区功能的OutputStream的write方法,
* 一次性的将字节数据写入文件,触发真正的磁盘写入。
* 这样就清空了缓冲区数据,并且将大量数据写入到文件中,在不破环缓冲区的情况下。
*/
flushBuffer();
//用过基础字节输出流OutputStream写入,触发真正的磁盘写入,或者会占用IO资源
out.write(b, off, len);
return;
}
if (len > buf.length - count) {
flushBuffer();//若是要写入的字节数大于缓冲区空白空间,刷新缓冲区
}
System.arraycopy(b, off, buf, count, len);//拷贝方式将输出参数b中的字符写入到缓冲区中
count += len;
}
根据源代码可以看到当缓冲区的空间不足或者要将缓冲区数据写入文件中时候,就会调用flush或者flushBuffer方法,下面看看这两个方法:
public synchronized void flush() throws IOException {
flushBuffer();
out.flush();
}
/** Flush the internal buffer */
private void flushBuffer() throws IOException {
if (count > 0) {//缓冲区内有字节数据
out.write(buf, 0, count);//通过原始基础字节流一次性将字节数据写入到文件中,触发真正的磁盘写入
count = 0;//重置清空缓冲区
}
}
所以,通常flush是依赖与带有缓冲输出字节或者字符流的,每次调用flush,实质都是调用out.write()将缓冲区中数据,对磁盘文件进行真正的写入。
那么为什么要调用flush?
通过上面的源代码也知道,当一次读取大量的字节数据时候,当缓冲区内容量不足时候(默认缓冲区为8192个字节),就会进行flush啦,先将缓冲区中数据对磁盘进行写入,或者是不用缓冲区数据,直接通过基础字节流写入,最后在清空处理缓冲区,为下一次读取数据做准备。
用下面的图进行简单描述这个过程:
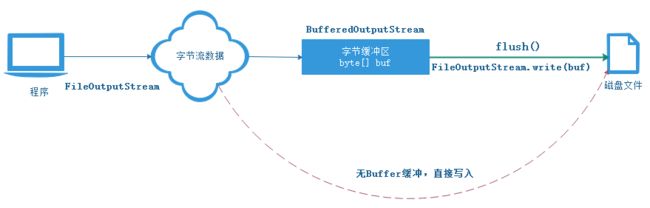
若是仅仅像处理程序中的字节数组,或者不进行文件输出的话,我们有时候也会使用ByteArrayOutputStream,给字节数组添加缓冲功能。可以输出处理好的字节数组到内存中,或者到文件中。
@Test
public void byteArrayOutputStreamTest() throws Exception{
FileOutputStream fos = new FileOutputStream("C:/Users/XianSky/Desktop/output.txt",true);
byte[] src = "bytearrayoutputstream".getBytes();//要处理的原始字节数组
//默认构造器缓冲区32个字节,可以通过构造器自定义大小,若是缓冲区大小不够,则会对当前缓冲区大小扩容一倍
ByteArrayOutputStream baos = new ByteArrayOutputStream(src.length);
baos.write(src, 0, src.length);//将src字节数组数据拷贝到内部缓冲区中
baos.write(104);//写入字母h到缓冲区末尾中
System.out.println("缓冲区中字节数:>>"+baos.size());
byte[] buff = baos.toByteArray();//将处理后的缓冲区字节转换成字节数组
System.out.println(new String(buff));
baos.close();
fos.write(buff);//将处理后的字节数组一次性写入到文件中
baos.close();
fos.close();
}
ByteArrayOutputStream还有一个特别方法就是:public synchronized void writeTo(OutputStream out),即可以将当前缓冲区中的字节数据写入到指定输出字节流中。
还有一个打印流:PrintStream,这个类对于字节,字符输出都能完成。想写入字节就使用write方法;想写入字符串,整型等基本数据类型就使用print方法。因为PrintStream这个打印流内部有两个私有的Writer类,结合本身字节的基础字节流,所以功能很强大。
public class PrintStream extends FilterOutputStream
implements Appendable, Closeable
{
...
private BufferedWriter textOut; //缓冲字符输出流
private OutputStreamWriter charOut;//字符字节转换流
...
}
打印流内部通过聚合一个字符输出流与一个字符字节输出转换流,那么就能实现字节字符的切换输出了,来看看基本使用方法,这里输出源是文件,也可以不是文件,像我们经常使用的jsp文件中也可以使用这个打印流输出信息到浏览器中:
@Test
public void PrintStreamTest() throws Exception{
FileOutputStream fos = new FileOutputStream("C:/Users/XianSky/Desktop/output.txt",true);
PrintStream ps = new PrintStream(fos);//在文件字节输出流上添加打印功能
ps.print("aa");//写入字符串
ps.print(104);//写入int数值
ps.println();//换行
ps.write(104);//写入字节,对应字母h
...
ps.close()
fos.close();
}
从使用上,操作文件也方便,可以输出任意基本数据类型和字符,字节等等数据。
其他的子类可以对照相应的输入流,可知道这些流的具体适合使用的场景。
Writer字符输出流
与OutputStream字节输出流相对,这个Writer则是字符输出流。相比而言,通常我们无论是程序输出到磁盘文件,和在网络输出,浏览器html输出,字符输出流相较而言使用比较多。下面先从整体类图看看这个字符输出流有什么子类以及通用方法特性。

从抽象基类Writer看看,对于字符输出流有那些基本的操作方法:
public void write(int c);//写入一个2字节字符
public void write(char cbuf[]);//将cbuf字符数组数据写入缓冲区
public void write(String str);//写入字符串到输出流中
public void write(String str, int off, int len);
public Writer append(CharSequence csq);//添加字符序列到输出流中
从这些方法总大致可以看出,这个Writer字符输出流系列,功能很强大,无论是单个,多个字符,字符串都能写入到字符输出流中。下面从一些常用的字符输出流的使用例子来说明内部是如何运行的?哎,其实与Reader字符输入流般,Writer除了与其方向相反,可以flush刷新缓冲区外,其他的也都产不多,你输入解码,我输出编码。
@Test
public void fileWriterTest() throws Exception{
FileWriter fw = new FileWriter("C:/Users/XianSky/Desktop/output.txt",true);
char[] cbuf = {'w','t'};
fw.write("hhh");//写入字符串
fw.write('A');//写入单个字符
fw.append("like");//在字符流添加字符串
fw.write(cbuf);//写入字符数组
fw.flush();
fw.close();
}
因为FileWirter是继承自OutputStreamWriter,其内部实现就如同FileReader类似,FileWriter写入数据都是通过:FileWriter --> OutputStreamWriter --> StreamEncoder这个流程实现的。最终还是StreamEncoder这个类实现将字节数据编码成字符数据,进行磁盘文件写入。
public class FileWriter extends OutputStreamWriter {
...
public FileWriter(String fileName) throws IOException {
super(new FileOutputStream(fileName));
}
}
同理,若是添加输出缓冲,则使用BufferedWriter或者CharArrayWirter来实现,这都是处理流,需要在基础流上封装处理,添加新功能。但是到读取字节数据底层还是由字节输出流来支持实现的。字符数据要进行输出,都要通过OutputStreamWriter类将这些字符输出流转换成字节输出流,最后统一磁盘输出到文件中。。。
在web开发中最常用的字符输出流,也就是PrintWriter了,通过得到response的输出通道流,往缓冲区里面写入字符,字符串等等数据,response刷新缓冲区后,就能将数据输出到客户端的浏览器页面进行显示了。下面看看jsp页面中或者servlet中字符输出流PrintWriter的基本使用:
//*.jsp
<%
//得到response相应输出流
PrintWriter pw = response.getWriter();
//往输出流中写入数据
pw.write(new char[]{'r','e','s'});//输出流中写入字符数组
pw.write("response output");//输出流中写入字符串
pw.append("append string");//在输出流后添加字符串
pw.flush(); //将response缓冲区中数据输出返回到客户端
%>
对于其他的使用场景,由于没有实际需求,所以就大致将这些基本的使用场景中的基本使用方式罗列出来了。基础掌握好了,高阶的也不是问题了。
输出字节流与字符流的转换
对于字符输出流来说,要想输出到文件或者其他远程网络资源中,实质上还是要转换成字节进行传输的。字节数据才能直接写入外部资源中,磁盘中存储的也是这些输出字符对应的字节。所以,字节输出是字符输出的根本。那么这个字符转换成字节的操作类OutputStreamWriter也至关重要了。
转换流过程可以参照如下图:
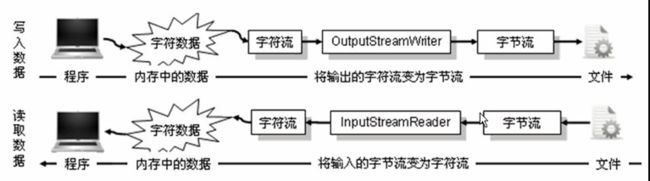
就如同InputStreamReader中使用StreamDecoder将字节解码成字符一样,OutputStreamWriter则是逆向过程,通过StreamEncoder将字符转换字节,最后输出到文件中进行保存。
public class OutputStreamWriter extends Writer {
private final StreamEncoder se;
...
/*
* 当调用write将字符数组写入到字符输出流中,底层是调用StreamEncoder se对象,
* 将字符转换成字节进行输出。
*/
public void write(char cbuf[], int off, int len) throws IOException {
se.write(cbuf, off, len);
}
}
继续进入StreamEncoder中的write方法:
//StreamEncoder.java
public void write(char cbuf[], int off, int len) throws IOException {
synchronized (lock) {
ensureOpen();
if ((off < 0) || (off > cbuf.length) || (len < 0) ||
((off + len) > cbuf.length) || ((off + len) < 0)) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return;
}
implWrite(cbuf, off, len);
}
}
void implWrite(char cbuf[], int off, int len)
throws IOException
{
CharBuffer cb = CharBuffer.wrap(cbuf, off, len);
if (haveLeftoverChar)
flushLeftoverChar(cb, false);
while (cb.hasRemaining()) {
//CharsetEncoder对CharBuffer中字符进行编码成字节
CoderResult cr = encoder.encode(cb, bb, false);
if (cr.isUnderflow()) {
assert (cb.remaining() <= 1) : cb.remaining();
if (cb.remaining() == 1) {
haveLeftoverChar = true;
leftoverChar = cb.get();
}
break;
}
if (cr.isOverflow()) {
assert bb.position() > 0;
writeBytes(); //实际字节输出方法
continue;
}
cr.throwException();
}
}
private void writeBytes() throws IOException {
bb.flip();
int lim = bb.limit();
int pos = bb.position();
assert (pos <= lim);
int rem = (pos <= lim ? lim - pos : 0);
if (rem > 0) {
if (ch != null) {// WritableByteChannel不为空
if (ch.write(bb) != rem)//通过WritableByteChannel写入ByteBuffer bb中字节数据。
assert false : rem;
} else {
//WritableByteChannel不可通过通道方式写字节数据,就用OutputStream的
//底层的write方法,内部通过native的writeBytes()方法将字节写入文件中。
out.write(bb.array(), bb.arrayOffset() + pos, rem);
}
}
bb.clear();
}
字节-->字符(InputStreamReader):解码,通过StreamDecoder将读取到字节,通过CharBuffer,ByteBuffer,ReadableByteChannel等nio包中类,将字节转换成字符到程序中进行处理。
字符-->字节(OutputStreamWriter):编码,通过StreamEncoder将程序内存中的字符数组等数据,通过CharBuffer,ByteBuffer,WritableByteChannel等nio包中类,将字符编码成字节后,在进行输出。
总结
经过自己对java io的理解,通过类图对字节流,字符流的输入输出进行大致了解。然后通过分别对一些常用的子类的使用场景进行说明,举例。并通过底层源码进行分析,当然了,自己对java io的理解也肯定有限,也有可能自己的理解错误了,有偏差,希望自己在日后学习中不断更深入了解,在回过头能发现问题并进行更正。
java中还有nio的一些知识也是非常有意思的,想上面的基础io中内部实现也有不少依赖nio中的通道概念类。希望自己也可以再下一章节写写对这些nio的使用和理解。再java io设计中,也有想适配器模式,装饰器模式的应用,也希望自己能对它们进行总结,更深入的理解。再找时间来总结和分析,坚持坚持,在写总结的过程中,自己对基础知识的理解也确实加深不少,这些时间花费还是挺值得的吧.....