前几天有幸在日知录社区里分享了自己对CephFS的理解与CephFS的测试分析,然后把内容整理如下,因为内容比较多,保持与日知录社区的文章一致,这里先贴出第一部分。
若对我的分享比较感兴趣,可以访问链接:日知录 - CephFS架构解读与测试分析
CephFS架构解读
cephFS简介
CephFS是Ceph提供的兼容Posix协议的文件系统 ,对比RBD和RGW,它是最晚满足Production ready的一个功能。CephFS的底层还是使用rados存储数据,用MDS管理filesystem的元数据。
在Jewel版本里,CephFS的基本功能已经ready,但是很多feature还是experimental的,并不建议在生成环境打开这些feature。
CephFS特性
-
可扩展性
CephFS的client端是直接读写OSDs的,所以OSDs的扩展性也体现在CephFS中
-
共享文件系统
CephFS是一个共享的文件系统,支持多个clients同时读写文件系统的一个file
-
高可用性
CephFS支持配置元数据服务器集群,也可以配置为Active-Standby的主从服务器,提高可用性
-
文件/目录Layout配置
CephFS支持配置任一文件/目录的Layout,文件/目录若不单独配置,默认继承父目录的Layout属性
-
POSIX ACLs支持
CephFS支持POSIX的ACLs,在CephFS支持的两个client中,kernel client默认支持,FUSE client需要修改配置来支持
-
Quotas支持
CephFS在后端没有实现Quota的功能,它的Quota是在CephFS FUSE client端实现的,而kernel client里还没有添加
CephFS架构
如下图所示:
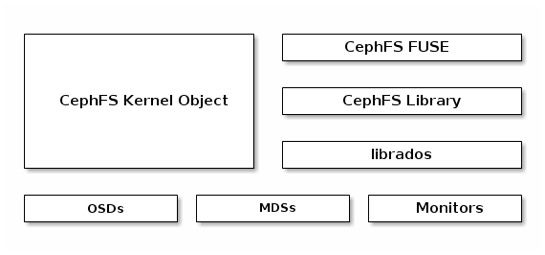
最底层还是基础的OSDs和Monitors,添加了MDSs,上层是支持客户端的CephFS kernel object,CephFS FUSE,CephFS Library等。
CephFS组件间通信

如上图所示,CephFS各个组件间通信如下:
-
Client <--> MDS
元数据操作和capalities
-
Client <--> OSD
数据IO
-
Client <--> Monitor
认证,集群map信息等
-
MDS <--> Monitor
心跳,集群map信息等
-
MDS <--> OSD
元数据IO
-
Monitor <--> OSD
心跳,集群map信息等
CephFS MDS组件
Ceph MDS设计的比较强大,作为一个能存储PB级数据的文件系统,它充分考虑了对元数据服务器的要求,设计了MDS集群。另外也引入了MDS的动态子树迁移,MDS的热度负载均衡。
但也正是这么超前的设计,使得MDS集群很难做到稳定,所以目前Jewel版本里默认还是单MDS实例,用户可配置主从MDS实例,提高可用性。 但在未来,MDS集群的这些属性都将稳定下来,为我们提供超强的元数据管理性能。
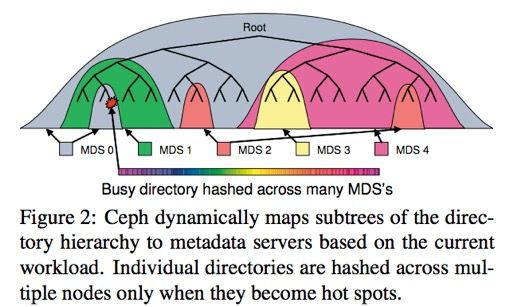
上图描述了CephFS的Dynamic subtree partition功能,它支持目录分片在多个MDS之间服务,并支持基于MDS负载均衡的动态迁移。
Client跟MDS通信后,会缓存对应的“目录-MDS”映射关系,这样Client任何时候都知道从哪个MDS上获取对应的元数据信息。
MDS自身的元数据有:
-
per-MDS journal
每个MDS都有一个对应的journal文件,支持大到几百兆字节的size,保证元数据的一致性和顺序提交的性能,它也是直接存储到OSD cluster里的
-
CephFS MetaData
MDS管理的CephFS的元数据也以文件格式存储到OSD cluster上,有些元数据信息会存到object的OMAP里
CephFS使用方式
与通常的网络文件系统一样,要访问cephfs,需要有对应的client端。cephfs现在支持两种client端:
- CephFS kernel client
- since 2.6.34
- CephFS FUSE
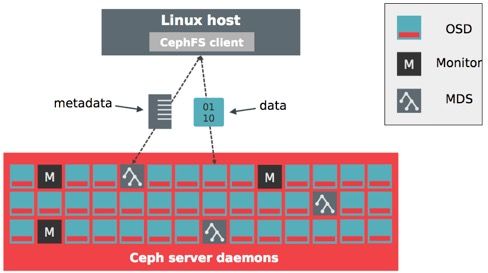
Client端访问CepFS的步骤如下:
- client端与MDS节点通讯,获取metadata信息(metadata也存在osd上)
- client直接写数据到OSD
Client端访问CephFS示例
- Client发送open file请求给MDS
- MDS返回file inode,file size,capability和stripe信息
- Client直接Read/Write数据到OSDs
- MDS管理file的capability
- Client发送close file请求给MDS,释放file的capability,更新file详细信息
这里cephfs并没有像其他分布式文件系统设计的那样,有分布式文件锁来保障数据一致性
它是通过文件的capability来保证的
CephFS相关命令
创建MDS Daemon
# ceph-deploy mds create <…>
创建CephFS Data Pool
# ceph osd pool create <…>
创建CephFS Metadata Pool
# ceph osd pool create <…>
创建CephFS
# ceph fs new <…>
查看CephFS
# ceph fs ls
name: tstfs, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
删除CephFS
# ceph fs rm --yes-i-really-mean-it
查看MDS状态
# ceph mds stat
e8: tstfs-1/1/1 up tstfs2-0/0/1 up {[tstfs:0]=mds-daemon-1=up:active}
- e8
- e表示epoch
- 8是epoch号
- tstfs-1/1/1 up
- tstfs是cephfs名字
- 三个1分别是 mds_map.in/mds_map.up/mds_map.max_mds
- up是cephfs状态
- {[tstfs:0]=mds-daemon-1=up:active}
- [tstfs:0]指tstfs的rank 0
- mds-daemon-1是服务tstfs的mds daemon name
- up:active是cephfs的状态为 up & active
mount使用CephFS
- CephFS kernel client
# mount -t ceph :6789 /mntdir
# umount /mntdir
- CephFS FUSE
安装ceph-fuse pkg
# yum install -y ceph-fuse
# ceph-fuse -m :6789 /mntdir
# fusermount -u /mntdir
centos7里没有fusermount命令,可以用umount替代
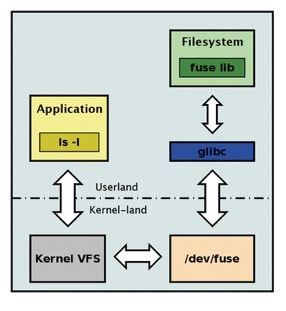
FUSE的IO Path较长,会先从用户态调用到内核态,再返回到用户态使用CephFS FUSE模块访问Ceph集群,如下图所示:
对比
- 性能:Kernel client > ceph-fuse
- Quota支持:只有ceph-fuse(client-side quotas)
Quota不是在CephFS后端实现的,而是在client-side实现的。若某些应用中要求使用Quota,这时就必须考虑使用CephFS FUSE了
CephFS Layout
Cephfs支持配置目录、文件的layout和stripe,这些元数据信息保存在目录和文件的xattr中。
- 目录的layout xattrs为:ceph.dir.layout
- 文件的layout xattrs为:ceph.file.layout
CephFS支持的layout配置项有:
- pool
数据存储到指定pool - namespace
数据存储到指定namespace,比pool更细的粒度(rbd/rgw/cephfs都还不支持) - stripe_unit
条带大小,单位Byte - stripe_count
条带个数
默认文件/目录继承父目录的layout和striping
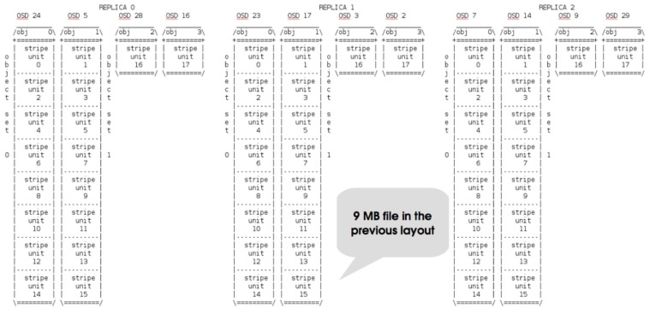
示例: 配置一个目录的Layout
# setfattr -n ceph.dir.layout -v "stripe_unit=524288 stripe_count=8 object_size=4194304 pool=cephfs_data2" /mnt/mike512K/
目录中一个9MB的文件的layout分布图为:
CephFS认证
有时候可能应用有这样的需求,不同的用户访问不同的CephFS目录,这时候就需要开启CephFS的认证。
不过首先需要开启的是Ceph集群的认证,然后就可以创建CephFS认证的client端了,指定client对mon,mds,osd的访问权限。
开启Ceph集群认证
配置ceph.conf
# vim /etc/ceph/ceph.conf
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
创建CephFS认证的client
# ceph auth get-or-create client.*client_name* \
mon 'allow r' \
mds 'allow r, allow rw path=/*specified_directory*' \
osd 'allow rw pool=’
示例与解释:
# ceph auth get-or-create client.tst1 mon ‘allow r’ mds ‘allow r, allow rw path=/tst1’ osd ‘allow rw pool=cephfs_data'
-
mon ‘allow r’
允许client从monitor读取数据;必须配置
-
mds ‘allow r, allow rw path=/tst1’
允许client从MDS读取数据,允许client对目录/tst1读写;
其中‘ allow r’必须配置,不然client不能从mds读取数据,mount会报permission error; -
osd ‘allow rw pool=cephfs_data’
允许client从osd pool=cephfs_data 上读写数据;
若不配置,client只能从mds上获取FS的元数据信息,没法查看各个文件的数据
对osd的权限也是必须配置的,不然client只能从mds上获取fs的元数据信息,没法查看文件的数据
检查ceph auth
# ceph auth get client.tst1
exported keyring for client.tst1
[client.tst]
key = AQCd+UBZxpi4EBAAUNyBDGdZbPgfd4oUb+u41A==
caps mds = allow r, allow rw path=/tst1"
caps mon = "allow r"
caps osd = "allow rw pool=cephfs_data"
mount测试
# mount -t ceph :6789:/tst1 /mnt -o name=tst1,secret=AQCd+UBZxpi4EBAAUNyBDGdZbPgfd4oUb+u41A==
认证机制不完善
CephFS的认证机制还不完善,上述client.tst1可以mount整个CephFS目录,能看到并读取整个CephFS的文件
# mount -t ceph :6789:/ /mnt -o name=tst1,secret=AQCd+UBZxpi4EBAAUNyBDGdZbPgfd4oUb+u41A==
另外没找到能支持readonly访问某一目录的方法。
只验证了cephfs kernel client,没试过ceph-fuse的认证
CephFS的 FSCK & Repair
FS的fsck和repair对一个文件系统是非常重要的,如果这个没搞定,一个文件系统是不会有人敢用的。
Ceph在Jewel版本里提供了Ready的CephFS的scrub和repair工具,它哪能处理大部分的元数据损坏。
但在使用中请记住两点:
- 修复命令==慎重执行==,需要专业人士操作
- 若命令支持,修复前请先备份元数据
cephfs journal工具
cephfs-journal-tool,用来修复损坏的MDS journal,它支持的命令有下面几类,详细的介绍看下help就明白了。
cephfs-journal-tool:
- inspect/import/export/reset
- header get/set
- event get/apply/recover_dentries/splice
cephfs online check/scrub
ceph tell mds. damage ls
ceph tell mds. damage rm
# scrub an inode and output results
ceph mds mds. scrub_path {force|recursive|repair [force|recursive|repair...]}
cephfs offline repair
cephfs-data-scan init [--force-init]
cephfs-data-scan scan_extents [--force-pool]
cephfs-data-scan scan_inodes [--force-pool] [--force-corrupt]
cephfs-data-scan scan_frags [--force-corrupt]
cephfs-data-scan tmap_upgrade