目录
1.jieba下载安装
2.算法实现
3.分词功能
1.jieba下载安装
Jieba是一个中文分词组件,可用于中文句子/词性分割、词性标注、未登录词识别,支持用户词典等功能。该组件的分词精度达到了97%以上。
1)下载Jieba
官网地址:pypi.python.org/pypi/jieba/
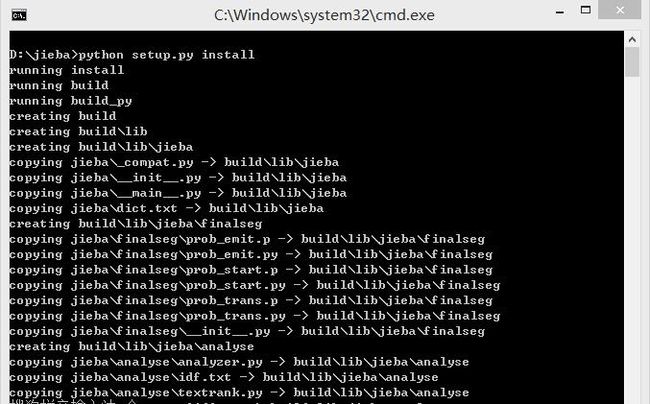
2)安装
打开命令提示符,输入python setup.py install 进行安装
2.算法实现
1)基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG);
2)采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合;
3)对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法。
3.分词功能
1)分词
jieba.cut方法接受两个输入参数: 1) 第一个参数为需要分词的字符串 2)cut_all参数用来控制是否采用全模式;jieba.cut_for_search 方法接受两个参数:需要分词的字符串;是否使用 HMM 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细。
待分词的字符串可以是 unicode 或 UTF-8 字符串、GBK 字符串。注意:不建议直接输入 GBK 字符串,可能无法预料地错误解码成 UTF-8。
jieba.cut以及jieba.cut_for_search返回的结构都是一个可迭代的generator,可以使用for循环来获得分词后得到的每一个词语(unicode),也可以用list(jieba.cut(...))转化为list
代码示例:
#encoding=utf-8
import jieba
seg_list = jieba.cut("范炜是川大信管专业的老师",cut_all=True)
print"Full Mode:","/ ".join(seg_list)#全模式
seg_list = jieba.cut("范炜是川大信管专业的老师",cut_all=False)
print"Default Mode:","/ ".join(seg_list)#精确模式
seg_list = jieba.cut("范炜是川大信管专业的老师")#默认是精确模式
print", ".join(seg_list)
seg_list = jieba.cut_for_search("范炜是川大信管专业的老师")#搜索引擎模式
print", ".join(seg_list)
结果显示:

2)自定义词典
用法: jieba.load_userdict(file_name) # file_name 为自定义词典的路径。
词典格式和dict.txt一样,一个词占一行;每一行分三部分,一部分为词语,另一部分为词频(可省略),最后为词性(可省略),用空格隔开。
词频可省略,使用计算出的能保证分出该词的词频。
更改分词器的 tmp_dir 和 cache_file 属性,可指定缓存文件位置,用于受限的文件系统。
自定义词典示例:
范炜 5 nr
川大 5 j
信管 5 j
代码示例:
#encoding=utf-8
import sys
sys.path.append("C:\Python27\Lib\site-packages\jieba")
import jieba
jieba.load_userdict("D:/jieba/jieba/userdict.txt")
seg_list= jieba.cut("范炜是川大信管专业的老师")
print("Revise: "+"/".join(seg_list))
结果显示:
3)调整词典
使用 add_word(word, freq=None, tag=None) 和 del_word(word) 可在程序中动态修改词典。
使用 suggest_freq(segment, tune=True) 可调节单个词语的词频,使其能(或不能)被分出来。
代码示例:
#encoding=utf-8
import sys
sys.path.append("C:\Python27\Lib\site-packages\jieba")
import jieba
jieba.load_userdict("D:/jieba/jieba/userdict.txt")
jieba.add_word("江大桥",freq=20000,tag=None)
print"/".join(jieba.cut("江州市长江大桥参加了长江大桥的通车仪式。"))
结果显示:
4)关键词提取(基于 TextRank 算法的关键词提取)
基本思想:
将待抽取关键词的文本进行分词;
以固定窗口大小(默认为5,通过span属性调整),词之间的共现关系,构建图;
计算图中节点的PageRank,注意是无向带权图。
jieba.analyse.textrank(sentence, topK = 20, withWeight = False, allowPOS = ('ns', 'n', 'v', 'nv')) 注意默认过滤词性。
jieba.analyse.TextRank() 新建自定义TextRank实例。
代码示例:
#encoding=utf-8
import sys
sys.path.append('C:\Python27\Lib\site-packages\jieba')
import jieba
import jieba.analyse
from optparse import OptionParser
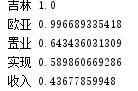
s="此外,公司拟对全资子公司吉林欧亚置业有限公司增资4.3亿元,增资后,吉林欧亚置业注册资本由7000万元增加到5亿元。吉林欧亚置业主要经营范围为房地产开发及百货零售等业务。目前在建吉林欧亚城市商业综合体项目。2013年,实现营业收入0万元,实现净利润-139.13万元。"
for x, w in jieba.analyse.textrank(s,topK=5,withWeight=True):
print("%s %s"% (x, w))
结果显示:
5)词性标注
jieba.posseg.POSTokenizer(tokenizer=None) 新建自定义分词器,tokenizer 参数可指定内部使用的 jieba.Tokenizer 分词器。jieba.posseg.dt 为默认词性标注分词器。
标注句子分词后每个词的词性,采用和 ictclas 兼容的标记法。
代码示例:
#encoding=utf-8
import jieba.posseg as pseg
words = pseg.cut("我爱北京天安门。")
for w in words:
print("%s %s"%(w.word, w.flag))
结果显示:
