selenium动态网页请求与模拟登录知乎
Selenium 架构图

Selenium python api
http://selenium-python.readthedocs.io/index.html
http://selenium-python-zh.readthedocs.io/en/latest/index.html
事实上,Selenium 只是一个中间的 API 接口,他可以通过 Driver 来驱动浏览器

- Selenium 动态网页请求
打开一个天猫商城的商品,f12 分析页面,查看价格在 class="tm-price" 的 span 标签中

右键查看网页源代码,在源代码中搜索商品价格是搜索不到的,这个时候 Selenium 的优势就体现出来了

只需要短短几行代码就可以通过 Selenium 操控浏览器打来天猫商品网址,打印页面源码,发现可以搜索到商品价格
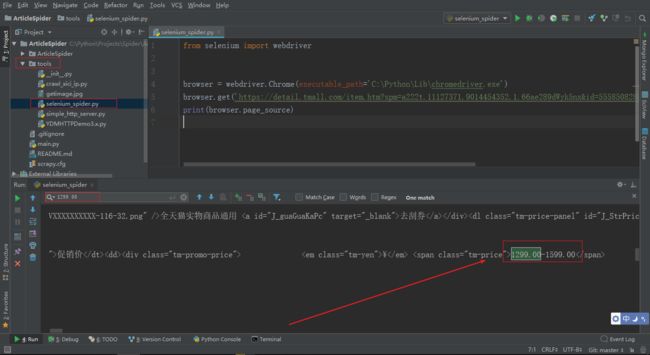
Selenium 会自动打开 Chrome 浏览器
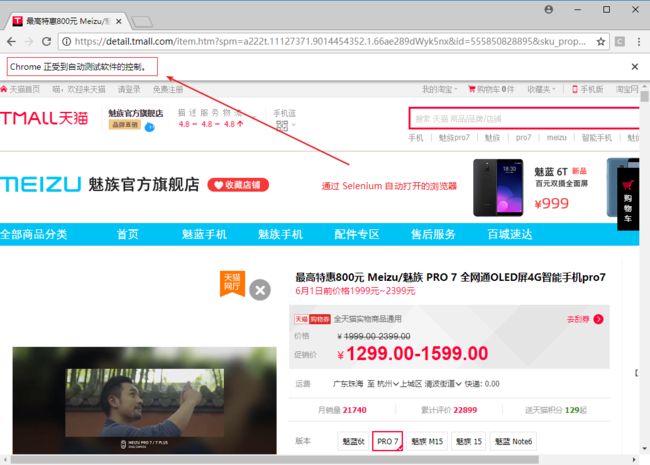
可以通过两种不同方式提取商品价格,推荐使用 Scrapy Selector,因为是 C 语言写的,速度快,Selenium 是 纯 Python 写的,速度慢

完整测试代码
# tools/selenium_spider.py
from selenium import webdriver
from scrapy.selector import Selector
browser = webdriver.Chrome(executable_path='C:\Python\Lib\chromedriver.exe')
browser.get('https://detail.tmall.com/item.htm?spm=a222t.11127371.9014454352.1.66ae289dWyk5nx&id=555850828895&sku_properties=10004:827902415;5919063:6536025')
# print(browser.page_source)
# 通过 Scrapy 的 Selector 提取商品价格
selector = Selector(text=browser.page_source)
price = selector.xpath('//span[@class="tm-price"]/text()').extract_first()
print(price)
# 通过 Selenium 提取商品价格
price = browser.find_element_by_class_name('tm-price').text
print(price)
browser.quit()
- Selenium 模拟登录知乎
因为知乎再一次改版,不登录也可以访问首页了,所以这里演示的模拟登录和之前写的 zhihu_login spider 登录的时候情况不同了

知乎现在的登录逻辑是:访问首页后,点击右侧登录按钮,弹出弹层,输入用户名、密码,再点击弹层底部登录按钮,进行登录

Selenium 模拟登录知乎完整代码
# tools/selenium_login_zhihu.py
"""
selenium 模拟登录知乎
"""
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.zhihu.com/')
button = browser.find_element_by_css_selector('.HomeSidebar-signBannerActions button[data-za-detail-view-id="2278"]')
button.click()
username = browser.find_element_by_css_selector('input[name="username"]')
username.send_keys('username')
password = browser.find_element_by_css_selector('input[name="password"]')
password.send_keys('password')
login_button = browser.find_element_by_css_selector('.Button.SignFlow-submitButton.Button--primary.Button--blue')
login_button.click()
# browser.quit()
selenium模拟登录微博, 模拟鼠标下拉
- Selenium模拟登录微博
思路同知乎模拟登录一样,分析并定位微博账号登录输入框以及登录按钮

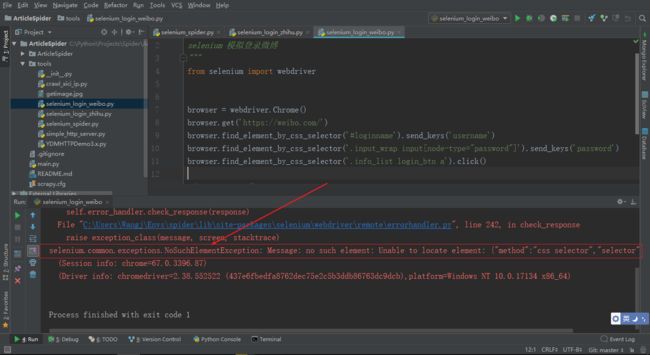
运行代码发现报错,找不到 id 为 loginname 的元素,原因是页面还没有加载完成就执行到了这一步,所以没有找到登录微博账号的输入框
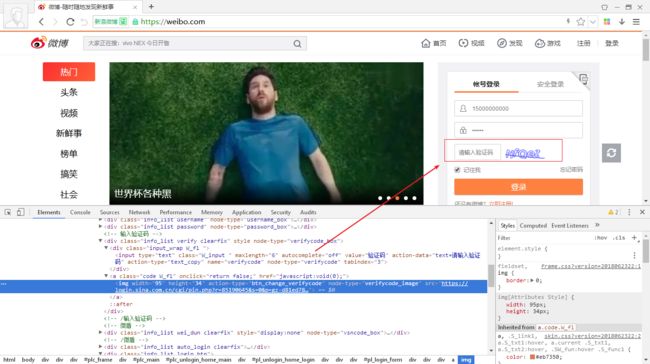
分析发现现在微博每次登录都需要验证码,所以结合云打码平台识别验证码,来实现模拟登录
Selenium 模拟登录微博完整代码
# tools/selenium_login_weibo.py
"""
selenium 模拟登录微博
"""
import time
from selenium import webdriver
from scrapy.selector import Selector
import requests
from tools.YDMHTTPDemo3 import get_verifycode
browser = webdriver.Chrome()
browser.get('https://weibo.com/')
time.sleep(15) # 等待页面加载完成
browser.find_element_by_css_selector('#loginname').send_keys('username')
browser.find_element_by_css_selector('.input_wrap input[node-type="password"]').send_keys('password')
time.sleep(3) # 等待出现验证码
selector = Selector(text=browser.page_source)
verifycode_image_url = selector.xpath('//a[@class="code W_fl"]/img/@src').extract_first()
verifycode_image = requests.get(verifycode_image_url)
with open('weibo.jpg', 'wb') as f: # 将验证码写入本地文件
f.write(verifycode_image.content)
result = get_verifycode() # 通过云打码平台识别验证码
browser.find_element_by_css_selector('.input_wrap.W_fl input[node-type="verifycode"]').send_keys(result)
browser.find_element_by_css_selector('.info_list.login_btn a').click()
# browser.quit()
为了在 selenium_login_weibo.py 中导入方便,这里代码稍作了修改
# tools/YDMHTTPDemo3.py
import http.client
import mimetypes
import urllib
import json
import time
import requests
class YDMHttp:
apiurl = 'http://api.yundama.com/api.php'
username = ''
password = ''
appid = ''
appkey = ''
def __init__(self, username, password, appid, appkey):
self.username = username
self.password = password
self.appid = str(appid)
self.appkey = appkey
def request(self, fields, files=[]):
response = self.post_url(self.apiurl, fields, files)
response = json.loads(response)
return response
def balance(self):
data = {'method': 'balance', 'username': self.username, 'password': self.password, 'appid': self.appid,
'appkey': self.appkey}
response = self.request(data)
if (response):
if (response['ret'] and response['ret'] < 0):
return response['ret']
else:
return response['balance']
else:
return -9001
def login(self):
data = {'method': 'login', 'username': self.username, 'password': self.password, 'appid': self.appid,
'appkey': self.appkey}
response = self.request(data)
if (response):
if (response['ret'] and response['ret'] < 0):
return response['ret']
else:
return response['uid']
else:
return -9001
def upload(self, filename, codetype, timeout):
data = {'method': 'upload', 'username': self.username, 'password': self.password, 'appid': self.appid,
'appkey': self.appkey, 'codetype': str(codetype), 'timeout': str(timeout)}
file = {'file': filename}
response = self.request(data, file)
if (response):
if (response['ret'] and response['ret'] < 0):
return response['ret']
else:
return response['cid']
else:
return -9001
def result(self, cid):
data = {'method': 'result', 'username': self.username, 'password': self.password, 'appid': self.appid,
'appkey': self.appkey, 'cid': str(cid)}
response = self.request(data)
return response and response['text'] or ''
def decode(self, filename, codetype, timeout):
cid = self.upload(filename, codetype, timeout)
if (cid > 0):
for i in range(0, timeout):
result = self.result(cid)
if (result != ''):
return cid, result
else:
time.sleep(1)
return -3003, ''
else:
return cid, ''
def report(self, cid):
data = {'method': 'report', 'username': self.username, 'password': self.password, 'appid': self.appid,
'appkey': self.appkey, 'cid': str(cid), 'flag': '0'}
response = self.request(data)
if (response):
return response['ret']
else:
return -9001
def post_url(self, url, fields, files=[]):
for key in files:
files[key] = open(files[key], 'rb');
res = requests.post(url, files=files, data=fields)
return res.text
######################################################################
# 用户名
username = 'username'
# 密码
password = 'password'
# 软件ID,开发者分成必要参数。登录开发者后台【我的软件】获得!
appid = 5149
# 软件密钥,开发者分成必要参数。登录开发者后台【我的软件】获得!
appkey = '9405f228b0dc52df62e1353d7bc33a2a'
# 图片文件
filename = 'weibo.jpg'
# 验证码类型,# 例:1004表示4位字母数字,不同类型收费不同。请准确填写,否则影响识别率。在此查询所有类型 http://www.yundama.com/price.html
codetype = 5000
# 超时时间,秒
timeout = 60
def get_verifycode():
# 检查
if (username == 'username'):
print('请设置好相关参数再测试')
else:
# 初始化
yundama = YDMHttp(username, password, appid, appkey)
# 登陆云打码
uid = yundama.login()
print('uid: %s' % uid)
# 查询余额
balance = yundama.balance()
print('balance: %s' % balance)
# 开始识别,图片路径,验证码类型ID,超时时间(秒),识别结果
cid, result = yundama.decode(filename, codetype, timeout)
print('cid: %s, result: %s' % (cid, result))
return result
if __name__ == '__main__':
get_verifycode()
注意将图片文件 filename 配置成 'weibo.jpg'

- Selenium 模拟鼠标下拉
因为有些页面是通过 Ajax 动态加载的,所以通过鼠标下拉才能够获取内容,Selenium 是可以直接执行 JavaScript 代码的,而 JavaScript 代码就可以控制浏览器滚动页面(也就是鼠标下拉)
只需要一行代碼就可以实现鼠标下拉
browser.execute_script('window.scrollTo(0,document.body.scrollHeight); var lenOfPage=document.body.scrollHeight; return lenOfPage;')
from selenium import webdriver
from scrapy.selector import Selector
browser = webdriver.Chrome(executable_path='C:\Python\Lib\chromedriver.exe')
# 测试加载动态 HTML 页面
# browser.get('https://detail.tmall.com/item.htm?spm=a222t.11127371.9014454352.1.66ae289dWyk5nx&id=555850828895&sku_properties=10004:827902415;5919063:6536025')
# # print(browser.page_source)
#
# # 通过 Scrapy 的 Selector 提取商品价格
# selector = Selector(text=browser.page_source)
# price = selector.xpath('//span[@class="tm-price"]/text()').extract_first()
# print(price)
#
# # 通过 Selenium 提取商品价格
# price = browser.find_element_by_class_name('tm-price').text
# print(price)
# 测试鼠标下拉功能
import time
browser.get('https://www.oschina.net/blog')
for i in range(3):
# 执行 JavaScript 代码
browser.execute_script('window.scrollTo(0,document.body.scrollHeight); var lenOfPage=document.body.scrollHeight; return lenOfPage;')
time.sleep(1)
browser.quit()
chromedriver不加载图片、phantomjs获取动态网页
- chromedriver不加载图片
from selenium import webdriver
# 设置 chromedriver 不加载图片
chrome_options = webdriver.ChromeOptions()
prefs = {'profile.managed_default_content_settings.images': 2}
chrome_options.add_experimental_option('prefs', prefs)
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.get('https://www.taobao.com/')
# browser.quit()
运行代码可以发现所有图片均未加载

- phantomjs获取动态网页
phantomjs 是一个无界面浏览器,所以从某种层面上会比 Chrome 或者 Firefox 等浏览器效率更高,但是有个很大的问题,在多进程的情况下,phantomjs 的性能会下降很严重
phantomjs 的一大好处就是在 linux 这种无界面的服务器上,没有可视化的环境,phantomjs 优势就体现出来了。但是在 windows 下更多的是要用 Chrome,因为 Chrome 的性能高于 phantomjs,并且在多进程的情况下 phantomjs 的渲染有可能会出问题,而且是极其不稳定的
下载地址:http://phantomjs.org/download.html
phantomjs 使用方法同 Chrom 是一样的
from selenium import webdriver
# phantomjs 无界面浏览器的使用,多进程情况下 phantomjs 性能会下降很严重
browser = webdriver.PhantomJS(executable_path=r'C:\Python\Lib\phantomjs-2.1.1-windows\bin\phantomjs.exe')
browser.get('https://item.taobao.com/item.htm?id=530828112213&ali_trackid=2:mm_26632614_0_0:1529804318_358_919575055&spm=a21bo.7925826.192013.1.12e24c0dmW0lJq')
print(browser.page_source)
# phantomjs 是看不见的浏览器,所以记得将其退出
browser.quit()
运行 phantomjs 同样可以搜索到淘宝商品价格

事实上,运行程序在打印结果的第一行会有一个警告,新版本的 selenium(我测试使用的版本为selenium=3.12.0)已经不建议使用 PhantomJS,在未来的某一个版本一定会彻底弃用 PhantomJS

selenium集成到scrapy中
可以通过自定义中间件,来将 Selenium 集成到 Scrapy 当中
# ArticleSpider/middlewares.py
from selenium import webdriver
from scrapy.http import HtmlResponse
class JSPageMiddleware(object):
"""
通过 Selenium 操作 Chrome 请求动态加载的网页
"""
def process_request(self, request, spider):
# 实际项目中通常并不是每一个页面都必须通过 Chrome 来请求
# 这样效率也会太低,通常只是某些页面需要用 Chrome 来请求
# 这里以 jobbole 爬虫为例,因为 ArticleSpider 项目中有多
# 个 spider,判断如果是 jobbole spider,就用 Chrome 来处
# 理,当然 jobbole spider 实际上并不需要 Chrome 来处理,
# 这里只是以这个为例进行测试
# 在有些情况下,也许我们只会处理 jobbole spider 中的某一
# 类 URL,如果这样的话,也可以通过这里接收到的参数 request
# 利用 re 等方式判断其 request 的 URL 是否符合某一类规则
# 将符合规则的 URL 通过 Chrome 来处理
if spider.name == 'jobbole':
browser = webdriver.Chrome()
browser.get(request.url)
import time
time.sleep(3)
print(f'访问:{request.url}')
# 因为这里已经通过 Chrome 请求了网页并下载完成,所以也就
# 没必要再次发送请求到 Scrapy 下载器了,况且实际情况中动
# 态加载的页面 Scrapy 也无法下载,解决办法就是这里下载完
# 成后,直接 return 一个 HtmlResponse 就可以了,一旦遇到
# 这个 HtmlResponse,Scrapy 就不会再向下载器 downloader
# 发送,而是直接返回 response 给我们的 spider
# 查看源码默认 _DEFAULT_ENCODING = 'ascii',所以要指明 encoding='utf8'
return HtmlResponse(url=browser.current_url, body=browser.page_source, request=request, encoding='utf8')
settings.py 中配置中间件
DOWNLOADER_MIDDLEWARES = {
...
'ArticleSpider.middlewares.JSPageMiddleware': 10,
}
这样就简单的实现了将 Selenium 集成到 Scrapy 中,但这也仅仅是实现了,还有很多问题未处理
这样写最大的弊端就是每次发起一个请求,去请求一个页面,都会重新打开一个 Chrome,这样做效率太低
修改以上代码,将 browser 的初始化放到
__init__方法中,实现不是每次请求页面都重新打开一个 Chrome
# ArticleSpider/middlewares.py
from selenium import webdriver
from scrapy.http import HtmlResponse
class JSPageMiddleware(object):
"""
通过 Selenium 操作 Chrome 请求动态加载的网页
"""
def __init__(self):
self.browser = webdriver.Chrome()
super().__init__()
def process_request(self, request, spider):
if spider.name == 'jobbole':
self.browser.get(request.url)
import time
time.sleep(3)
print(f'访问:{request.url}')
return HtmlResponse(url=self.browser.current_url, body=self.browser.page_source, request=request, encoding='utf8')
但是这样做还是有一个隐患,就是每次爬虫如果运行完成自动关闭后,是不会自动关闭浏览器的
Scrapy 的中间件中常用的两个方法
process_request、process_response分别可以处理 Request 和 Response,但是不能在中间件中调用 spider 的 close 方法,所以就不能在中间件中处理关闭浏览器的操作
事实上,实际情况中并不是每个页面都需要用 Chrome 请求,所以,既然不是每个 spider 都需要 Chrome,那么就可以考虑将 Chrome 放到每一个 spider 里面,哪个 spider 需要用到 Chrome 就在哪个 spider 中放入 Chrome,这样做当启动多个 spider 的时候,就会启动对应多个 Chrome,互不影响,这样对爬虫的并发也是有好处的。而在 spider 中关闭 Chrome 就要相对简单很多
在 jobbole.py 中 jobbole spider 的
__init__方法中初始化 browser
# ArticleSpider/spiders/jobbole.py
from selenium import webdriver
...
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['jobbole.com']
start_urls = ['http://python.jobbole.com/all-posts/'] # http://blog.jobbole.com/114041/
def __init__(self):
self.browser = webdriver.Chrome()
super().__init__()
def parse(self, response):
"""
1. 提取文章列表页中所有文章详情页链接,并交给 parse_detail 方法进行解析
2. 提取下一页链接,并交给 Scrapy 进行下载
Args:
response: 响应信息
Yields:
1. 文章详情页链接,交给 parse_detail 解析
2. 下一页链接,交给 Scrapy 下载
"""
post_nodes = response.xpath('//div[@id="archive"]')
for post_node in post_nodes:
post_url = post_node.xpath('.//div[@class="post-meta"]//a[@class="archive-title"]/@href').extract_first('')
front_img_url = post_node.xpath('.//div[@class="post-thumb"]//img/@src').extract_first('')
yield scrapy.Request(url=urljoin(response.url, post_url), callback=self.parse_detail,
meta={'front_img_url': front_img_url})
next_url = response.xpath('//a[@class="next page-numbers"]/@href').extract_first()
if next_url:
yield scrapy.Request(url=next_url, callback=self.parse)
...
# ArticleSpider/middlewares.py
from scrapy.http import HtmlResponse
class JSPageMiddleware(object):
"""
通过 Selenium 操作 Chrome 请求动态加载的网页
"""
def process_request(self, request, spider):
if spider.name == 'jobbole':
spider.browser.get(request.url)
import time
time.sleep(3)
print(f'访问:{request.url}')
return HtmlResponse(url=spider.browser.current_url, body=spider.browser.page_source, request=request, encoding='utf8')
下面就是做进一步处理,在 JobboleSpider 中想办法在爬虫结束运行后自动关闭 Chrome
这里用到了 Scrapy 中信号的概念,Scrapy 的信号同 Django 用法是一样的
# ArticleSpider/spiders/jobbole.py
...
from selenium import webdriver
from scrapy.xlib.pydispatch import dispatcher
from scrapy import signals
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['jobbole.com']
start_urls = ['http://python.jobbole.com/all-posts/'] # http://blog.jobbole.com/114041/
def __init__(self):
self.browser = webdriver.Chrome()
super().__init__()
# 利用 Scrapy 的信号来关闭 Chrome
# 当接收到 spider_closed 信号的时候,关闭 Chrome
dispatcher.connect(receiver=self.spider_closed, signal=signals.spider_closed)
def spider_closed(self, spider):
"""
当 spider 退出的时候关闭 Chrome
"""
print('spider closed')
self.browser.quit()
def parse(self, response):
"""
1. 提取文章列表页中所有文章详情页链接,并交给 parse_detail 方法进行解析
2. 提取下一页链接,并交给 Scrapy 进行下载
Args:
response: 响应信息
Yields:
1. 文章详情页链接,交给 parse_detail 解析
2. 下一页链接,交给 Scrapy 下载
"""
post_nodes = response.xpath('//div[@id="archive"]')
for post_node in post_nodes:
post_url = post_node.xpath('.//div[@class="post-meta"]//a[@class="archive-title"]/@href').extract_first('')
front_img_url = post_node.xpath('.//div[@class="post-thumb"]//img/@src').extract_first('')
yield scrapy.Request(url=urljoin(response.url, post_url), callback=self.parse_detail,
meta={'front_img_url': front_img_url})
next_url = response.xpath('//a[@class="next page-numbers"]/@href').extract_first()
if next_url:
yield scrapy.Request(url=next_url, callback=self.parse)
...
这样就实现了 spider 关闭时自动关闭 Chrome,但是这样做对 Scrapy 爬虫的性能是有很大影响的,Scrapy 本身是一个异步框架,集成了 Chrome 后就变成了同步,如果想改成异步也是可以的,但是会非常麻烦,涉及到重写 downloader,所以必须熟悉 Twisted 的规范和 API 等
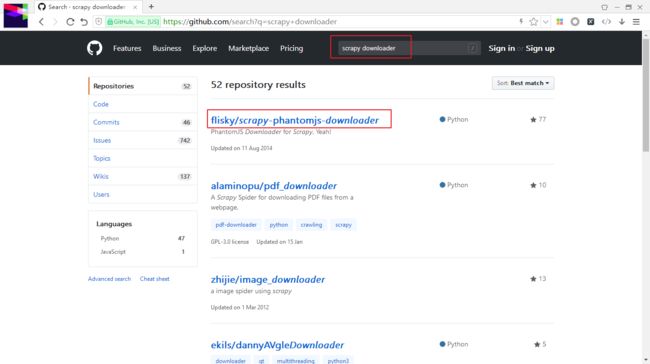
GitHub 上面也是有开源的,搜索 scrapy downloader 第一条结果就实现了重写 Scrapy 的 downloader
其余动态网页获取技术介绍-chrome无界面运行、scrapy-splash、selenium-grid, splinter
- chrome无界面运行
首先需要安装 pyvirtualdisplay
pip install pyvirtualdisplay
安装好后只需要增加 3 行代码即可无界面运行 Chrome,但是这种操作只有在 Linux 下是可以的,Windows 下代码不能运行,不过 Windows 下也没必要无界面运行 Chrome
# Chrome 无界面运行,只需要在初始化 Chrome 之前加上下面 3 行代码就可以了
from pyvirtualdisplay import Display
display = Display(visible=0, size=(800, 600)) # 参数 visible=0 就是不显示界面
display.start()
browser = webdriver.Chrome()
browser.get('https://www.taobao.com/')
# browser.quit()
事实上,综合来看 chromedriver 是最稳定的,phantomjs 是有几率被识别为爬虫的
- scrapy-splash
Scrapy 本身也提供了一个下载动态网页的解决方案
GitHub 地址:https://github.com/scrapy-plugins/scrapy-splash
它实际上是自己运行了一个 server,通过 http 的请求方式去执行 js,所以性能相对于 Chrome 等会相对高一些,轻量级的,但是稳定性还是 Chrome 最高。scrapy-splash 还有一个好处是支持分布式,因为运行在一个 server 上,所以可以从很多地方发送请求
- selenium-grid
selenium-grid 也是支持分布式的,与 scrapy-splash 方案类似,也是启动一个服务,通过 API 的方式向它发送请求
- splinter
splinter 也是一种可以操控浏览器的解决方案,用法同 selenium 比较像,纯 Python 写的
GitHub 地址:https://github.com/cobrateam/splinter
scrapy的暂停与重启
Scrapy 的暂停与重启是非常方便的,比如爬虫爬取一半的时候需要将其停掉,后续继续爬取的时候以当前暂停的位置继续爬取
以 lagou spider 为例,因为暂停爬虫需要保存很多中间状态,比如暂停前没有做完的 Request、过滤器、spider 状态等,这些都需要保存下来,才能做到暂停后重启爬虫的时候可以从暂停前的状态继续爬取
为什么不用 PyCharm 调试爬虫,而是用命令行来调试?因为 Scrapy 爬虫结束所接收的信号是一个 Ctrl + C 的命令,如果用 PyCharm 启动爬虫,关闭爬虫的时候是不会给 Scrapy 发送 Ctrl + C 的命令的(Pycharm 实际上就是直接把进程 kill 掉),所以只能用 命令行来运行程序,在 Linux 下同样也可以用 Ctrl + C 命令。事实上 Linux 中的
kill -f main.py命令同样会发送给 Scrapy 一个 结束信号的,但是如果用kill -f -9 main.py命令就是强制杀死 main.py 这个进程,这样的话 Scrapy 还是无法接收到中断信号的,Windows 任务管理器中结束进程也是同样效果。
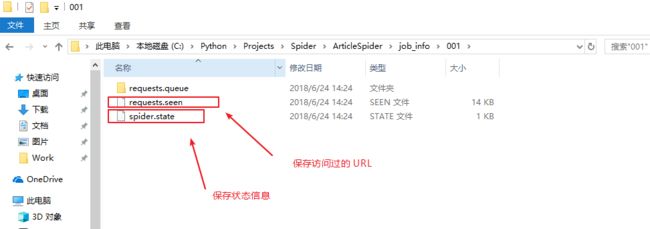
首先需要在 ArticleSpider 项目根目录创建一个 'job_info'目录,用于存放爬虫暂停所需存储的信息
然后通过
scrapy crawl lagou -s JOBDIR=job_info/001命令运行 lagou 爬虫
这里又增加了一个 001/ 目录,是因为项目中会有多个爬虫,每个爬虫都需要有自己的目录,为了区分,所以这里命名为 001/,并且如果暂停后,不想从暂停时的位置继续爬取,想要完全重新运行爬虫,就可以在新建一个目录如 002/ 这样,启动新爬虫只需要运行scrapy crawl lagou -s JOBDIR=job_info/002即可

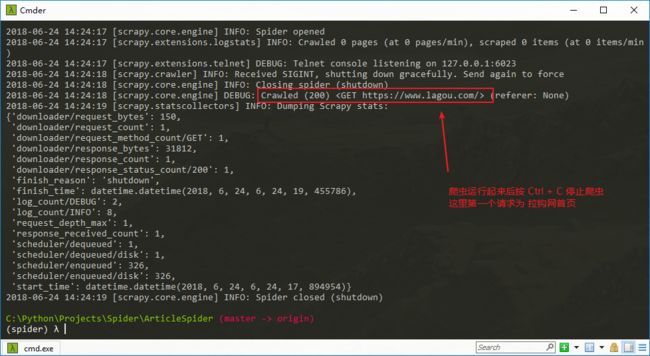
注意,在按 Ctrl + C 停止爬虫的时候,只能按一次 Ctrl + C ,千万不能多次按,按两次后就会强制退出爬虫,就相当于任务管理器中强制杀死进程,就不会给 Scrapy 发送信号了,也就无法做到保存中间状态
暂停爬虫以后,可以查看 001/ 目录多了几个文件
spider 如果全部跑完后,p0 这个文件会被 Scrapy 自动删除掉

想要重启爬虫,只需要重新执行同样的命令
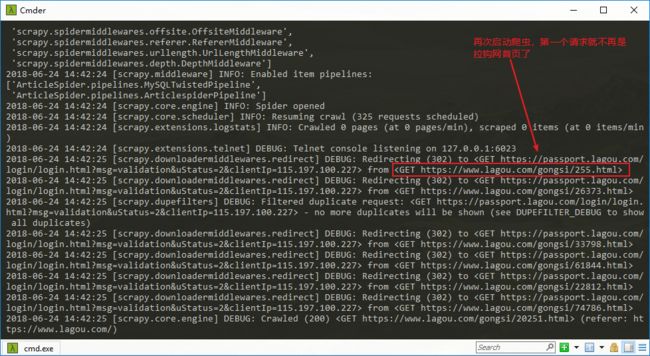
scrapy crawl lagou -s JOBDIR=job_info/001即可

再次启动 lagou 爬虫,第一个请求已经不再是 拉勾网首页了,不过这里爬虫被拉钩网禁止了,不要在意这些细节
想重新运行一个新的爬虫,运行
scrapy crawl lagou -s JOBDIR=job_info/002又会从拉勾网首页进行爬取


scrapy url去重原理
Scrapy 自带的去重类定义在 dupefilte.py 文件中

dupefilte.py 中的 RFPDupeFilter 类下的 request_seen 为主要去除方法

这个方法会在 Scrapy 源码中的 core/scheduler.py 中被调用
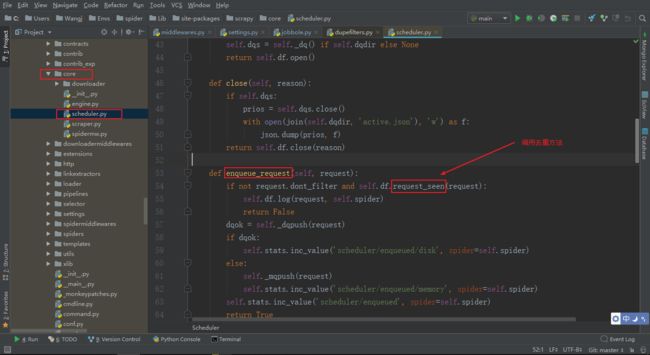
由此,可以分析出,如果自己要写一个去重器,就要实现 request_seen 方法
通过 Scrapy 发送 Request 的时候,如果指定参数 dont_filter=True,这样 Scrapy 就会关闭去重,不过滤 URL
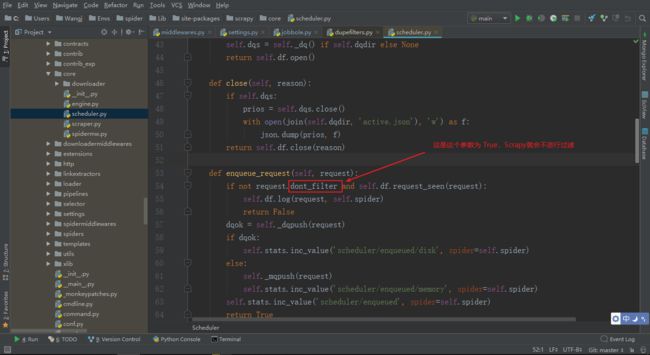

最后被调用的 request_fingerprint 是放在 scrapy/utlis/request.py 文件下的


Scrapy 是把这些 URL 都放到一个 set 里面的

scrapy telnet服务
telnet 就是让我们可以连接到一个远程的端口进行操作

事实上,Scrapy 默认启动了 Telnet 服务,监听 6023 端口

要想使用 Telnet,需要在 控制面板-程序-程序和功能-启用或关闭 Windows 功能 中开启 Telnet 服务和 Telnet 客户端,启动后就可以用 Telnet 了

启动 spider,在终端输入
telnet localhost 6023就可以连接使用了

启动爬虫
输入命令
telnet localhost 6023连接,出现>>>提示符表名连接成功
est() 命令查看当前 spider 运行状态
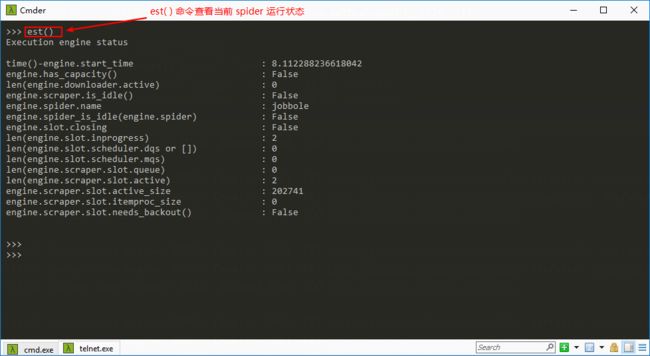
Scrapy telnet 中文文档地址:https://scrapy-chs.readthedocs.io/zh_CN/latest/topics/telnetconsole.html
连接上 Telnet 以后实际上就进入了一个 Python 终端,Scrapy 提供了很多变量

Telnet 终端命令行中可以通过
spider命令查看当前运行的 spider,通过
spider.settings['COOKIES_ENABLED']命令可以查看 settings.py 中配置的COOKIES_ENABLED的值
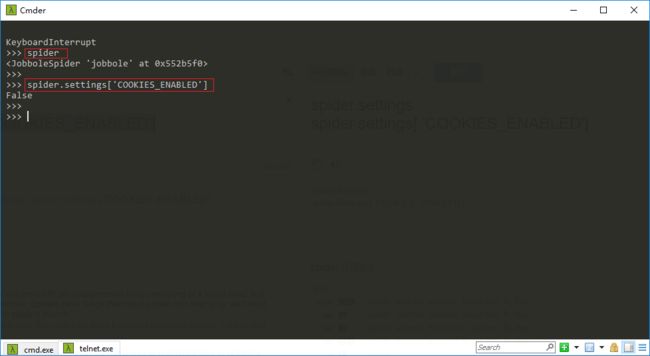
事实上,正是因为有了 Telnet,我们甚至可以在连接后的命令行终端写一些 Python 代码,来获取当前正在运行的 spider 的状态

scrapy的数据收集
文档地址:https://scrapy-chs.readthedocs.io/zh_CN/latest/topics/stats.html
数据收集也可以叫状态收集,比如 spider 运行的时候,我们希望用一个数值来计数我们到底发送了多少个 Request,这就是一个典型的数据收集(状态收集),再比如,在 parse 方法中到底共 yield 了多少个 item 出去
- 示例
收集伯乐在线所有 404 的 URL 以及 404 页面个数
# ArticleSpider/spiders/jobbole.py
...
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['jobbole.com']
start_urls = ['http://python.jobbole.com/fail_url/'] # http://blog.jobbole.com/114041/
# 收集伯乐在线所有 404 的 URL 以及 404 页面个数
# spider 默认情况下只会处理 200~300 之间的页面,
# 为了将 404 页面进行统计,就需要设置一个值,
# handle_httpstatus_list = [404]
# 这个变量的列表是可以添加多个值的,比如
# handle_httpstatus_list = [404, 301]
handle_httpstatus_list = [404]
def __init__(self):
# 用这个对象来保存所有 404 页面
# 为什么不用数据收集器来保存呢?
# 是因为数据收集器是数字类型,对于列表类型不太好操作
self.fail_urls = []
def parse(self, response):
"""
1. 提取文章列表页中所有文章详情页链接,并交给 parse_detail 方法进行解析
2. 提取下一页链接,并交给 Scrapy 进行下载
Args:
response: 响应信息
Yields:
1. 文章详情页链接,交给 parse_detail 解析
2. 下一页链接,交给 Scrapy 下载
"""
if response.status == 404:
# 如果页面为 404,则将此 URL 加入到 self.fail_urls 变量中
self.fail_urls.append(response.url)
# 只需要这样写 Scrapy 就会自动将 failed_url 值加一
self.crawler.stats.inc_value('failed_url')
post_nodes = response.xpath('//div[@id="archive"]')
for post_node in post_nodes:
post_url = post_node.xpath('.//div[@class="post-meta"]//a[@class="archive-title"]/@href').extract_first('')
front_img_url = post_node.xpath('.//div[@class="post-thumb"]//img/@src').extract_first('')
yield scrapy.Request(url=urljoin(response.url, post_url), callback=self.parse_detail,
meta={'front_img_url': front_img_url})
next_url = response.xpath('//a[@class="next page-numbers"]/@href').extract_first()
if next_url:
yield scrapy.Request(url=next_url, callback=self.parse)
...
可以 DeBug 调试代码


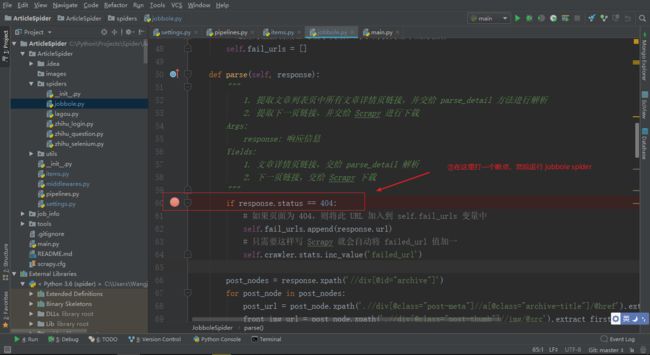
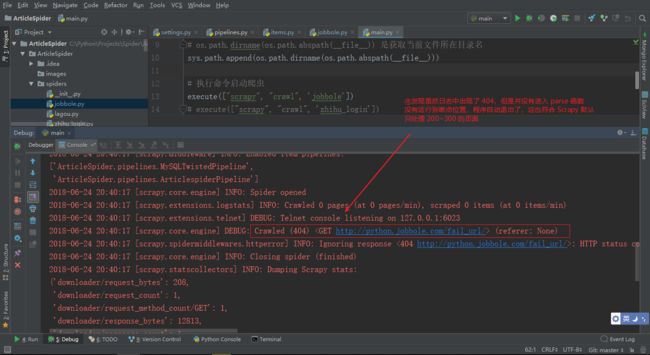



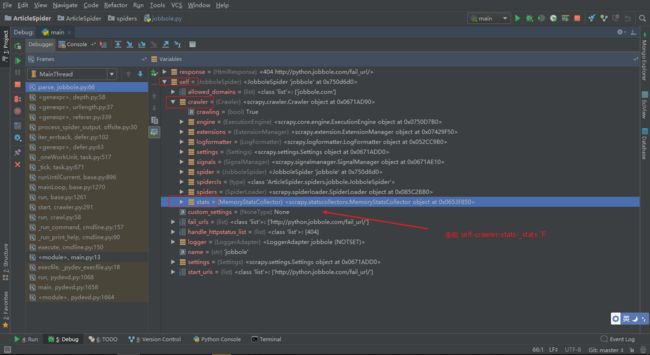
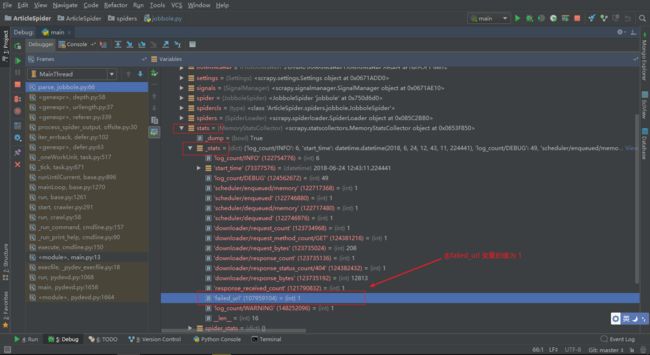
这样就实现了 Scrapy 的数据收集
scrapy信号详解
信号是一个非常重要的东西,它是我们的中间件、扩展的一个桥梁。Scrapy 的整个组件以及它的扩展都是基于信号来设计的,Scrapy 本身是内置了很多信号的
文档地址:https://scrapy-chs.readthedocs.io/zh_CN/latest/topics/signals.html
Scrapy使用信号来通知事情发生。您可以在您的Scrapy项目中捕捉一些信号(使用 extension)来完成额外的工作或添加额外的功能,扩展Scrapy。
我们能够看到的 middlewarer 实际上也是 extensions 中的一种,middlewarer 只是用来处理某些信号的一些扩展,我们可以这样理解,spider middleware 和 download middleware 实际上是一个简单的扩展
虽然信号提供了一些参数,不过处理函数不用接收所有的参数 - 信号分发机制(singal dispatching mechanism)仅仅提供处理器(handler)接受的参数。
延迟的信号处理器(Deferred signal handlers)
延迟是 Twisted 当中的一种概念,它实际上就是一个 Deferred 的对象,是一个延迟的对象,什么是延迟的对象呢?

我们可以在 deferred 对象里面加上 回调函数或者 errorback 函数,这个对象有这么一个特性,所以我们可以通过对返回的 deferred 对象里面加上回调或者错误处理函数
内置信号参考手册(Built-in signals reference)
- engine_started:当Scrapy引擎启动爬取时发送该信号,该信号可能会在信号
spider_opened之后被发送,取决于spider的启动方式- engine_stopped:当Scrapy引擎停止时发送该信号(例如,爬取结束)
- item_scraped:当item被爬取,并通过所有 Item Pipeline 后(没有被丢弃(dropped),发送该信号
- spider_closed:当某个spider被关闭时,该信号被发送
- spider_error:当spider的回调函数产生错误时(例如,抛出异常),该信号被发送,Scrapy 如果出现异常,并不会把 spider 停止掉,所以相对来说 Scrapy 是一个比较稳定的框架
... 更多信号请参考文档
信号使用示例
当产生 spider_closed 信号的时候调用 handle_spider_closed 方法
# ArticleSpider/spiders/jobbole.py
...
from scrapy.xlib.pydispatch import dispatcher
from scrapy import signals
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['jobbole.com']
start_urls = ['http://python.jobbole.com/fail_url/']
handle_httpstatus_list = [404]
def __init__(self):
# 用这个对象来保存所有 404 页面
# 为什么不用数据收集器来保存呢?
# 是因为数据收集器是数字类型,对于列表类型不太好操作
self.fail_urls = []
dispatcher.connect(self.handle_spider_closed, signals.spider_closed)
def handle_spider_closed(self, spider, reason):
# 文档中有提到会返回 spider、reason 这两个参数
# 当接收到 爬虫关闭的信号,将 self.fail_urls 拼接成字符串
# 放到 self.crawler.stats 当中,因为 self.crawler.stats 里
# 面是没有列表的,所以要组装成字符串
self.crawler.stats.set_value('failed_urls', ','.join(self.fail_urls))
def parse(self, response):
"""
1. 提取文章列表页中所有文章详情页链接,并交给 parse_detail 方法进行解析
2. 提取下一页链接,并交给 Scrapy 进行下载
Args:
response: 响应信息
Yields:
1. 文章详情页链接,交给 parse_detail 解析
2. 下一页链接,交给 Scrapy 下载
"""
if response.status == 404:
# 如果页面为 404,则将此 URL 加入到 self.fail_urls 变量中
self.fail_urls.append(response.url)
# 只需要这样写 Scrapy 就会自动将 failed_url 值加一
self.crawler.stats.inc_value('failed_url')
post_nodes = response.xpath('//div[@id="archive"]')
for post_node in post_nodes:
post_url = post_node.xpath('.//div[@class="post-meta"]//a[@class="archive-title"]/@href').extract_first('')
front_img_url = post_node.xpath('.//div[@class="post-thumb"]//img/@src').extract_first('')
yield scrapy.Request(url=urljoin(response.url, post_url), callback=self.parse_detail,
meta={'front_img_url': front_img_url})
next_url = response.xpath('//a[@class="next page-numbers"]/@href').extract_first()
if next_url:
yield scrapy.Request(url=next_url, callback=self.parse)
...
运行 jobbole spide,爬虫结束时会打印
failed_urls的值
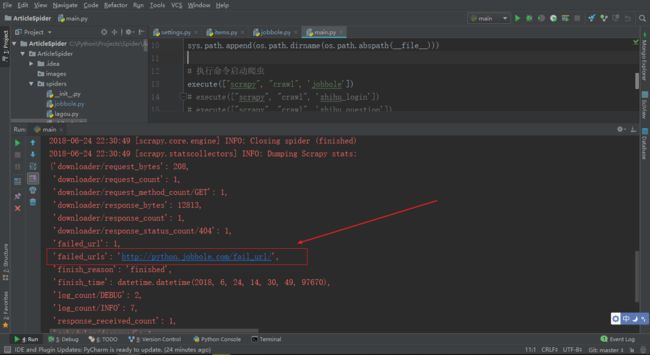
会被打印出来的原因是在 Scrapy 源码中,statscollectors.py 中也是做过信号绑定的,在 close_spider 时候会将 _stats 打印到控制台日志中
