发展前景
随着科学技术的进步和工业的发展,城市中交通量激增,原始的交通方式已不能满足要求;同时,由于工业发展为城市交通提供的各种交通工具越来越多,从而加速了城市交通事业的发展。
道路容量严重不足 汽车增长速度过快 公共交通日趋萎缩
交通设施条件不足 缺乏整体发展战略


交通计数应用程序是为了统计交通流量用的,对城市、或公路网络,道路的规划设计所必须的参数-交通量(当然包含比如日交通量、年交通量、日交通高峰流量等)
所有代码
这是我们的计划:
-
理解用于前景检测的背景减法算法的主要思想。
-
OpenCV图像过滤器。
-
通过轮廓检测物体。
-
构建处理管道以进一步处理数据。
下面这个视频是从youtube上下载:https://youtu.be/wqctLW0Hb_0
背景减法算法


背景减法有许多不同的算法,但它们的主要思想非常简单。 我们假设您有一个房间的视频,并且在该视频的某些帧上没有人和宠物,所以基本上它是静态的,我们称之为background_layer。因此,要获取正在视频中移动的对象,我们只需要:
foreground_objects = current_frame - background_layer
但在某些情况下,我们无法获得静态帧,因为灯光可能会发生变化,或某些物体会被某人移动,或者总是存在运动等等。在这种情况下,我们会保存一定数量的帧并试图找出哪些像素大多数都是一样的,然后这个像素成为background_layer的一部分。区别在于我们如何获得此background_layer以及我们用于使选择更准确的其他过滤。
在本课中,我们将使用MOG算法进行背景减法,处理后,它看起来像这样:

左侧的原始帧,右侧的MOG(带阴影检测)减去前景。
正如您所看到的那样,前景蒙版上会出现一些噪音,我们会尝试使用一些标准的滤镜技术来消除这些噪音。
现在我们的代码看起来像这样:
def train_bg_subtractor(inst, cap, num=500): ''' BG减法器需要处理一些帧来开始给出结果 ''' print('Training BG Subtractor...') i = 0 while cap.isOpened(): ret, frame = cap.read() inst.apply(frame, None, 0.001) i += 1 if i >= num: return cap # 创造MOG BG减法器,缓存500帧和阴影剔除 bg_subtractor = cv2.createBackgroundSubtractorMOG2(history=500, detectShadows=True) # 设置图像源 cap = cv2.VideoCapture('input.mp4') # 跳过500帧训练bg减法器 train_bg_subtractor(bg_subtractor, cap, num=500)
帧——就是影像动画中最小单位的单幅影像画面,相当于电影胶片上的每一格镜头。 一帧就是一副静止的画面,连续的帧就形成动画,如电视图象等。 我们通常说帧数,简单地说,就是在1秒钟时间里传输的图片的帧数,也可以理解为图形处理器每秒钟能够刷新几次,通常用fps(Frames Per Second)表示。每一帧都是静止的图象,快速连续地显示帧便形成了运动的假象。高的帧率可以得到更流畅、更逼真的动画。每秒钟帧数 (fps) 愈多,所显示的动作就会愈流畅。
哪吒:按照24帧/秒的人眼帧数


过滤
对于我们的情况,我们将需要这个过滤器:
阈值,侵蚀,扩张,开运算,闭运算。
腐蚀
卷积核沿着图像滑动,如果与卷积核对应的原图像的所有像素值都是 1,那么中心元素就保持原来的像素值,否则就变为零。
erosion = cv2.erode(img,kernel,iterations = 1)
膨胀
与腐蚀相反,与卷积核对应的原图像的像素值中只要有一个是 1,中心元素的像素值就是 1。
dilation = cv2.dilate(img,kernel,iterations = 1)

开运算(去噪)
先腐蚀再膨胀就叫做开运算。就像我们上面介绍的那样,它被用来去除噪声。这里我们用到的函数是 cv2.morphologyEx()。
opening = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel)


闭运算(填黑点)
先膨胀再腐蚀。它经常被用来填充前景物体中的小洞,或者前景物体上的小黑点。
closing = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel)

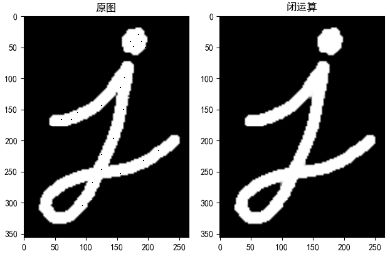
所以现在我们将使用它们去除前景蒙版上的一些噪音。 首先,我们将使用闭运算去除区域中的间隙,然后打开以移除1-2 px点,然后再扩张后使目标对象更大。
def filter_mask(self, img, a=None): # 这个过滤器是根据视觉测试手工挑选的 kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (2, 2)) # 填补任何小洞 closing = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel) # 去除噪音 opening = cv2.morphologyEx(closing, cv2.MORPH_OPEN, kernel) # 膨胀以合并相邻的小块 dilation = cv2.dilate(opening, kernel, iterations=2) return dilation
我们的前景看起来像这样:


通过轮廓检测物体
为此,我们将使用带有params的标准cv2.findContours方法:
函数 cv2.findContours() 有三个参数:
第一个是输入图像,第二个是轮廓检索模式,第三个是轮廓近似方法。
返回值有三个,第一个是图像(现在没了),第二个是轮廓,第三个是(轮廓的)层析结构。轮廓(第二个返回值)是一个 Python列表,其中存储这图像中的所有轮廓。每一个轮廓都是一个 Numpy 数组,包含对象边界点(x,y)的坐标。
cv2.CV_RETR_EXTERNAL - 仅获取外轮廓。
cv2.CV_CHAIN_APPROX_TC89_L1 - 使用Teh-Chin链式近似算法(更快)
# 得到边界框的中心 def get_centroid(x, y, w, h): x1 = int(w / 2) y1 = int(h / 2) cx = x + x1 cy = y + y1 return (cx, cy) def detect_vehicles(fg_mask, min_contour_width=35, min_contour_height=35): matches = [] # 发现外部轮廓 contours, hierarchy = cv2.findContours( fg_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_TC89_L1) # 根据高度,宽度进行过滤 for (i, contour) in enumerate(contours): # 找到其中一条轮廓,进行高和宽的过滤 (x, y, w, h) = cv2.boundingRect(contour) contour_valid = (w >= min_contour_width) and ( h >= min_contour_height) if not contour_valid: # 不满足过滤掉 continue # 得到边界框的中心 centroid = get_centroid(x, y, w, h) # 将轮廓加入数组中 matches.append(((x, y, w, h), centroid)) return matches
在出口处,我们按高度,宽度过滤然后添加质心。很简单,是吗?
Pipeline封装
你必须明白,在ML和CV中没有一个魔术算法可以处理所有事情,即使我们想象这样的算法存在,我们仍然不会使用它,因为它在规模上不会有效。
例如几年前,Netflix以300万美元的奖金为最佳电影推荐算法创造了竞争。其中一个团队创建了这样的问题,就是它无法大规模运作,因此对公司来说毫无用处。但是,Netflix仍为它们支付了100万美元:)
所以现在我们将构建简单的处理流程,它不仅仅是为了方便但规模相同的规模。
class PipelineRunner(object): ''' 非常简单的pipline。 只需按顺序运行处理程序,将上下文从一个传递到另一个。 您还可以为处理器设置日志级别。 ''' def __init__(self, pipeline=None, log_level=logging.DEBUG): self.pipeline = pipeline or [] self.context = {} self.log = logging.getLogger(self.__class__.__name__) self.log.setLevel(log_level) self.log_level = log_level self.set_log_level() def set_context(self, data): self.context = data def add(self, processor): if not isinstance(processor, PipelineProcessor): raise Exception( 'Processor should be an isinstance of PipelineProcessor.') processor.log.setLevel(self.log_level) self.pipeline.append(processor) def remove(self, name): for i, p in enumerate(self.pipeline): if p.__class__.__name__ == name: del self.pipeline[i] return True return False def set_log_level(self): for p in self.pipeline: p.log.setLevel(self.log_level) def run(self): for p in self.pipeline: self.context = p(self.context) self.log.debug("Frame #%d processed.", self.context['frame_number']) return self.context class PipelineProcessor(object): ''' 处理器的基类。 ''' def __init__(self): self.log = logging.getLogger(self.__class__.__name__)
作为输入构造函数将采取将按顺序运行的处理器列表。每个处理器都是这项工作的一部分。让我们创建轮廓检测处理器。
class ContourDetection(PipelineProcessor): ''' 检测移动物体。 这个处理器的目的是减去背景,获得移动物体 并使用cv2.findContours方法检测它们,然后过滤掉宽度和高度不符合的。 bg_subtractor - 背景减法器isinstance。 min_contour_width - 最小边界矩形宽度。 min_contour_height - 最小边界矩形高度。 save_image - 如果为True,则将检测到的对象掩码保存到文件中。 image_dir - 保存图像的位置(必须存在)。 ''' def __init__(self, bg_subtractor, min_contour_width=35, min_contour_height=35, save_image=False, image_dir='images'): super(ContourDetection, self).__init__() self.bg_subtractor = bg_subtractor self.min_contour_width = min_contour_width self.min_contour_height = min_contour_height self.save_image = save_image self.image_dir = image_dir def filter_mask(self, img, a=None): # 这个过滤器是根据视觉测试手工挑选的 kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (2, 2)) # 闭运算,填补任何小洞 closing = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel) # 开运算,去除噪音 opening = cv2.morphologyEx(closing, cv2.MORPH_OPEN, kernel) # 膨胀以合并相邻的小块 dilation = cv2.dilate(opening, kernel, iterations=2) return dilation def detect_vehicles(self, fg_mask, context): matches = [] # 发现外部轮廓 contours, hierarchy = cv2.findContours(fg_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_TC89_L1) for (i, contour) in enumerate(contours): # 找到其中一条轮廓,进行高和宽的过滤 (x, y, w, h) = cv2.boundingRect(contour) contour_valid = (w >= self.min_contour_width) and ( h >= self.min_contour_height) if not contour_valid: # 不满足过滤掉 continue # 得到边界框的中心 centroid = utils.get_centroid(x, y, w, h) # 将轮廓加入数组中 matches.append(((x, y, w, h), centroid)) return matches def __call__(self, context): frame = context['frame'].copy() frame_number = context['frame_number'] fg_mask = self.bg_subtractor.apply(frame, None, 0.001) # 只是阈值化 fg_mask[fg_mask < 240] = 0 fg_mask = self.filter_mask(fg_mask, frame_number) if self.save_image: #可选,保存过滤后的黑白图片 utils.save_frame(fg_mask, self.image_dir + "/mask_%04d.png" % frame_number, flip=False) #进行目标检测 context['objects'] = self.detect_vehicles(fg_mask, context) context['fg_mask'] = fg_mask return context
所以只需将bg减法,过滤和检测三个部分合并在一起。 现在让我们创建一个处理器,它将链接到不同帧上的检测对象,并创建路径,也将计算到达出口区域的车辆。
class VehicleCounter(PipelineProcessor): ''' 计算进入出口区域的车辆。 此类的目的是基于检测到的对象和本地缓存创建 对象修补和计数在退出区域中定义的退出区域中输入的对象。 exit_masks - 退出监测后的点集合列表。 path_size - 路径中的最大点数。 max_dst - 两点之间的最大距离。 ''' def __init__(self, exit_masks=[], path_size=10, max_dst=30, x_weight=1.0, y_weight=1.0): super(VehicleCounter, self).__init__() self.exit_masks = exit_masks self.vehicle_count = 0 self.path_size = path_size self.pathes = [] self.max_dst = max_dst self.x_weight = x_weight self.y_weight = y_weight def check_exit(self, point): for exit_mask in self.exit_masks: try: if exit_mask[point[1]][point[0]] == 255: return True except: return True return False def __call__(self, context): objects = context['objects'] context['exit_masks'] = self.exit_masks context['pathes'] = self.pathes context['vehicle_count'] = self.vehicle_count if not objects: return context points = np.array(objects)[:, 0:2] points = points.tolist() # 如果pathes为空,则添加新点 if not self.pathes: for match in points: self.pathes.append([match]) else: # 根据最小距离链接新点与旧路径 # points new_pathes = [] for path in self.pathes: _min = 999999 _match = None for p in points: if len(path) == 1: # distance from last point to current d = utils.distance(p[0], path[-1][0]) else: # 基于前2个点预测下一个点并计算 # 从预测的下一个点到当前的距离 xn = 2 * path[-1][0][0] - path[-2][0][0] yn = 2 * path[-1][0][1] - path[-2][0][1] d = utils.distance( p[0], (xn, yn), x_weight=self.x_weight, y_weight=self.y_weight ) if d < _min: _min = d _match = p if _match and _min <= self.max_dst: points.remove(_match) path.append(_match) new_pathes.append(path) # 如果当前帧没有匹配,则不丢弃路径 if _match is None: new_pathes.append(path) self.pathes = new_pathes # 添加新的pathes if len(points): for p in points: # 不添加已经计算的点数 if self.check_exit(p[1]): continue self.pathes.append([p]) # 仅保存路径中的最后N个点 for i, _ in enumerate(self.pathes): self.pathes[i] = self.pathes[i][self.path_size * -1:] # 计算车辆和去除计数pathes: new_pathes = [] for i, path in enumerate(self.pathes): d = path[-2:] if ( # 需要列表中的两点来计算 len(d) >= 2 and # 上一个点不是在出口区 not self.check_exit(d[0][1]) and # 当前点在出口区 self.check_exit(d[1][1]) and # path len 大于 path_size self.path_size <= len(path) ): self.vehicle_count += 1 else: # 禁止链接已经在退出区域中的路径 add = True for p in path: if self.check_exit(p[1]): add = False break if add: new_pathes.append(path) self.pathes = new_pathes context['pathes'] = self.pathes context['objects'] = objects context['vehicle_count'] = self.vehicle_count self.log.debug('#VEHICLES FOUND: %s' % self.vehicle_count) return context
这个类有点复杂,所以让我们按部分来看看。
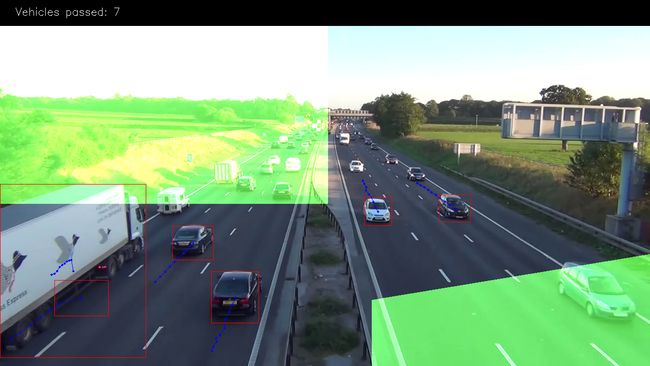

图像上的绿色面具是出口区域,是我们计算车辆的地方。例如,我们将仅计算长度超过3个点(以消除一些噪音)的路径和绿色区域中的第4个路径。 我们使用掩码导致它的许多操作比使用矢量算法更有效和简单。只需使用“二进制和”操作来检查该区域中的那个点,就是这样。这是我们如何设置它:
EXIT_PTS = np.array([ [[732, 720], [732, 590], [1280, 500], [1280, 720]], [[0, 400], [645, 400], [645, 0], [0, 0]] ]) base = np.zeros(SHAPE + (3,), dtype='uint8') exit_mask = cv2.fillPoly(base, EXIT_PTS, (255, 255, 255))[:, :, 0]
现在让我们在路径中链接点
# 根据最小距离链接新点与旧路径 # points new_pathes = [] for path in self.pathes: _min = 999999 _match = None for p in points: if len(path) == 1: # distance from last point to current d = utils.distance(p[0], path[-1][0]) else: # 基于前2个点预测下一个点并计算 # 从预测的下一个点到当前的距离 xn = 2 * path[-1][0][0] - path[-2][0][0] yn = 2 * path[-1][0][1] - path[-2][0][1] d = utils.distance( p[0], (xn, yn), x_weight=self.x_weight, y_weight=self.y_weight ) if d < _min: _min = d _match = p if _match and _min <= self.max_dst: points.remove(_match) path.append(_match) new_pathes.append(path) # 如果当前帧没有匹配,则不丢弃路径 if _match is None: new_pathes.append(path) self.pathes = new_pathes # 添加新的pathes if len(points): for p in points: # 不添加已经计算的点数 if self.check_exit(p[1]): continue self.pathes.append([p]) # 仅保存路径中的最后N个点 for i, _ in enumerate(self.pathes): self.pathes[i] = self.pathes[i][self.path_size * -1:]
在第一帧。我们只是将所有点添加为新路径。
接下来如果len(path)== 1,对于缓存中的每个路径,我们试图从新检测到的对象中找到点(质心),这些对象将具有到路径的最后一个点的最小欧几里德距离。
如果len(路径)> 1,那么路径中的最后两个点我们预测同一条线上的新点,并找到它与当前点之间的最小距离。
最小距离的点添加到当前路径的末尾并从列表中删除。
如果在此之后留下一些点,我们将它们添加为新路径。
而且我们也限制了路径中的点数。
# 计算车辆和去除计数pathes: new_pathes = [] for i, path in enumerate(self.pathes): d = path[-2:] if ( # 需要列表中的两点来计算 len(d) >= 2 and # 上一个点不是在出口区 not self.check_exit(d[0][1]) and # 当前点在出口区 self.check_exit(d[1][1]) and # path len 大于 path_size self.path_size <= len(path) ): self.vehicle_count += 1 else: # 禁止链接已经在退出区域中的路径 add = True for p in path: if self.check_exit(p[1]): add = False break if add: new_pathes.append(path) self.pathes = new_pathes context['pathes'] = self.pathes context['objects'] = objects context['vehicle_count'] = self.vehicle_count self.log.debug('#VEHICLES FOUND: %s' % self.vehicle_count)
现在我们将尝试计算进入出口区域的车辆。要做到这一点,我们只需要在路径中取最后两个点,然后检查出口区域中的最后一个点,而不是先前的点,并检查len(路径)是否应大于限制。
之后的部分是防止将新点反向链接到出口区域中的点。
最后两个处理器是CSV编写器,用于创建报告CSV文件,以及用于调试和漂亮图片的可视化。
class Visualizer(PipelineProcessor): def __init__(self, save_image=True, image_dir='images'): super(Visualizer, self).__init__() self.save_image = save_image self.image_dir = image_dir def check_exit(self, point, exit_masks=[]): for exit_mask in exit_masks: if exit_mask[point[1]][point[0]] == 255: return True return False # 绘制路径 def draw_pathes(self, img, pathes): if not img.any(): return for i, path in enumerate(pathes): path = np.array(path)[:, 1].tolist() for point in path: # 画出圆点和蓝色线条实现车尾尾随效果 cv2.circle(img, point, 2, CAR_COLOURS[0], -1) cv2.polylines(img, [np.int32(path)], False, CAR_COLOURS[0], 1) return img # 绘制包裹车的盒子 def draw_boxes(self, img, pathes, exit_masks=[]): for (i, match) in enumerate(pathes): contour, centroid = match[-1][:2] if self.check_exit(centroid, exit_masks): continue x, y, w, h = contour # 根据车的宽高,绘制出车的矩形大小 cv2.rectangle(img, (x, y), (x + w - 1, y + h - 1), BOUNDING_BOX_COLOUR, 1) cv2.circle(img, centroid, 2, CENTROID_COLOUR, -1) return img def draw_ui(self, img, vehicle_count, exit_masks=[]): # 这只是为图像添加不透明度的绿色遮罩 for exit_mask in exit_masks: _img = np.zeros(img.shape, img.dtype) _img[:, :] = EXIT_COLOR mask = cv2.bitwise_and(_img, _img, mask=exit_mask) cv2.addWeighted(mask, 1, img, 1, 0, img) # 在图片上面绘制计数结果 cv2.rectangle(img, (0, 0), (img.shape[1], 50), (0, 0, 0), cv2.FILLED) cv2.putText(img, ("Vehicles passed: {total} ".format(total=Zvehicle_count)), (30, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (255, 255, 255), 1) return img def __call__(self, context): frame = context['frame'].copy() frame_number = context['frame_number'] pathes = context['pathes'] exit_masks = context['exit_masks'] vehicle_count = context['vehicle_count'] frame = self.draw_ui(frame, vehicle_count, exit_masks) frame = self.draw_pathes(frame, pathes) frame = self.draw_boxes(frame, pathes, exit_masks) utils.save_frame(frame, self.image_dir + "/processed_%04d.png" % frame_number) return context
CSV编写器正在按时间保存数据,因为我们需要它来进行进一步的分析。所以我使用这个公式为unixtimestamp添加额外的帧时序:
time =((self.start_time + int(frame_number / self.fps))* 100+ int(100.0 / self.fps)*(frame_number%self.fps))
所以在开始时间= 1 000 000 000和fps = 10的情况下,我将得到像这样的结果 1 = 1 000 000 000 010 帧1 = 1 000 000 000 020 ...
然后,在获得完整的csv报告后,您可以根据需要聚合此数据。
检测过程生成视频
ffmpeg常用命令总结:https://blog.csdn.net/langzijing/article/details/85256846
下载网站:https://ffmpeg.zeranoe.com/builds/
执行命令:ffmpeg -start_number 0 -framerate 15 -i ./out/processed_%04d.png -s:v 1280:720 -c:v libx264 -profile:v high -crf 20 -pix_fmt yuv420p ./out.mp4
结论
所以你看,它并不像很多人想的那么难。
但是,如果您运行该脚本,您将看到此解决方案不理想,并且前景对象存在重叠问题,也没有按照类型对车辆分类(您肯定需要真正的分析)。但是,凭借良好的相机位置(在道路上方),它提供了非常好的准确性。这告诉我们,即使是以正确方式使用的小而简单的算法也能提供良好的结果。
那么我们可以做些什么来解决当前的问题呢?
一种方法是尝试添加一些额外的过滤,试图分离对象以便更好地检测。另一个是使用更复杂的算法,如深度卷积网络。
附加:
yolo 算法
论文标题: 《You Only Look Once: Unified, Real-Time Object Detection》 论文地址:https://arxiv.org/pdf/1506.02640.pdf
v1是yolo系列的开山之作,以简洁的网络结构,简单的复现过程而受到人们的追捧。 yolo_v1奠定了yolo系列算法“分而治之”的基调,在yolo_v1上,输入图片被划分为7X7的网格,如下图所示:
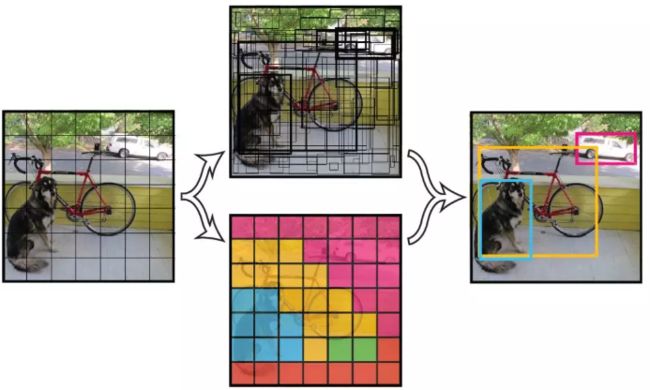

如上图所示,输入图片被划分为7x7个单元格,每个单元格独立作检测。 在这里很容易被误导:每个网格单元的视野有限而且很可能只有局部特征,这样就很难理解yolo为何能检测比grid_cell大很多的物体。其实,yolo的做法并不是把每个单独的网格作为输入feed到模型,在inference的过程中,网格只是物体中心点位置的划分之用,并不是对图片进行切片,不会让网格脱离整体的关系。


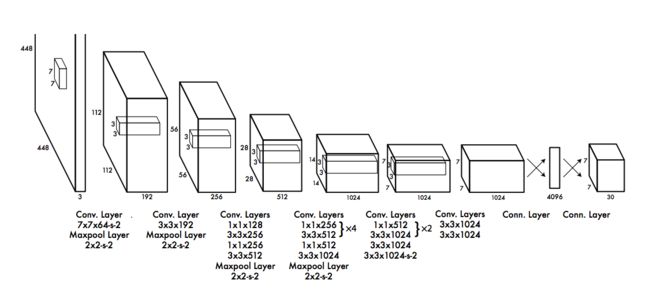
可以通过yolo_v1的structure来进一步理解,相比一些复杂的网络结构而言,yolo_v1的网络结构显得亲民得多。基本思想是这样:预测框的位置、大小和物体分类都通过CNN暴力predict出来。

具体训练过程:https://blog.csdn.net/guleileo/article/details/80581858
总结: v1对于整个yolo系列的价值,即v2/v3还保留的特性,可以总结为3点:
-
使用了leaky ReLU,相比普通ReLU,leaky并不会让负数直接为0
-
分而治之,用网格来划分图片区域,每块区域独立检测目标;
-
端到端训练。损失函数的反向传播可以贯穿整个网络,这也是one-stage检测算法的优势。
YOLO局限性:
由于YOLO具有极强的空间限制,它限制了模型在邻近物体上的预测,如果两个物体出现在同一个cell中,模型只能预测一个物体,所以在小物体检测上会出问题。另外模型对训练数据中不包含的物体或具有异常长宽比的物体扩展不是太好。loss函数对大小bbox采取相同的error也是个问题。
西电的一个真实项目:https://www.jianshu.com/p/f9348a21051c
效果:
