大家好,我是痞子衡,是正经搞技术的痞子。今天痞子衡给大家介绍的是语音处理工具Jays-PySPEECH诞生之文语合成实现。
文语合成是Jays-PySPEECH的核心功能,Jays-PySPEECH借助的是pyttsx3以及eSpeak引擎来实现的文语合成功能,今天痞子衡为大家介绍文语合成在Jays-PySPEECH中是如何实现的。
一、pyttsx3简介
pyttsx3是一套基于实现SAPI5文语合成引擎的Python封装库,该库的设计者为Natesh M Bhat,该库其实是 pyTTS 和 pyttsx 项目的延续,pyttsx3主要是为Python3版本设计的,但同时也兼容Python2。JaysPySPEECH使用的是pyttsx3 2.7。
pyttsx3系统的官方主页如下:
- pyttsx3官方主页: https://github.com/nateshmbhat/pyttsx3
- pyttsx3安装方法: https://pypi.org/project/pyttsx3/
pyttsx3的使用足够简单,其官方文档 https://pyttsx3.readthedocs.io/en/latest/engine.html 半小时即可读完,下面是最简单的一个示例代码:
import pyttsx3;
engine = pyttsx3.init();
engine.say("I will speak this text");
engine.runAndWait() ;1.1 Microsoft Speech API (SAPI5)引擎
前面痞子衡讲了pyttsx3基于的文语合成内核是SAPI5引擎,这是微软公司开发的TTS引擎,其官方主页如下:
- SAPI5官方文档: https://docs.microsoft.com/en-us/previous-versions/windows/desktop/ms723627(v%3dvs.85)
由于pyttsx3已经将SAPI5封装好,所有我们没有必要关注SAPI5本身的TTS实现原理。
1.2 确认PC支持的语音包
在使用pyttsx3进行文语合成时,依赖的是当前PC的语音环境,打开控制面板(Control Panel)->语言识别(Speech Recognition),可见到如下页面:

痞子衡使用的PC是Win10英文版,故默认仅有英文语音包(David是男声,Zira是女声),这点也可以使用如下pyttsx3调用代码来确认:
import pyttsx3;
ttsObj = pyttsx3.init()
voices = ttsObj.getProperty('voices')
for voice in voices:
print ('id = {} \nname = {} \n'.format(voice.id, voice.name))代码运行结果如下:
id = HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Speech\Voices\Tokens\TTS_MS_EN-US_DAVID_11.0 name = Microsoft David Desktop - English (United States) id = HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Speech\Voices\Tokens\TTS_MS_EN-US_ZIRA_11.0 name = Microsoft Zira Desktop - English (United States)
1.3 为PC增加语音包支持
要想在使用Jays-PySPEECH时可以实现中英双语合成,要确保PC上既有英文语音包也有中文语音包,痞子衡PC上当前仅有英文语音包,故需要安装中文语音包(安装其他语言语音包的方法类似)。
Windows系统下中文语音包有很多,可以使用第三方公司提供的语音包(比如 NeoSpeech公司 ),也可以使用微软提供的语音包,痞子衡选用的是经典的慧慧语音包(zh-CN_HuiHui)。
进入 Microsoft Speech Platform - Runtime (Version 11) 和 Microsoft Speech Platform - Runtime Languages (Version 11) 下载页面将选中文件下载(亲测仅能用Google Chrome浏览器才能正常访问,IE竟然也无法打开):

先安装SpeechPlatformRuntime.msi(双击安装即可),安装完成之后重启电脑,再安装MSSpeech_TTS_zh-CN_HuiHui.msi,安装结束之后需要修改注册表,打开Run(Win键+R键)输入"regedit"即可看到如下registry编辑界面,HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Speech\Voices路径下可以看到默认语音包(DAVID, ZIRA),HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Speech Server\v11.0\Voices路径下可看到新安装的语音包(HuiHui):
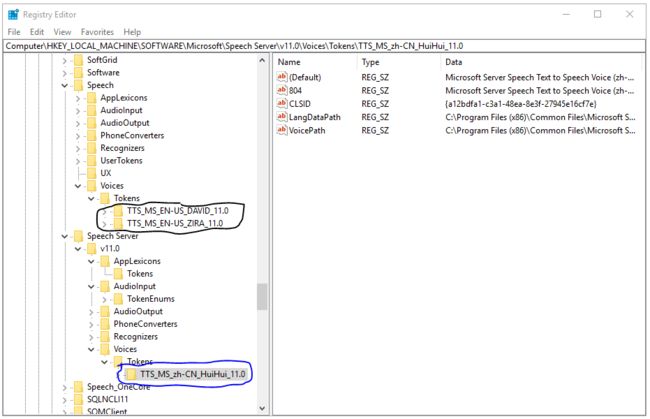
右键HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Speech Server\v11.0\Voices,将其导出成.reg文件,使用文本编辑器打开这个.reg文件将其中"\Speech Server\v11.0"全部替换成"\Speech"并保存,然后将这个修改后的.reg文件再导入注册表。

导入成功后,便可在注册表和语音识别选项里看到Huihui身影:

Note: 上述修改仅针对32bit操作系统,如果是64bit系统,需要同时将HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\Microsoft\Speech Server\v11.0\Voices路径的注册表按同样方法也操作一遍。
二、eSpeak简介
由于pyttsx3仅能在线发声,无法将合成后的语音保存为wav文件,因此痞子衡需要为JaysPySPEECH再寻一款可以保存为wav的TTS引擎。痞子衡选中的是eSpeak,eSpeak是一个简洁的开源语音合成软件,用C语言写成,支持英语和其他很多语言,同时也支持SAPI5接口,合成的语音可以导出为wav文件。
eSpeak的官方主页如下:
- eSpeak官方主页: http://espeak.sourceforge.net/
- eSpeak下载安装: http://espeak.sourceforge.net/download.html
- eSpeak补充语言包: http://espeak.sourceforge.net/data/index.html
eSpeak从标准输入或者输入文件中读取文本,虽然语音输出与真人声音相去甚远,但是在项目需要的时候,eSpeak仍不失为一个简便快捷的工具。
痞子衡将eSpeak 1.48.04安装在了C:\tools_mcu\eSpeak路径下,进入这个路径可以找到\eSpeak\command_line\espeak.exe,这便是我们需要调用的工具,为了方便调用,你需要将"C:\tools_mcu\eSpeak\command_line"路径加入系统环境变量Path中。
关于中文支持,在\eSpeak\espeak-data\zh_dict文件里已经包含了基本的中文字符,但是如要想要完整的中文支持,还需要下载zh_listx.zip中文语音包,解压后将里面的zh_listx文件放到\eSpeak\dictsource目录下,并且在\eSpeak\dictsource路径下执行命令"espeak --compile=zh",执行成功后可以看到\eSpeak\espeak-data\zh_dict文件明显变大了。
eSpeak对于python来说是个外部程序,我们需要借助subprocess来调用espeak.exe,下面是示例代码:
import subprocess
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
enText = "Hello world"
zhText = u"你好世界"
txtFile = "C:/test.txt" #文件内为中文
wavFile = "C:/test.wav"
# 在线发音(-v是设置voice,en是英文,m3男声,zh是中文,f3是女声)
subprocess.call(["espeak", "-ven+m3", enText])
subprocess.call(["espeak", "-vzh+f3", zhText])
# 保存为wav文件(第一种方法仅能保存英文wav,如果想保存其他语言wav需要使用第二种方法)
subprocess.call(["espeak","-w"+wavFile, enText])
subprocess.call(["espeak","-vzh+f3", "-f"+txtFile, "-w"+wavFile])如果想直接体验eSpeak的发音质量,可以直接打开\eSpeak\TTSApp.exe应用程序,软件使用非常简单:

三、Jays-PySPEECH文语合成实现
文语合成实现主要分为两部分:TTS, TTW。实现TTS需要import pyttsx3,实现TTW需要借助subprocess调用eSpeak,下面 痞子衡分别介绍这两部分的实现:
3.1 Text-to-Speech实现
TTS代码实现其实很简单,目前仅实现了pyttsx3引擎,并且仅支持中英双语识别。具体到Jays-PySPEECH上主要是实现GUI界面上"TTS"按钮的回调函数,即textToSpeech(),如果用户选定了配置参数(语言类型、发音人类型、TTS引擎类型),并点击了"TTS"按钮,此时便会触发textToSpeech()的执行。代码如下:
reload(sys)
sys.setdefaultencoding('utf-8')
import pyttsx3
class mainWin(win.speech_win):
def __init__(self, parent):
# ...
self.ttsObj = None
def refreshVoice( self, event ):
languageType, languageName = self.getLanguageSelection()
engineType = self.m_choice_ttsEngine.GetString(self.m_choice_ttsEngine.GetSelection())
if engineType == 'pyttsx3 - SAPI5':
if self.ttsObj == None:
self.ttsObj = pyttsx3.init()
voices = self.ttsObj.getProperty('voices')
voiceItems = [None] * len(voices)
itemIndex = 0
for voice in voices:
voiceId = voice.id.lower()
voiceName = voice.name.lower()
if (voiceId.find(languageType.lower()) != -1) or (voiceName.find(languageName.lower()) != -1):
voiceItems[itemIndex] = voice.name
itemIndex += 1
voiceItems = voiceItems[0:itemIndex]
self.m_choice_voice.Clear()
self.m_choice_voice.SetItems(voiceItems)
else:
voiceItem = ['N/A']
self.m_choice_voice.Clear()
self.m_choice_voice.SetItems(voiceItem)
def textToSpeech( self, event ):
# 获取语音语言类型(English/Chinese)
languageType, languageName = self.getLanguageSelection()
# 从asrttsText文本框获取要转换的文本
lines = self.m_textCtrl_asrttsText.GetNumberOfLines()
if lines != 0:
data = ''
for i in range(0, lines):
data += self.m_textCtrl_asrttsText.GetLineText(i)
else:
return
ttsEngineType = self.m_choice_ttsEngine.GetString(self.m_choice_ttsEngine.GetSelection())
if ttsEngineType == 'pyttsx3 - SAPI5':
# 尝试创建pyttsx3文语合成对象ttsObj
if self.ttsObj == None:
self.ttsObj = pyttsx3.init()
# 搜索当前PC是否存在指定语言类型的发声人
hasVoice = False
voices = self.ttsObj.getProperty('voices')
voiceSel = self.m_choice_voice.GetString(self.m_choice_voice.GetSelection())
for voice in voices:
#print ('id = {} \nname = {} \nlanguages = {} \n'.format(voice.id, voice.name, voice.languages))
voiceId = voice.id.lower()
voiceName = voice.name.lower()
if (voiceId.find(languageType.lower()) != -1) or (voiceName.find(languageName.lower()) != -1):
if (voiceSel == '') or (voiceSel == voice.name):
hasVoice = True
break
if hasVoice:
# 调用pyttsx3里的say()和runAndWait()完成文语合成,直接在线发音
self.ttsObj.setProperty('voice', voice.id)
self.ttsObj.say(data)
self.statusBar.SetStatusText("TTS Conversation Info: Run and Wait")
self.ttsObj.runAndWait()
self.statusBar.SetStatusText("TTS Conversation Info: Successfully")
else:
self.statusBar.SetStatusText("TTS Conversation Info: Language is not supported by current PC")
self.textToWav(data, languageType)
else:
self.statusBar.SetStatusText("TTS Conversation Info: Unavailable TTS Engine")3.2 Text-to-Wav实现
TTW代码实现也很简单,目前仅实现了eSpeak引擎,并且仅支持中英双语识别。具体到Jays-PySPEECH上主要是实现GUI界面上"TTW"按钮的回调函数,即textToWav(),如果用户选定了配置参数(发音人性别类型、TTW引擎类型),并点击了"TTW"按钮,此时便会触发textToWav()的执行。代码如下:
import subprocess
class mainWin(win.speech_win):
def textToWav(self, text, language):
fileName = self.m_textCtrl_ttsFileName.GetLineText(0)
if fileName == '':
fileName = 'tts_untitled1.wav'
ttsFilePath = os.path.join(os.path.dirname(os.path.abspath(os.path.dirname(__file__))), 'conv', 'tts', fileName)
ttwEngineType = self.m_choice_ttwEngine.GetString(self.m_choice_ttwEngine.GetSelection())
if ttwEngineType == 'eSpeak TTS':
ttsTextFile = os.path.join(os.path.abspath(os.path.dirname(__file__)), 'ttsTextTemp.txt')
ttsTextFileObj = open(ttsTextFile, 'wb')
ttsTextFileObj.write(text)
ttsTextFileObj.close()
try:
#espeak_path = "C:/tools_mcu/eSpeak/command_line/espeak.exe"
#subprocess.call([espeak_path, "-v"+languageType[0:2], text])
gender = self.m_choice_gender.GetString(self.m_choice_gender.GetSelection())
gender = gender.lower()[0] + '3'
# 调用espeak.exe完成文字到wav文件的转换
subprocess.call(["espeak", "-v"+language[0:2]+'+'+gender, "-f"+ttsTextFile, "-w"+ttsFilePath])
except:
self.statusBar.SetStatusText("TTW Conversation Info: eSpeak is not installed or its path is not added into system environment")
os.remove(ttsTextFile)
else:
self.statusBar.SetStatusText("TTW Conversation Info: Unavailable TTW Engine")至此,语音处理工具Jays-PySPEECH诞生之文语合成实现痞子衡便介绍完毕了,掌声在哪里~~~