一、热力图(heatmap)
热力图可以看出两个属性之间的相关系数。
- 举例一,以Titanic数据为例:红色(正相关)或者蓝色(负相关)颜色越深说明相关性越强。
plt.figure(figsize=(12,10))
foo = sns.heatmap(train.drop('PassengerId',axis=1).corr(), vmax=0.6, square=True, annot=True)

热力图1
- 举例二:网上找的示例
import matplotlib.pyplot as plt
import seaborn as sns
data = pd.read_csv("../input/car_crashes.csv")
data = data.corr()
sns.heatmap(data)
plt.show()

热力图2
二、矩阵图pairplot
当数据的特征维度大于2时,无法在平面上表征这些维度,seaborn提供了pairplot。两两组成pair看数据在2个维度平面上的分布情况。
图中点的颜色按照结果种类(class=0\1\2...)区分。对角线位置是直方图,其它位置是散点图。pairplot更适合大量散点的场景,更容易看出变量间的相关性。
- 举例一:Titanic数据,nosurv_col未获救,红色,surv_col获救,蓝色。这是一个典型不适合的场景,基本上看不出相关性。vars选择的是整个cols
cols = ['Survived','Pclass','Age','SibSp','Parch','Fare']
g = sns.pairplot(data=train.dropna(), vars=cols, size=1.5,
hue='Survived', palette=[nosurv_col,surv_col])
g.set(xticklabels=[])

pairplot图形1
- 举例二:网上找的案例,TV\Radio\Newpaper和sales间的关系,x_vars=['TV','Radio','Newspaper'],y_vars='Sales'
import seaborn as sns
sns.pairplot(data,x_vars=['TV','Radio','Newspaper'],y_vars='Sales',size=7,aspect=0.8)

pairplot图形2
seaborn的pairplot函数绘制X的每一维度和对应Y的散点图。通过设置size和aspect参数来调节显示的大小和比例。可以从图中看出,TV特征和销量是有比较强的线性关系的,而Radio和Sales线性关系弱一些,Newspaper和Sales线性关系更弱。通过加入一个参数kind=’reg’,seaborn可以添加一条最佳拟合直线和95%的置信带。
sns.pairplot(data, x_vars=['TV','Radio','Newspaper'], y_vars='Sales', size=7, aspect=0.8, kind='reg')

pairplot图形3
举例三:来自大牛寒小阳的博客
import matplotlib.pyplot as plt
import seaborn as sns
#使用pairplot看不同特征维度pair下数据的空间分布状况
_=sns.pairplot(df[:50],vars=[8,11,12,14,19],hue="class",size=1.5)
plt.show()
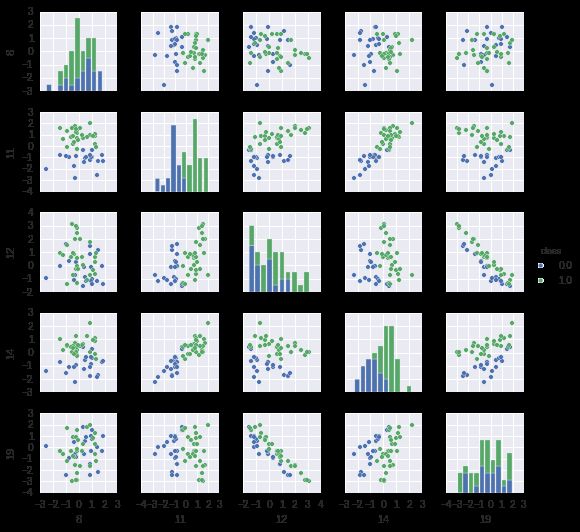
pairplot图形4
解读:从柱状图看,第11维和第14维看起来是近似线性可分的;从散列图看,第12和19维之间呈现出很高的负相关性。
接着用Seaborn的 corrplot
import matplotlib.pyplot as plt
plt.figure(figsize=(12,10))
_=sns.corrplot(df,annot=False)
plt.show()

各维度间的相关性
解读:最后一行是最终的类别(class=0/1/2..)。
从最后一行看,第11维的特征和类别间有极强的相关性,同理第14维。从交叉各行看,第11维特征和第14维特征之间也有极高的相关性;第12维特征和第19维特征间有极强的负相关性。强相关的特征其实包含了一些冗余的特征,而除掉上图中颜色较深的特征,其余特征包含的信息量就没有这么大了,它们和最后的类别相关度不高,甚至各自之间也没什么先惯性。插一句,这里的维度只有20,所以这个相关度计算并不费太大力气,然而实际情形中,你完全有可能有远高于这个数字的特征维度,同时样本量也可能多很多,那种情形下我们可能要先做一些处理,再来实现可视化了。
三、直方图distplot
distplot(seaborn)是加强版的hist(pandas),都是做直方图
- 举例一:Titanic数据,直方图自动得出[0,1),[1,2)...范围内获救/未获救的人数,并画出图形。
fig, ax = plt.subplots()
sns.distplot(surv['Age'].dropna().values, bins=range(0, 81, 1), ax=ax, kde=False, color="blue")
sns.distplot(nosurv['Age'].dropna().values, bins=range(0, 81, 1), ax=ax, kde=False, color="red")
ax.set_xlim([0, 82])
print("Median age survivors: %.1f, Median age non-survivers: %.1f"\
%(np.median(surv['Age'].dropna()), np.median(nosurv['Age'].dropna())))
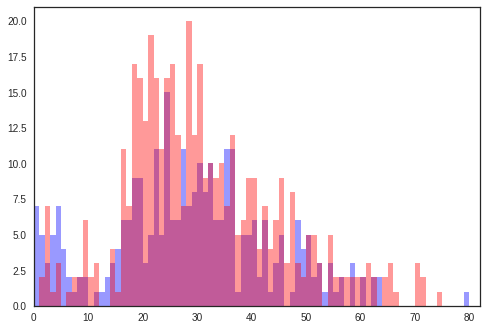
直方图1
图中,蓝色是获救的,红色是未获救的。既有获救又有未获救是图中紫色部分。从图中可以看出10岁以下获救概率高,18-30之间很少获救。
- 举例二:网上的数据,对比hist()和distplot()的区别
import matplotlib.pyplot as plt
import seaborn as sns #要注意的是一旦导入了seaborn,matplotlib的默认作图风格就会被覆盖成seaborn的格式
%matplotlib inline # 为了在jupyter notebook里作图,需要用到这个命令
sns.distplot(births['prglngth'])
sns.plt.show()

直方图2
可以看出distplot()与hist()的最大区别是有一条密度曲线(KDE),可以设置参数去掉这条默认的曲线。
sns.distplot(births['prglngth'], kde=False)
sns.plt.show()
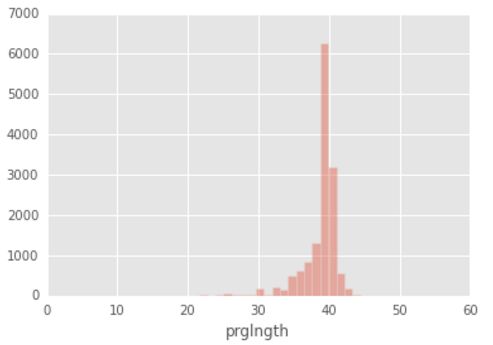
直方图3
四、直方图hist
- 举例:以Titanic为例,考量fare与survive之间的关系
#fare有等于0的,所以要+1
dummy = plt.hist(np.log10(surv['Fare'].values+ 1), color="orange", normed=True)
dummy = plt.hist(np.log10(nosurv['Fare'].values+ 1), histtype='step', color="blue", normed=True)
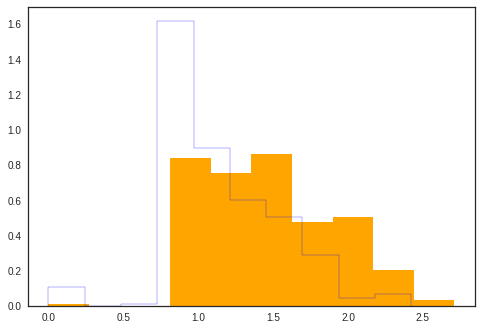
直方图
五、堆积直方图
在作图之前,先理解crosstab
df = DataFrame({'key1':['a','a','b','b','a'],'key2':['one','two','one','two','one'],'data1':np.random.randn(5),'data2':np.random.randn(5)})
df
#[Out]# data1 data2 key1 key2
#[Out]# 0 0.439801 1.582861 a one
#[Out]# 1 -1.388267 -0.603653 a two
#[Out]# 2 -0.514400 -0.826736 b one
#[Out]# 3 -1.487224 -0.192404 b two
#[Out]# 4 2.169966 0.074715 a one
pd.crosstab(df.key1,df.key2, margins=True)
#[Out]# key2 one two All
#[Out]# key1
#[Out]# a 2 1 3
#[Out]# b 1 1 2
#[Out]# All 3 2 5
参考1
类似crosstab做分类的,还有:groupby\pivot_table,
参考2
对于分类型的特征,用累积直方图还是很合适的。
- 举例:Titanic
tab.sum(1),每个class的总和,注意纵轴是percentage
tab = pd.crosstab(train['Pclass'], train['Survived'])
print(tab)
dummy = tab.div(tab.sum(1).astype(float), axis=0).plot(kind="bar", stacked=True)
dummy = plt.xlabel('Pclass')
dummy = plt.ylabel('Percentage')
绿色是survived,可以看出1st class获救率更高。

累积直方图1
如果dummpy改为
dummy = tab.div(tab.sum(1).astype(float), axis=0).plot(kind="bar")
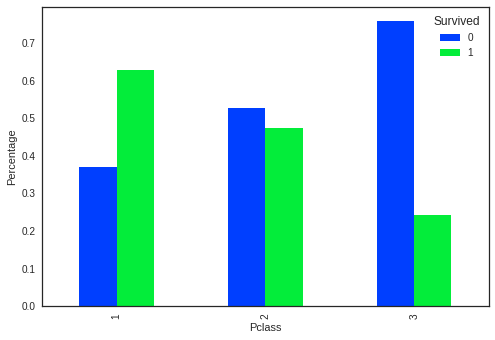
对比直方图
同理,性别属性也可以用累积直方图
sex = pd.crosstab(train['Sex'], train['Survived'])
print(sex)
dummy = sex.div(sex.sum(1).astype(float), axis=0).plot(kind="bar", stacked=True)
dummy = plt.xlabel('Sex')
dummy = plt.ylabel('Percentage')

累积直方图2