Spark Sql-Sql解析
1. Sql语句的通用执行过程分析
sql语句在分析执行过程中会经历如下的几个步骤:
- 语法解析
- 操作绑定
- 优化执行策略
- 交付执行

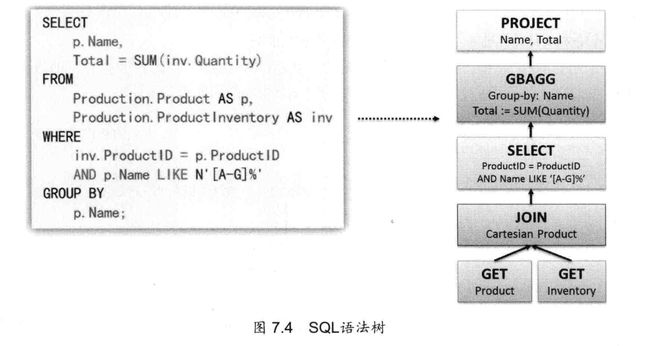
语法解析之后,会形成一个语法树。书中的每个节点是执行的规则(rule),整个书被称为执行策略。
2. SQL ON Spark
有了上述的铺垫,我们意识到spark很好的支持sql,也要完成解析,优化,执行的三个过程。
整个sql部分的代码大致分类:

处理顺序:
- sqlparser 生成 unresolved logical plan
- analyzer 生成logical plan
- optimizer 生成 optimized logical plan
- planner 生成sparkplan
- 最终sparkplan生成rdd
- 最终将生成的rdd交给spark执行。
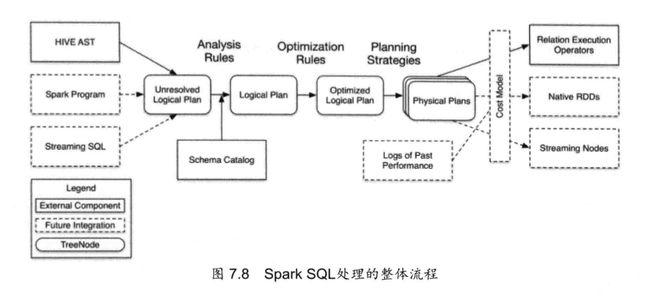
以下按照这个顺序详细介绍。
2.1 Sqlparse
sqlcontext中定义的sql函数用以解析身材个好难过schemaRDD
def sql(sqlText:String):SchemaRDD=new SchemaRDD(this,parseSql(sqltext))
def parseSql(sql:String):LogicalPlan=parser(sql)

由于apply函数不被显式的调用,调用parsesql的时候会隐shi调用apply函数。


2.2 analyzer
第一阶段,将string转换为unresolved logicalplan ,第二阶段将unresolved对象变成resolved的。
由于scala支持惰性计算。所以真正需要执行job的时候买才会进行分析和优化。


queryexecution在处理过程中分三大步。这三大步主要分两个阶段,一个是logical plan的处理,一个是physicalplan的处理。
无论是analyzier还是optimizer都是ruleexecutor的子类。

默认处理函数是apply。
apply中用到batches,batches定义了一系列规则。
有了这么多的rules后,我们开看unresolved logicalplan如何被处理的。
所谓的unresolved logicalplan,用一个直白的话来表示就是要找到数据源是什么。在sqlparse阶段,尽管知道people是一个表明,但是不知道真正的数据存储在哪。儿resolveRelations就是解决这个问题的。

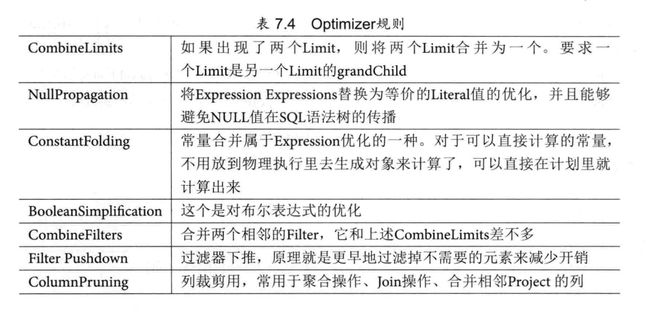
2.3 optimizer
optimizer部分所做的操作就是对logicalplan进行优化。
2.4 planner
经过sqlparser—>analyzer—>optimizer,现在需要将logicalplan转换为rdd,才能在spark cluster上真正的进行数据分析。
logicalplan到rdd的转换过程引入了sparkplan。sparkplan的任务是生成rdd,在此之前是logicalplan到sparkplan的转换过程。
lazy val sparkplan=planner(optimizedPlan).next()
生成rdd
lazy val executeplan:SparkPlan=prepareForExecution(sparkPlan)
lazy val toRDD:RDD[Row]=executedPlan.execute()
SparkPlanner:LogicalPlan—>SparkPlan
sparkplanner利用sparkstrategies将logicalplan转换为sparkplan。

planner会调用丁酉queryplanner的apply函数。调用关系如下:
//sparkplanner
override def plan(plan: LogicalPlan): Iterator[SparkPlan] = {
super.plan(plan).map {
_.transformUp {
case PlanLater(p) =>
// TODO: use the first plan for now, but we will implement plan space exploaration later.
this.plan(p).next()
}
}
}
//QueryPlanner
abstract class QueryPlanner[PhysicalPlan <: TreeNode[PhysicalPlan]] {
/** A list of execution strategies that can be used by the planner */
def strategies: Seq[GenericStrategy[PhysicalPlan]]
def plan(plan: LogicalPlan): Iterator[PhysicalPlan] = {
// Obviously a lot to do here still...
val iter = strategies.view.flatMap(_(plan)).toIterator
assert(iter.hasNext, s"No plan for $plan")
iter
}
}
策略定义
def strategies: Seq[Strategy] =
extraStrategies ++ (
FileSourceStrategy ::
DataSourceStrategy ::
DDLStrategy ::
SpecialLimits ::
Aggregation ::
JoinSelection ::
InMemoryScans ::
BasicOperators :: Nil)

ps:一些join的解释:
- join
- outer join
- semi join
与logicalplan不同的是sparkplan最重要的区别就是有execute函数。针对具体实现又可以分为unarynode leafnode binarynode,简单来说就是单目运算符操作,叶子结点,双目运算符操作。
3. parquet & json
