一、简介
categorical是pandas中对应分类变量的一种数据类型,与R中的因子型变量比较相似,例如性别、血型等等用于表征类别的变量都可以用其来表示,本文就将针对categorical的相关内容及应用进行介绍。
二、创建与应用
2.1 基本特性和适用场景
在介绍具体方法之前,我们需要对pandas数据类型中的categorical类型有一个了解,categorical类似R中的因子型变量,可以进行排序操作,但不可以进行数值运算操作,其顺序在其被定义的时候一同确定,而不是按照数字字母词法排序的顺序,其适用场景有如下几个:
1、具有少数几种可能取值并存在大量重复的字符串字段,利用categorical类型对其转换后可有效节省内存
2、字段的排序规则特殊,不遵循词法顺序时,可以利用categorical类型对其转换后得到用户所需的排序规则、
2.2 创建方式
pandas中创建categorical型数据主要有如下几种方式:
1、对于Series数据结构,传入参数dtype='category'即可:
#直接创建categorical型Series series_cat = pd.Series(['B','D','C','A'], dtype='category') #显示Series信息 series_cat

可以看到,series_cat的类型为category,但是没有声明顺序,这时若对Series排序,实际上还是按照词法的顺序:
series_cat.sort_values()

2、对于DataFrame,在定义数据之后转换类型:
#创建数据框 df_cat = pd.DataFrame({ 'V1':['A','C','B','D'] }) #转换指定列的数据类型为category df_cat['V1'] = df_cat['V1'].astype('category') df_cat['V1']

3、利用pd.Categorical()生成类别型数据后转换为Series,或替换DataFrame中的内容:
categorical_ = pd.Categorical(['A','B','D','C'], categories=['A','B','C','D']) series_cat = pd.Series(categorical_) series_cat

categorical_ = pd.Categorical(['A','B','D','C'], categories=['A','B','C','D']) df_cat = pd.DataFrame({ 'V1':categorical_ }) df_cat['V1']

而pd.Categorical()独立创建categorical数据时有两个新的特性,一是其通过参数categories定义类别时,若原数据中出现了categories参数中没有的数据,则会自动转换为pd.nan:
categorical_ = pd.Categorical(['A','B','D','C'], categories=['B','C','D']) df_cat = pd.DataFrame({ 'V1':categorical_ }) df_cat['V1']

另外pd.Categorical()还有一个bool型参数ordered,设置为True时则会按照categories中的顺序定义从小到大的范围:
categorical_ = pd.Categorical(['A','B','D','C'], categories=['A','B','C','D'], ordered=True) df_cat = pd.DataFrame({ 'V1':categorical_ }) df_cat['V1']

4、利用pandas.api.types中的CategoricalDtype()对已有数据进行转换
通过CategoricalDtype(),我们可以结合astype()完成从其他类型数据向categorical数据的转换过程,利用CategoricalDtype()的参数categories、ordered,弥补.astype('category')的短板(实际上.astype('category')等价于.astype(CategoricalDtype(categories=None, ordered=False))):
from pandas.api.types import CategoricalDtype #创建数据框 df_cat = pd.DataFrame({ 'V1':['A','C','B','D'] }) cat = CategoricalDtype(categories=['A','C','B'], ordered=True) df_cat['V1'] = df_cat['V1'].astype(cat) df_cat['V1']

2.3 应用
categorical型数据主要应用于自定义排序,如下例,我们创建了一个包含字符型变量class和数值型变量value的数据框:
import numpy as np df = pd.DataFrame({ 'class':np.random.choice(['A','B','C','D'],10), 'value':np.random.uniform(0,10,10) }) df.head()
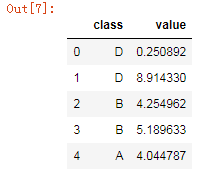
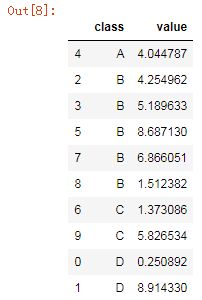
如果按照class列排序得到的结果是按照字母自然顺序:
df.sort_values('class')
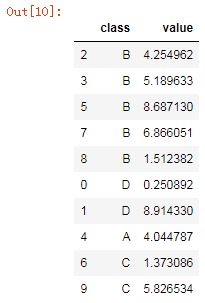
而通过将class列修改为自己定义的排序方式则得到的结果如下:
from pandas.api.types import CategoricalDtype cat = CategoricalDtype(categories=['B','D','A','C'], ordered=True) df['class'] = df['class'].astype(cat) df.sort_values('class')
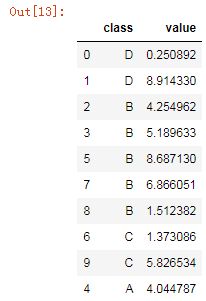
若想要临时修改排序规则,可以使用.cat.reorder_categories()方法:
df['class'].cat.reorder_categories(['D','B','C','A'], ordered=True, inplace=True)#iinplace参数设置为True使得变动覆盖原数据 df.sort_values('class')
关于pandas中的categorical型数据还有很多的小技巧,因为不常用这里就不再赘述,感兴趣可以查看pandas的官方文档,以上就是本文的全部内容,如有笔误望指出!