此学习笔记整理于 Ryan Mitchell Web Scraping with Python- Collecting Data from the Modern Web (2015) Chapter Storing data
一,urlretrieve

urlretrieve 是urllib.request里面的一个函数,知道了文件在html结构里面的位置就可以取回文件了。例子中,位置是imageLocation 那一句。urlretrieve(位置,‘另存为的文件名称’)。作者又给了一个复杂的例子,取出所有的某类文件。但是作者技术高超,用了函数。感觉不是那么容易理解。于是我照着逻辑又写了一个没有函数的,逻辑很清晰。写完了之后发现,作者的也很清晰,看来还是得自己写一写,才能理解好代码的逻辑。

我们从for 开始看,downloadList 是我找的所有的img tag。整个的if 一直到第25行都是为了获取图片的网址,前边的替换就是为了让他们的形式一致。因为可能有些事http://开头,有些是www.开头。24,25行是为了筛选:只筛选出网页内部链接图片。
26-30,给出存储电脑的位置。我们需要在代码最开始引进 import 一个新的库。os 这个os,是Python能够和operation system对话的一个库。
32以后其实算是创建这些电脑路径吧,如果这个文件(包括路径)不存在就创建一个。
第35句代码,忘了截上去。urlretrieve(url,path),你知道需要缩进多少吗?(Python的语法比较简单,没有vba类似的end if, next 等,它的语法判断有一部分是根据缩进量来判断层次的)
二,存储为CSV文件

新引进了一个库,csv
注意第八行!为什么要加一个【0】,是因为,findAll返回的是一个列表,而列表不能继续向下find了。
注意第11行!为什么加一个newline和为什么加一个encoding
为什么要有一个newline=‘’,因为不写的话,会。。。下面网页打开就知道了哦。
http://codepub.cn/2015/10/08/Using-the-Python-CSV-module-to-read-and-write-CSV-file/
encoding 为了防止出现编码错误,utf-8 支持所有的编码类型。
注意16行,这样也是为了从列表取出单独的东西来分析。而不是列表类型的数据。
注意15和17行,为什么要加一个列表来作过度,要不然就是一个字母一个表格存储的。
不写的话,会隔行产生空行。
三,关于元组 tuple(), 列表list[],集合set{},字典{:,:}
这一个,我也分不大清楚。也没想着分多大清楚,肯定对我学习造成了一定的障碍。但我觉得,当我需要分清楚的时候再来看看用到的分别在哪里再来记住。所以我主要看下面这个网站:
http://rmingwang.com/python-tuple-list-dict-set.html
还有关于Python的基础知识,随便找个公开课看下就好了,这些东西主要看自己。所以不要沉迷在搜索,下载,再搜索,下载的loop里面无法自拔!(对,我就是一直在这个loop里面)
四, mysql来存储
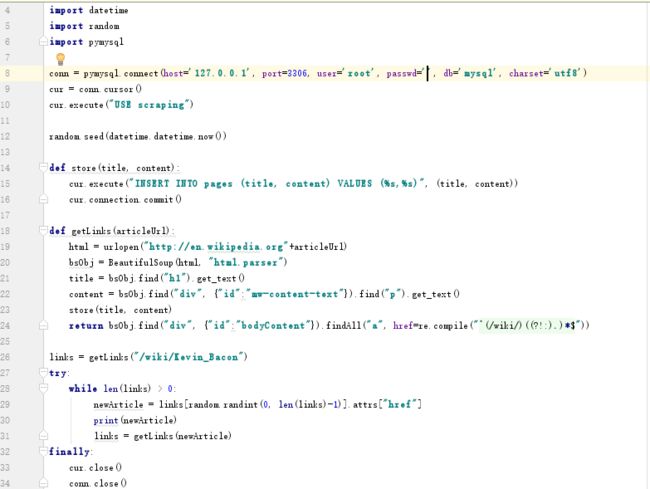
作者首先简单介绍了mysql的语言,在这里我就不多说了,因为我也不精通,只是学过sas里面的sql。
还是解释上面的代码:
conn是先连接上mysql,这句代码仅适用于windows平台,passwd应该是你的mysql的密码。
cur=conn.cur 这里我们相当于在一个数据库里选择了一个服务员,我们通过Ta来进行数据的操作。
第十行,use scraping,这是一个数据库scraping。首先你得有一个数据库。关于如何建立一个数据库,请移步百度或者google。
然后是两个函数,
一个是把链接内的title和content存储到scraping这个数据库。15行,我也看不大懂,先记下了。%s 作者用的是“\%s”,这两种表示都可以,我也不清楚,可能跟formating string 有关。16行,是确认订单的意思。告诉这个服务员就这些了。不告诉ta,做的修改无法保存到数据库。
另外一个是获取用以存储的数据并返回这个link里面的其他link以备循环。
try and finally,作者说了,爬虫一般都来加一个好了。finally 是用来结束while 这个loop的时候用的。告诉服务员自己要走了,然后断开连接。
作者当然很好心地告诉了我们一些tricks。第一:primary key选择id 自动增加。二,建立索引。三,把大的数据库拆分成小的。(爬取过程中的重复数据,可以用这个方法,每一种属性来一个小数据库,然后再加一个重复次数的数据库,大大减少了重复数据的存储量。
P.S.:没能上车的小伙伴欢迎留言,如果我会我直接回答你!如果不会,我谷歌后回答你!如果要加我微信,不行。