使用基于深度学习的自动对焦和相位恢复在全息成像中扩展景深
全息术以仅强度记录的形式对样本的三维(3D)信息进行编码。然而,为了从其全息图解码原始样本图像,需要自动聚焦和相位恢复,这在数字上执行通常是麻烦且耗时的。在这里,我们演示了基于卷积神经网络(CNN)的方法,该方法同时执行自动聚焦和相位恢复,以显着扩展景深(DOF)和全息成像中的重建速度。为此,通过使用成对的随机散焦的反向传播的全息图及其对应的对焦相位恢复图像来训练CNN。在该训练阶段之后,CNN采用3D样本的单个反向传播全息图作为输入以快速实现相位恢复并在显着扩展的DOF上重建样本的对焦图像。这种基于深度学习的DOF扩展方法是非迭代的,并且显着地改善了从O(nm)到O(1)的全息图像重建的算法时间复杂度,其中n指的是样本内的单个对象点或粒子的数量。体积,m代表聚焦搜索空间,每个物体点或粒子需要在其中单独聚焦。这些结果突出了由机器学习驱动的数据统计图像重建方法所创造的一些独特机会,并且我们相信所提出的方法可广泛适用于计算地扩展其他成像模态的DOF。
全息术[1-8]通过物体散射光与参考波的干涉来编码样本的三维(3D)信息。通过该干涉过程,由例如图像传感器记录的全息图的强度包含样本的幅度和相位信息。通过3D样本空间恢复此对象信息已成为众多全息成像技术的主题[2-4,9-12]。在全息图像重建过程中,有两个主要步骤。其中之一是,这是必需的,因为在给定的数字全息图中仅记录全息图案的强度信息。通常,对于离轴全息成像系统[3,4,11,12],与线上全息设置相比,可以相对更容易地实现该相恢复步骤,代价是减少空间带宽积。成像系统。另一方面,对于在线全息术,已经开发了利用测量多样性和/或关于样本的先验信息的迭代相位恢复方法[6,7,13-22]。无论采用何种特定的全息设置,都需要进行相位恢复,以消除样本的重建相位和幅度图像中的双重图像和自干扰相关的空间伪像。
全息图像重建中的另一个关键步骤是,其中需要数值估计3D对象的不同部分的样本到传感器距离(即,相对高度)。自动聚焦精度对于重建的全息图像的质量是至关重要的,使得相位恢复的光场可以3D反向传播到正确的物体位置。传统上,为了执行自动聚焦,全息图被数字地传播到一组轴向距离,其中在每个得到的复值图像处评估聚焦标准。该步骤理想地在相位恢复步骤之后执行,但是也可以在之前应用,虽然这可能会降低聚焦精度[23]。各种自动聚焦标准已经成功地用于全息成像,包括例如田村系数[24],基尼指数[25]和其他[23,26-31]。无论使用何种特定的聚焦标准,甚至采用智能搜索策略[32],自动聚焦步骤都需要光场的数值反向传播和通常> 10-20轴距离的标准评估,即使是小视场(FOV)。此外,如果样本具有不同深度的多个对象,则需要对FOV中的每个对象重复该过程。
最近的一些工作利用深度学习来实现自动对焦。任等人。制定自动聚焦作为分类问题并使用卷积神经网络(CNN)来提供具有~3mm轴向范围的每个分类(即,箱)的聚焦距离的粗略估计,这更适合于不需要精确了解每个物体的轴向距离的成像系统。[33]另一个例子,Shimobaba等。使用CNN回归模型实现连续自动对焦,同样具有> 5mm的相对粗糙的聚焦精度[34]。与这些最近的结果并行,已经证明了使用单个强度全息图来重建二维物体图像的基于CNN的相位恢复方法[35-38]。然而,在这些前一种方法中,使用对焦图像训练神经网络,其中基于成像设置先验地精确地知道样本到传感器(全息图)距离,或者基于自动聚焦标准单独地确定。结果,重建质量在系统景深(DOF)之外迅速降低;例如,对于病理载玻片(组织切片)的高分辨率成像,与正确聚焦距离的~4μm偏差导致分辨率的损失并使亚细胞结构细节失真[38]。
在这里,我们演示了一种基于深度学习的全息图像重建方法,该方法使用单个全息图强度同时执行自动聚焦和相位恢复,与以前的方法相比,显着扩展了重建图像的DOF,同时还改善了算法时间 - 从O(nm)到O(1)的全息图像重建的复杂性。我们将此方法称为,并且它依赖于训练CNN不仅具有对焦图像补丁,而且还具有随机散焦的全息图像以及它们相应的对焦和相位恢复图像,用作参考。总的来说,HIDEF通过同时执行自动聚焦和相位恢复显着提高了高分辨率全息成像的计算效率和重建速度,并且通过扩展重建图像的DOF,增加了图像重建过程对光学设置中的潜在未对准的鲁棒性。
除了数字全息术之外,相同的基于深度学习的方法也可以用于改善非相干成像模态的DOF,包括例如荧光显微术。这项工作及其成果突出了基于深度学习的统计图像重建方法所创造的一些令人兴奋的机会,这些方法通过高质量图像数据的可用性为具有挑战性的成像问题提供了独特的解决方案。
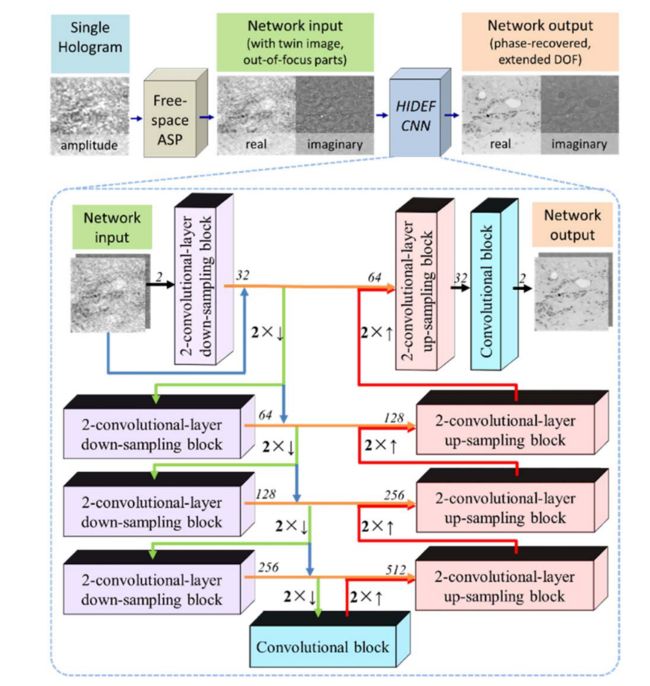
图1 。 HIDEF CNN在训练后,同时实现了相位恢复和自动对焦,显着扩展了全息图像重建的DOF。 网络具有下采样分解路径(绿色箭头)和对称上采样扩展路径(红色箭头)。 蓝色箭头标记跳过卷积层的路径(定义残余连接)。 斜体数字表示这些块中不同级别的输入和输出通道的数量。 橙色箭头表示下采样和上采样路径之间的连接,其中来自下采样块的输出的通道与来自相应的上采样块的输出连接,使通道数加倍(参见补充1) 进一步细节)。 ASP,角谱传播。
我们使用的神经网络的体系结构如图1所示。该CNN体系结构的灵感来自U-Net [39],它包括一个下采样路径以及一个对称的上采样路径(参见补充说明1网络的详细描述)。通过一系列下采样操作,网络学会捕捉和分离不同尺度的全息输入场的真实图像和双图像空间特征[22]。还包括附加的快捷路径(图1中的蓝色箭头),以通过剩余连接向前传递信息,这对于提高网络的训练速度很有用[40]。这种CNN架构是使用TensorFlow实现的,TensorFlow是一种开源深度学习软件包[41]。在训练阶段,CNN最小化网络输出与目标/参考图像的l1范数距离,并使用自适应矩估计(Adam)优化器[42]以学习率10-4迭代地更新网络的权重和偏差。或者,也可以使用基于l2范数距离的损失函数来获得类似的结果,对空间分辨率有潜在的损失。对于每个图像数据集,训练与交叉验证的比率设置为14:3。网络的培训和盲测是在具有六核3.60 GHz CPU,16 GB RAM,使用Nvidia GeForce GTX 1080Ti GPU的PC上进行的。平均而言,训练过程需要约40小时,例如200,000次迭代,对应于~100个时期。在训练之后,512×512像素(具有相位和幅度通道)的全息图片的网络推断时间<0.2s。
为了证明HIDEF的成功,在我们的初始实验中,我们使用了由软冲击器表面捕获并通过片上全息显微镜成像的气溶胶,其中每个气溶胶散射的光场干扰直接透射的光形成在线全息图,使用CMOS成像器采集,无需使用任何镜头[32]。由于在空气采样期间变化的颗粒质量,流速和流动方向,基板上捕获的气溶胶分散在多个深度(z2)[32]。基于这种设置,训练图像数据集具有176个数字裁剪的非重叠区域,其仅包含位于相同深度的粒子,通过将它们旋转到0度,90度,180度和270度进一步增加四倍到704个区域。对于每个区域,我们使用单个全息图强度并将其反向传播到81个随机距离,跨越距正确全局焦点-100到100μm的轴向范围,通过使用梯度标准的Tamura自动聚焦确定[23] 。然后,我们使用这些复值字段作为网络的输入。使用多高度相位恢复(MH-PR)重建训练阶段中使用的目标图像(即,对应于相同样本的参考图像),所述多高度相位恢复利用样本的八个不同的在线全息图,在不同的z2距离处捕获,在对每个高度进行初始自动聚焦步骤之后,迭代地恢复样品的相位信息[14,43]。
在此培训阶段之后,接下来我们在与培训或验证集没有重叠的样本上盲目测试HIDEF网络;这些样品含有在每个图像FOV的不同深度上散布的颗粒。图2说明了HIDEF的成功以及它如何同时实现扩展的DOF和相位恢复。对于捕获的气溶胶的给定的在线全息图[如图2(a)所示],我们首先将全息图强度反向传播到距离CMOS成像器的有效区域z2 = 1mm的粗略距离,这是基于实验中使用的有效衬底厚度粗略确定的。由于传播距离短(~1mm)和缺失的相位信息,这个初始的反向传播全息图产生了强烈的双图像。然后将包含真实和双重图像的这个复数值字段馈送到CNN。 CNN的输出如图2(a)所示,其展示了具有各种气溶胶的HIDEF的扩展DOF,其在约90μm的轴向范围内扩散,所有这些都在网络输出处聚焦。除了将包含在单个全息图中的所有粒子带到清晰焦点之外,网络还执行相位恢复,从而产生没有与图像干扰和自干扰相关的伪影的相位和幅度图像。图2(b)和2(c)还比较了网络输出相对于标准MH-PR方法的结果,该标准MH-PR方法使用八个在线全息图来迭代地检索样本的相位信息。这些比较清楚地证明了使用单个全息图强度以及非迭代推断时间<0.2s实现的HIDEF的显着扩展的DOF和相恢复性能。相比之下,迭代MH-PR方法需要〜4秒进行相位恢复,并且在8个平面上自动对焦到单个对象需要大约2.4秒,对于相同的FOV和对象体积总共~6.4s,即慢> 30倍与HIDEF相比。
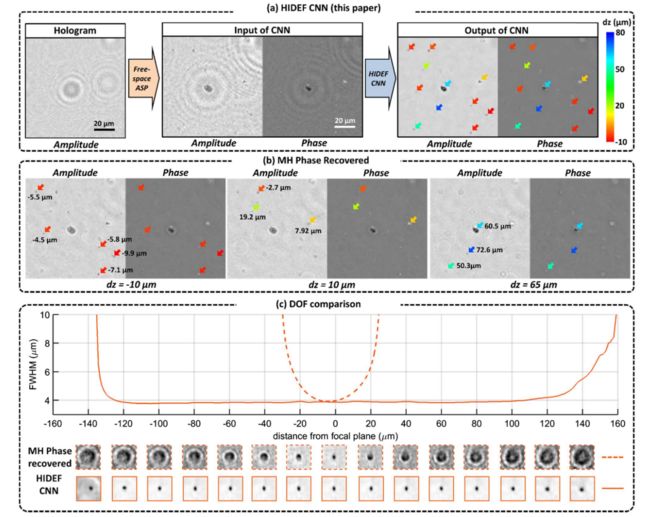
图2.使用HIDEF对不同深度的气溶胶进行扩展DOF重建。 (a)经过培训,HIDEF CNN将FOV内的所有粒子聚焦,同时进行相位恢复。每个粒子的深度相对于反向传播距离(1毫米)进行颜色编码,如右侧的颜色条所示。 (b)作为比较,相同FOV的MH-PR图像显示一些粒子在不同深度处聚焦并且在其他深度处变得不可见或变形。对于每个粒子的箭头,使用与(a)中相同的颜色编码。 (c)HIDEF的增强DOF通过跟踪粒子的半峰值宽度(FWHM)作为轴向散焦距离的函数来说明(详见补充说明1)。 HIDEF保持粒子的FWHM直径及其在> 0.2mm的大DOF上的正确图像,这是预期的,因为它是针对该离焦范围(0.1mm)进行训练的。另一方面,MH-PR结果显示出更有限的DOF,同样在底部报告的相同粒子 - 在不同散焦距离处的幅度图像也证实了这一点。另请参阅可视化1和可视化2以进行详细比较。
在这些结果中,我们使用1 mm的粗后向传播步骤,然后向CNN馈送复值域。我们的方法的一个重要特征是这种反向传播距离z2不需要精确。在可视化1中,我们演示了HIDEF输出图像的稳定性,因为我们改变了初始反向传播距离,无论初始z2选择如何,都提供相同的扩展DOF图像。这是非常期待的,因为网络是使用跨越轴向散焦(dz)范围为λ/ - 0.1mm的散焦全息图进行训练的。对于可视化1中所示的这种特定FOV,在3D中随机散布的所有气溶胶都经历了由λ/ -0.1mm限制的散焦量(相对于它们在样品体积中的正确轴向距离)。除了这种散焦范围之外,HIDEF网络不能执行可靠的图像重建,因为它没有经过训练[参见例如图2(c)中的|dz|>120μm]。实际上,在其训练范围之外,HIDEF开始产生幻觉,如可视化2所示,其覆盖了-1mm≤dz≤1mm的更大的轴向散焦范围 - 超出了网络的训练范围。
有趣的是,尽管网络仅使用全局散焦的全息贴片进行训练,该贴片仅包含相同深度/平面的粒子,但它学会了单独聚焦位于同一FOV内不同深度的各种粒子[见图2(a)]。基于这种观察,可以认为HIDEF网络不执行某个全息图FOV到焦平面的自由空间反向传播的物理等效。相反,它统计学习输入场的对焦和离焦特征,对离焦部分进行分割,并且对于给定的全息图FOV以并行方式用对焦特征替换它们。从算法时间复杂度的角度来看,这是给定全息图片的固定处理时间,即O(1)的复杂度,而不是传统的O(nm),其中n定义了单个对象点或粒子的数量。在3D样本体积内,m是离散的聚焦搜索空间。
基于上述论点,如果网络统计学习样本的焦点内和焦点外特征,可以认为这种方法应该限于相对稀疏的对象(如图2所示),让网络在训练中使用的某个轴向散焦范围内学习离焦样本特征。实际上,为了用非稀疏样本测试该假设,接下来我们在空间连接对象(例如组织切片)的全息图上测试HIDEF,其中样本平面内没有开口或空区域。为了实现这一目标,基于图1所示的CNN架构,我们用1,119个全息贴片(对应于组织病理学中使用的乳房组织切片)训练网络,随机传播到41个距离,跨越轴向散焦范围-100到相对于焦平面为100μm。在此培训阶段,我们使用MH-PR图像作为我们的目标/参考。我们在网络训练后的盲测结果总结在图3和可视化3中,它清楚地表明HIDEF可以同时对任意,非稀疏和连通的样本进行相位恢复和自动聚焦。在图3中,我们还发现MH-PR图像自然表现出有限的DOF:即使在~5μm的轴向散焦时,组织水平的一些精细特征也会失真。随着轴向散焦越来越多,MH-PR结果显示出明显的人造涟漪和更多细节的损失。另一方面,HIDEF对于轴向散焦非常稳健,能够正确地聚焦整个图像及其精细特征,同时还能够在不同的散焦距离内抑制双图像伪影,达到其训练范围( + - 0.1毫米);见可视化3。

图3.HIDEF结果与自由空间反向传播(CNN输入)和MH-PR(MH相恢复)结果的比较,作为轴向散焦距离(dz)的函数。 测试样品是人乳房组织样品的薄切片。 前两列使用单一强度全息图,而第三列(MH-PR)使用相同样品的八个在线全息图,在不同高度获得。 这些结果清楚地表明,HIDEF网络同时在其训练的轴向散焦范围内执行相位恢复和自动聚焦(即,在这种情况下jdzj≤100μm)。 在此训练范围之外(标有红色dz值),网络输出不可靠。 有关详细比较,请参见可视化3和可视化4。 比例尺:20μm。
然而,如可视化4和图3所示,超出其训练范围,HIDEF开始产生幻觉并产生虚假特征。在可视化2中也观察到类似的气溶胶图像行为。人们可以从这些观察中得到几条消息:网络不会学习或推广特定的物理过程,如波传播,全息图形成或光干扰;如果要推广这样的物理过程,人们就不会在网络输出处看到完全不相关的空间特征的突然出现,因为逐渐超出了它所训练的轴向散焦范围。例如,如果比较训练范围内和外部的网络输出(参见可视化3和可视化4),可以清楚地看到我们没有看到物理拖尾或衍射相关的平滑效果,因为一个人继续在一个范围内散焦。网络没有接受过培训。在这个对网络来说“新”的散焦范围内,它仍然提供相对清晰但不相关的特征,这表明它没有学习或推广波传播或干扰的物理特性。事实上,这突出了基于深度学习和数据驱动全息图像重建框架的独特方面,这里提出了:网络的输出图像是由神经网络训练的图像变换驱动的(在输入和输入之间)金标准标签图像),这种学习的转换产生的输出图像偏离基于波动方程(物理驱动)的解决方案。图2显示了一个重要的例子,其中网络快速对位于样品体积内不同深度的所有颗粒进行相位恢复和自动聚焦,使所有颗粒聚焦在输出图像上。从网络输入到输出的这种图像变换偏离基于波方程的解决方案,该解决方案将相位恢复的场传播到不同的平面,其中一些粒子将聚焦,而另一些粒子将在自由空间波传播的驱动下失焦。
为了进一步量化HIDEF的改进,接下来我们将网络输出图像的幅度与组织切片正确焦点处的MH-PR结果进行比较,并使用结构相似性(SSIM)指数进行比较,定义为[44 ]

其中U1是要评估的图像,U2是参考图像,在这种情况下是使用八个在线全息图的自动聚焦MH-PR结果。 μp和σp分别是图像Up(p≤1,2)的平均值和标准偏差。 σ1,2是两个图像之间的交叉方差,C1,C2是用于防止小分母分割的稳定常数。基于这些定义,图4显示了在-200至200μm的轴向散焦范围内计算的平均SSIM指数,其在180个不同的乳房组织FOV中被平均测试。与图3和可视化3中报告的定性比较一致,由于网络的相位恢复能力,HIDEF输出的SSIM值显着高于全息图强度反向传播到精确焦距。此外,如图4所示,与仅使用对焦全息图(具有精确z2值)训练的CNN(具有相同网络架构)相比,HIDEF具有更高的SSIM指数,对于DOF ~0.2mm的散焦全息图。有趣的是,用对焦全息图训练的网络在图4中只有一点击败HIDEF,即对于dz? 0μm,这是预期的,因为这是它专门训练的。然而,SSIM的这种小差异(0.78对0.76)在视觉上可以忽略不计(参见可视化3,dz的框架 = 0μm)。

图4.作为轴向散焦距离函数的SSIM值。 这些SSIM曲线中的每一个在180个测试FOV(512×512像素)上平均,对应于人乳房组织样本的薄切片。 结果证实了HIDEF网络输出图像的扩展DOF,直到其训练的轴向散焦范围。
到目前为止我们报告的结果证明了HIDEF同时执行相位恢复和自动聚焦的独特能力,使得重建图像的DOF至少增加了一个数量级,这也由图3和图4证实。 2和3以及可视化1,可视化2-可视化3.为了进一步扩展神经网络输出的DOF超过0.2 mm,可以使用更大的网络(具有更多层,权重和偏差)和/或更多训练数据,包含严重散焦的图像作为其学习阶段的一部分。当然,此处报告的概念验证DOF增强不是所提出方法的最终限制。事实上,为了更好地强调这个机会,我们还按照图的HIDEF架构训练了第三个神经网络。如图1所示,训练图像集包含随机散焦的乳房组织切片全息图,轴向散焦范围为-0.2至0.2mm。这个新网络与前一个网络的性能比较(如图3所示)如图4所示。如此比较所示,通过使用包含更多散焦全息图的训练图像集,我们能够显着扩展轴向散焦范围为0.4 mm(即 +/ - 0.2mm),HIDEF网络在同一输出图像上成功执行自动对焦和相位恢复。
总之,我们认为这项工作中报告的结果为统计图像重建方法所创造的一些独特机会提供了令人信服的证据,特别是通过深度学习,这里提出的方法可以广泛应用于计算扩展其他成像模式的DOF。 ,包括例如荧光显微术。