虚拟化(Virtualization)这种起源于上世纪60年代IBM大型机系统的技术在处理器性能大幅度提升的当下,再次迅速发展起来,并从最初的的裸机虚拟化(Type-I虚拟化)技术开始,演化出主机虚拟化(Type-II虚拟化)、混合虚拟化(Hybrid虚拟化)等更复杂的虚拟化模型,并在此基础山发展出了当下最热门的云计算技术,极大地降低了IT成本,增强了系统的安全性,可靠性和扩展性。
嵌入式系统则是虚拟化技术在嵌入式领域的应用。文中的Xvisor正是一款开源的采用裸机虚拟化技术的轻量级嵌入式Hypervisor,具有良好的代码架构和和可移植性,支持ARM和X86处理器的半虚拟化和基于硬件的全虚拟化技术。
文中围绕嵌入式Hypervisor的5个核心部分 - 客户机IO事件模拟、主机中断、 锁同步延迟、内存管理和内存占用,基于当下最流行的ARM处理器架构,进行了深入的阐述和对比。
本文翻译自Embedded Hypervisor Xvisor: A Comparative Analysis。译者在翻译时尽量逐词翻译,但是某些语句为了更清楚的表述根据译者的理解进行了转述。若有不妥,请参考原文。
- 摘要
- 1. 介绍
- 2. 虚拟化技术分类
- 2.1 Hypervisor设计
- 2.2 虚拟化模式
- 3. 嵌入式系统的开源Hypervisor
- 2.1 XEN
- 2.2 KVM
- 2.3 Xvisor
- 4. 客户机IO事件模拟
- 4.1 Xen ARM
- 4.2 KVM ARM
- 4.3 Xvisor ARM
- 5. 主机中断
- 5.1 Xen ARM
- 5.2 KVM ARM
- 5.3 Xvisor ARM
- 6. 锁同步延迟
- 7. 内存管理
- 7.1 Xen ARM
- 7.2 KVM ARM
- 7.3 Xvisor ARM
- 8. 内存占用比较
- 9. 基准测试程序
- 9.1 Dhrystone
- 9.2 Cachebench
- 9.3 Stream
- 9.4 Hackbench
- 10. 实验
- 11. 结论
- 参考文献
摘要
由于与减少费用、提高资源利用率和更高的性能直接相关,虚拟化技术已经在嵌入式系统中广泛流行。为了在嵌入式系统的严格时间约束和低内存占用的虚拟化环境中获得高效的性能,我们需要高效的Hypervisor(虚拟机管理器)。虽然现在已经有了一些开源的Hypervisor,例如Xen,Linux KVM和OKL4 Microvisor,这仍然是第一篇介绍开源嵌入式虚拟机管理器Xvisor(eXtensible Versatile hypervisor),并从对整个系统性能的影响上,与两个常用虚拟机管理器KVM和Xen进行对比的论文。实验证明,在ARM处理器架构上,Xvisor具有更低的CPU开销,更高的内存带宽,更低的锁同步延迟和虚拟定时器中断开销,并且能够全面提升嵌入式系统性能。
关键词:嵌入式系统; 虚拟化; Xen, Linux KVM; Xvisor;ARM;Hypervisor(虚拟机管理器);
1. 介绍
近年来,多核嵌入式系统需求的增长已经开始引领虚拟化技术在嵌入式系统中的研究。嵌入式系统通常具有资源有限,实时性约束,高性能要求,增长的应用程序栈需求(必须使用有限外设)等特点[参考文献1]。
虚拟化技术提供了在单核或多核处理器上以虚拟机(VM或客户机)方式运行多个操作系统的方法。每个客户机运行在一个或多个虚拟处理单元(vCPU)上。进而,一个客户机的所有vCPU(虚拟CPU)同另外一个客户机的vCPU完全隔离,但是共享同一套外设。
因此,虚拟化的应用提供了如下优势[参考文献2]:
- 过去运行在不同设备上的服务现在可以作为多个VM运行在同一个设备上;
- 在同一个设备上合并操作系统的实时特性和通用目的特性,即在不同的VM中执行实时程序和通用程序[参考文献3];
- 更好的容错性;
- 提供高可靠应用间的隔离性。
同样的,嵌入式虚拟化已经有在如下方面有力的证明了它的能力:
- 摩托罗拉Evoke,第一个虚拟化手机[参考文献4];
- 工业自动化,虚拟化允许添加额外的应用而不需要增加更多的处理单元[参考文献5];
- 汽车可以通过在若干个互相隔离的VM(虚拟机)上分别运行娱乐信息操作系统、AUTOSAR(汽车开放系统架构)操作系统和RTOS(实时操作系统),从而使得多个服务可以在同一套硬件上运行[参考文献6];
- 其他用户案例,例如零售和博彩行业。
基于下面的考虑,文中的分析性研究将新的嵌入式Hypervisor - Xvisor与2个现存的嵌入式开源Hypervisor - KVM/Xen进行对比:
本次研究基于ARM架构。这是由于最新的ARM处理器架构已经提供了硬件虚拟化扩展,并且ARM处理器在嵌入式系统中已经得到了广泛应用。另外,这3个Hypervisor共有的的大部分板级支持包(BSP)都使用了ARM架构处理器。
-
KVM和Xen被选中作为对比的虚拟机管理器,是基于如下原因:
- ARM架构支持[参考文献7,8];
- 允许我们没有任何限制的收集性能数据的开源特性[参考文献9];
- 与Xvisor支持同样的单板;
- 在嵌入式系统中得到了应用。
实验使用小型基准测试工具在客户机上进行测试。这些测试工具测试内存访问,Cache(高速缓存)访问,整形操作,任务处理等。这些操作上的性能增强能够提升系统的整体性能,不像是那些专注于测试某种特殊工作负荷(例如Web服务器,内核编译,图形渲染等)的宏基准测试工具。
-
实验仅使用通用目的操作系统(GPOS)Linux作为客户机。因为,这是唯一可被这3种Hypervisor支持的客户机操作系统。目前没有一个通用的实时操作系统可以同时为这3种ypervisor所支持。因此时间约束测试将通过如下因素的吞吐量测试来实施:
- Hypervisor的低内存和CPU开销;
- Hypervisor最小负荷情况下的客户机调度效率。
Xen,KVM和Xvisor实现的说明和限制的讨论如下所示:
- 本文第2章解释了虚拟化技术的分类;
- 本文第3章介绍了Xvisor并提供一个开源虚拟机管理器Xen和KVM的概况。影响到对比因素的主要组件的实现细节的解释在后续章节中会被显著说明。后续章节将包括一个基于ARM处理器架构的上述3种Hypervisor的对比分析[参考文献10]。
- 我们在第4讲述客户机IO模拟,而在第5,6,7,8章讲述主机中断处理,锁同步机制,内存管理和内存占用。
- 我们分析测试时用到的应用程序基准测试程序的简单说明放在第9章,测试结果放在随后的第10章,而结论则放在文末。
2. 虚拟化技术分类
基于如下两个特征[参考文献11],我们把虚拟化技术划分为5类:
- Hypervisor设计;
- 图1所示的虚拟化模式。
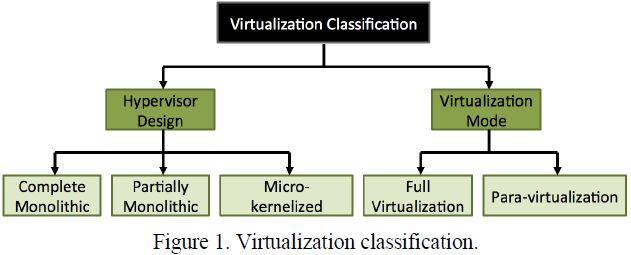
相应的,虚拟化技术分类在通过客户机获取的性能测量中扮演着重要角色。
2.1 Hypervisor设计
Hypervisor的角色是硬件和虚拟机之间的接口。这些Hypervisor的实现风格决定了他们作为虚拟化管理器的操作效率。给予他们的实现,所有Hypervisor都属于下面3种设计分类之一:
-
完全宏内核设计
完全宏内核Hypervisor使用一个单一的软件层来负责主机硬件访问,CPU虚拟化和客户机IO模拟。例如Xvisor和VMware ESXi Server[参考文献12]。
-
部分宏内核设计
部分宏内核Hypervisor通常是一个通用目的宏内核操作系统(例如Linux,FreeBSD,NETBSD,Windows等)的扩展。他们在操作系统内核支持主机硬件访问和CPU虚拟化,并通过用户空间软件支持客户机IO模拟。例如Linux KVM和VMware Workstation[参考文献13]。
-
微内核设计
微内核Hypervisor通常是在Hypervisor内核种提供基本的主机硬件访问和CPU虚拟化功能的轻量级微内核。它们依赖于一个管理VM来支持整个主机的硬件访问,客户机IO模拟和其他服务。这些微内核Hypervisor中的一些在一个分离的驱动VM上运行每一个主机设备驱动程序而不是在通用管理VM上运行。例如Xen,微软Hyper-V[参考文献14],OKL4 Microvisor[参考文献15]和INTEGRITY Multivisor[参考文献16]。
2.2 虚拟化模式
虚拟化模式决定了能够在Hypervisor上运行的客户机的类型[参考文献17,18]:
-
全虚拟化
通过提供系统虚拟机(例如模拟类似于真实硬件的整个系统),允许未经修改的客户机操作系统作为客户机运行。(译者注:该模式需要借助硬件的虚拟化支持,例如X86架构AMD-V/Intel VT,ARMv8和Power架构的虚拟化profile等。)
-
半虚拟化
通过提供Hypercall(虚拟机调用接口),允许修改过的的客户机操作系统作为客户机运行。这个模式要求客户机使用Hypercall来进行各种IO操作(例如,网络收发,块读写,终端读写等等)和在某些时候执行某些关键指令。这些Hypercall会触发一个trap(陷阱)中断以进入Hypervisor。这些trap中断基于Hypercall参数,使得Hypervisor为客户机提供期待的服务。
3. 嵌入式系统的开源Hypervisor
下面是两个开源虚拟机管理器Xen和KVM的一个简单介绍,用于在Hypervisor研究中跟Xvisor进行对照。
由于我们研究中对性能比较的关系,我们讲述了这些Hypervisor中已知的招致客户机运行并由此影响整个虚拟化嵌入式系统性能的系统组件的实现细节。这包括每个Hypervisor如何处理CPU虚拟化,客户机IO模拟和主机硬件访问。另外,每个Hypervisor的某些主要优势也会被提及。
2.1 XEN
如图2所示,Xen Hypervisor是一个支持全虚拟化和半虚拟化客户机的微内核Hypervisor。Xen Hypervisor内核是一个轻量级微内核,提供:
- CPU虚拟化;
- MMU虚拟化:
- 虚拟中断处理;
- 客户机间通讯[参考文献19]。
Domain(域)是Xen内核相应于虚拟机或客户机的概念。
Domain0(Dom0)是一个特殊类型的域,运行着一个Linux内核的修改版本。Dommain0必须运行在一个比任何其他VM或客户机更高的优先级上,并且具有对主机硬件的完全访问权限。Dom0的主要目的是利用Linux内核提供IO虚拟化和客户机管理服务。
DomainU(DomU)相应于运行着一个客户机操作系统的客户虚拟机。客户机的IO事件模拟和半虚拟化通过DomU和Dom0之间的通讯来实现。这一目的通过使用Xen事件通道来完成。半虚拟化客户机,相应于DomU PVM,使用Xen事件通道来访问Dom0半虚拟化IO服务。可是,全虚拟化客户机,相应于DomU HVM,使用运行在Dom0用户空间中的QEMU来模拟客户机IO事件。
所有用来管理客户机或域的用户接口都通过运行在Dom0用户控件的Xen工具栈来完成。没有Dom0,Xen不能提供DomU PVM或者DomU HVM。
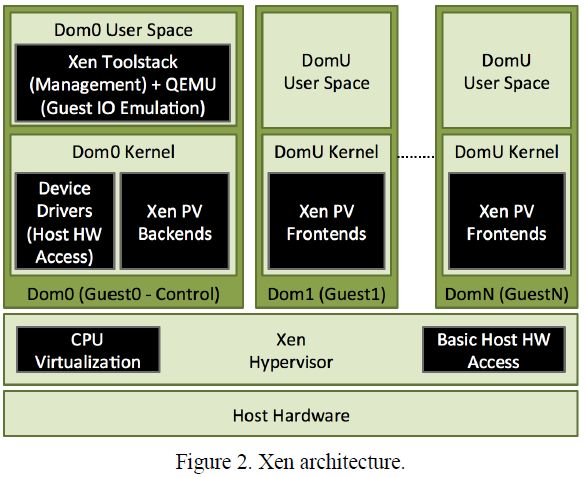
Xen最重要的优势是使用Linux内核作为Dom0,因为这能帮助Xen重用Linux内核现有的设备驱动和其他部分。可是,这个优势带来了后面章节将会提到的额外代价。也就是说,作为Dom0运行的Linux内核比直接运行在真实硬件上(没有Xen)稍微慢了一点。这是因为,Dom0只是Xen的另一个域,有它自己的嵌套页表,并且可能被Xen调度器调度出去。
2.2 KVM
KVM(基于内核的虚拟机)是一个支持全虚拟化和半虚拟化技术的部分宏内核Hypervisor。KVM主要提供全虚拟化客户机,并以可选的VirtIO设备[参考文献20]的形式提供半虚拟化支持。
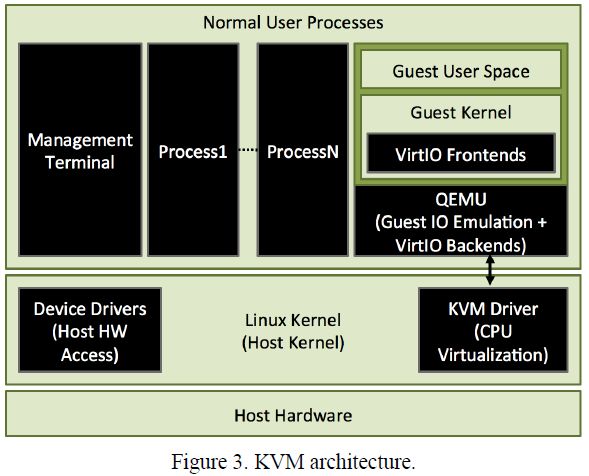
KVM扩展Linux内核的执行模式以允许Linux作为一个Hypervisor来工作。除了已有的2种执行模式(内核模式和用户模式),客户机模式被作为一种新的模式添加到Linux内核中。这种方式允许客户机操作系统与主机操作系统运行在相同的执行模式下(除了某些特殊指令和寄存器访问),并且IO访问将陷入到主机Linux内核。主机Linux内核将把一个虚拟机视作一个QEMU进程。KVM只能在主机内核上虚拟化CPU,并且依赖于运行在用户控件的QEMU来处理客户机IO事件的模拟和半虚拟化。
如图2所示,KVM包含2个主要组件:
- 内核空间字符设备驱动,通过一个字符设备文件/dev/kvm提供CPU虚拟化服务和内存虚拟化服务;
- 提供客户机硬件模拟的用户空间模拟器(通常是QEMU)。
与这两个组件之间的服务请求通讯,例如虚拟机和vCPU的创建,通常通过/dev/kvm设备文件的IOCTRL操作来处理。
KVM最重要的优势(类似于Xen)是使用Linux内核作为主机内核。这样有助于KVM重用Linux内核现有的设备驱动和其他部分。然而,由于KVM依赖于嵌套页表故障机制的客户机模式到主机模式的虚拟机切换,特殊指令陷阱(Trap),主机中断,客户机IO事件,和另一个从主机模式唤醒客户机执行的虚拟机切换,这个优势也导致了KVM整体性能本质上的降低。
2.3 Xvisor
图4中的Xvisor是一个支持全虚拟化和半虚拟化技术的完全宏内核Hypervisor。它的目的是提供一个仅需少量系统开销和很小内存占用的在嵌入式系统中使用的轻量级Hypervisor。Xvisor主要提供全虚拟化客户机,并以VirtIO设备[参考文献20]的形式提供半虚拟化支持。

Xvisor的所有核心组件,例如CPU虚拟化,客户机IO模拟,后端线程,半虚拟化服务,管理服务和设备驱动,都作为一个独立的软件层运行,不需要任何必备的工具或者二进制文件。
客户机操作系统运行在Xvisor上,具有更少的特权;而Xvisor的实现负责调用标准vCPU。此外,所有设备驱动和管理功能的后端处理运行在不具有最高优先级的孤儿vCPU(没有分配给某个客户机的vCPU)上。客户机配置信息以设备树(Device Tree)[参考文献21]的形式维护。这种方式通过使用设备树脚本(DTS),使得客户机硬件信息的维护更加容易。换句话说,为嵌入式系统定制一个虚拟机时不需要修改代码。
Xvisor最重要的优势是运行在提供所有虚拟化相关服务的最高特权等级上的单一软件层。不像KVM,Xvisor的上下文切换非常轻量级(参见第5章),因此嵌套页表、特殊指令陷阱、主机中断和客户机IO事件等的处理也非常快速。进而,所有设备驱动都作为Xvisor的一部分直接运行,具有完全的特权并且没有嵌套页表,以确保不会出现性能退化。另外,Xvisor的vCPU调度器是基于单CPU的,不处理多核系统的负载均衡。在Xvisor中,多核系统的负载均衡器是一个分离的部分,独立于vCPU调度器(不像KVM和XEN)。在Xvisor中,vCPU调度器和负载均衡器都是可扩展的。
Xvisor唯一的限制是缺少Linux那样丰富的单板和设备驱动。为了处理这个限制,Xvisor提供了Linux兼容层头文件以方便从Linux内核移植设备驱动框架和设备驱动。尽管不能完全解决问题,移植成本也可以大幅度减少。
4. 客户机IO事件模拟
嵌入式系统需要作为虚拟机(VM)或客户机运行传统软件。传统嵌入式软件可能期待需要Hypervisor模拟的特殊硬件。这就是为什么Hypervisor必须尽可能减小客户机IO事件模拟的开销。后面的小章节解释了前面提及的Hypervisor在ARM处理器架构上模拟的客户机IO事件的生命周期。注意,这非常重要。因为在这些Hypervisor中,客户机IO事件流在所有处理器架构包括ARM上都是相同的。
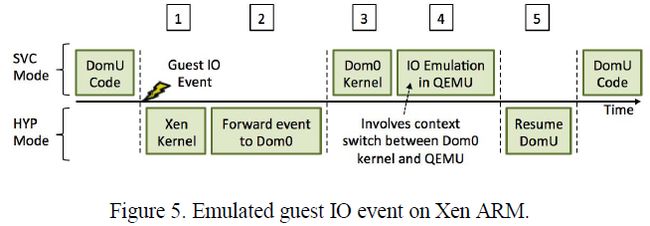
4.1 Xen ARM
图5展示了Xen ARM用于DomU HVM(全虚拟化客户机)的客户机IO事件模拟的生命周期。从标志1开始,一个客户机IO事件被触发,然后使用标志2和标志3所示的Xen事件通道转发到Dom0内核。随后,运行在Dom0用户空间的QEMU在标志4模拟客户机IO事件。最后在标志5,控制返回到DomU。
图中所示流程导致了一定数目的开销。首先,尽管已经进行过优化,基于域间通信的Xen事件通道还是具有非零开销。其次,Dom0内核到用户空间和相反方向的上下文切换增加了客户机IO事件模拟的开销。
4.2 KVM ARM
图6展示了客户机IO事件模拟在KVM ARM上的处理流程。图中场景开始在标志1,即一个客户机IO事件被触发的时刻。客户机IO事件引起一个VM-Exit事件,引起KVM从客户机模式切换到主机模式。然后,如标志2和3所示,客户机IO事件被运行在用户空间的QEMU处理。最后,在标志4处,VM-enter发生,引起KVM从主机模式切换到客户机模式。
处理开销主要由VM-exit和Vm-ente上下文切换引起,而这正是KVM众所周知的严重开销。

4.3 Xvisor ARM
不像其他Hypervisor,Xvisor ARM在客户机IO事件模拟上不会引发额外的调度或者上下文切换的开销。如图7所示,流程开始在标志1,一个客户机IO事件被Xvisor ARM捕获时。随后,事件在标志2处的不可睡眠的通用上下文中被处理以确保时间被处理,并具有预期的开销。
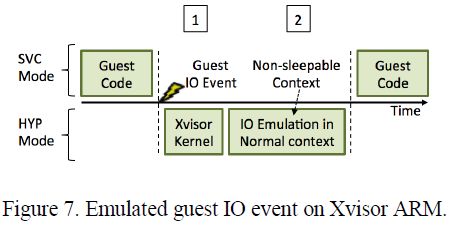
5. 主机中断
嵌入式系统在处理主机中断时,必须遵守严格的时间约束。在虚拟化环境中,Hypervisor在处理主机中断时可能会有额外的开销,转而影响主机IO性能。请重点注意,文中所述的Hypervisor的主机中断处理流程对所有处理器架构包括ARM都是相同的。
5.1 Xen ARM
在Xen中,主机设备驱动作为Dom0 Linux内核的一部分运行。因此所有主机中断都被转发到Dom0。如图8所示,流程开始在标志1,一个主机IRQ(中断请求)被触发,然后在标志2处被转发到Dom0。如图中标志3和4所示,所有主机中断由Dom0处理。如果一个主机中断在DomU运行时被触发,那么它将在Dom0被调度进来后才能得到处理,因此主机中断处理引发了调度开销。
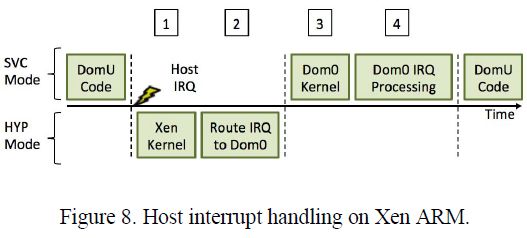
5.2 KVM ARM
图9所示为KVM ARM上客户机正在运行时的主机中断处理流程[参考文献22]。如图中标志1所示,每个主机中断触发一个VM-exit。一旦中断如图中标志2和3所示,被主机内核处理,KVM通过标志4处的VM-entry恢复客户机。当某个KVM客户机处于运行状态时,VM-exit和VM-entry增加了相当大的主机中断处理开销。进而,如果主机中断被转发到KVM客户机,那么调度开销也会存在。

5.3 Xvisor ARM
Xvisor的主机设备驱动通常作为Xvisor的一部分以最高权限运行。因此,图10中,处理主机中断时是不需要引发调度和上下文切换开销的。只有当主机中断被转发到一个当前没有运行的客户机时,才会引发调度开销。
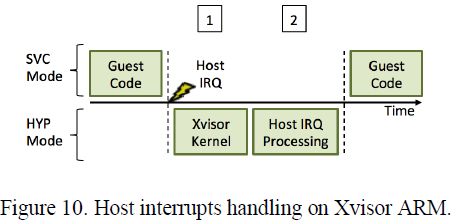
6. 锁同步延迟
在虚拟化环境中,锁同步延迟问题是[参考文献23]中提到的一个众所周知的问题。这个问题因如下2个调度器的存在而产生:
- Hypervisor调度器
- 客户机OS调度器
这里,两个调度器互相意识不到对方,导致客户机vCPU被Hypervisor随意抢占。我们给出了一个关于这种延迟和所有3个Hypervisor如何处理它们的一个简要介绍。
同一个客户机中vCPU之间锁同步的低效处理导致了图11和12中显示的两个不确定场景:vCPU抢占和vCPU堆积问题。两种问题都可能导致在获取同一个客户机的vCPU锁时增加等待时间。
当一个运行在持有锁的某主机CPU(pCPU0)上的vCPU(vCPU0)被抢占,而同时另一个运行在其他主机CPU(pCPU1)上的vCPU(vCPU1)正在等待这个锁,那么vCPU抢占问题就会发生。另外,发生在一个运行着多个vCPU的单主机CPU上的锁调度冲突问题也会导致vCPU堆积问题发生。也就是说,希望获取某个锁的vCPU(vCPU1)抢占了运行在同一个主机CPU上的vCPU(vCPU0),但是vCPU0正在持有这个锁。

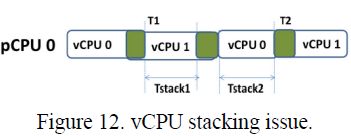
在ARM机构上,操作系统典型的使用WFE(等待事件)指令来等待请求一个锁,并使用SEV(发送事件)指令来释放一个锁。ARM架构允许WFE指令被Hypervisor捕获,但是SEV指令不能被捕获。为了解决vCPU堆积问题,所有3种Hypervisor(Xen ARM,KVM ARM和Xvisor ARM)都使用捕获WFE指令的方法使得vCPU让出时间片。ARM架构的vCPU抢占问题能够通过使用半虚拟化锁的方式来解决,但是需要对客户机操作系统进行源码级的修改。
7. 内存管理
嵌入式系统要求有效的内存处理。对于嵌入式Hypervisor来说,内存管理的开销需要慎重考虑。ARM架构提供2级翻译表(或者说嵌套页表),用于客户机内存虚拟化,即图13所示的2阶段MMU。客户机操作系统负责编程第1阶段页表,将客户机虚拟地址(GVA)翻译到间接物理地址(IPA)。ARM Hypervisor负责编程第2阶段页表来从将间接物理地址(IPA)翻译成实际物理地址(PA)。

TLB-miss(Translation Look-aside Buffers miss,即页表缓冲缺失)时必须检索翻译表。这个过程中使用的第2阶段页表的级数影响内存带宽和虚拟化系统的整体性能。比如最糟糕的情况下,N级第1阶段翻译表和M级第2阶段翻译表需要NxM次内存访问。对任何虚拟化系统上的客户机来说,TLB-miss损失都是非常昂贵的。为了减少2阶段MMU中的TLB-miss损失,ARM Hypervisor在第2阶段创建更大的页。
7.1 Xen ARM
Xen ARM为每个客户机或域(Dom0或DomU)创建一个独立的3级第2阶段翻译表。Xen ARM能创建4K字节,2M字节或1G字节的第2阶段翻译表项。Xen ARM也按需分配客户机内存,并试图基于IPA和PA对齐构造尽可能最大的第2阶段翻译表项。
7.2 KVM ARM
KVM用户空间工具(QEMU)预先分配作为客户机RAM使用的用户空间内存,并向KVM内核模块通知其位置。KVM内核模块为每个客户机vCPU创建一个独立的3级第2阶段翻译表。典型的,KVM ARM将创建4K字节大小的第2阶段翻译表项,但是也能够使用巨大化TLB优化模式创建2M字节大小的第2阶段翻译表项。
7.3 Xvisor ARM
Xvisor ARM在客户机创建时,预先分配连续的主机内存以做为客户机RAM。它为每个客户机创建一个独立的3级第2阶段翻译表。Xvisor ARM能创建4K字节,2M字节或1G字节的第2阶段翻译表项。另外,Xvisor ARM总是基于IPA和PA对齐创建尽可能最大的第2阶段翻译表项。最后,客户机RAM是扁平化和连续的(不像其它Hypervisor)。这有助于缓存预取访问,从而进一步提升客户机内存访问性能。
8. 内存占用比较
嵌入式系统要求小内存占用([参考文献[24])。下表I,II和III显示Cubieboard2([参考文献[25])上的安装需求和最小内存占用。因此后面问题答复如下:
- 需要满足什么条件才能使Xen ARM,KVM ARM和Xvisor ARM运行在系统上?
- Xen ARM,KVM ARM和Xvisor ARM需要消耗的的最小内存是多少?

上图中:
- a) Xen工具栈与其它依赖库单独安装。这个工具栈允许用户管理虚拟机创建、销毁和配置。它可以通过命令行终端和图形接口使用([参考文献[10])。
-
b) Xen保留大量内存,用于事件通道。

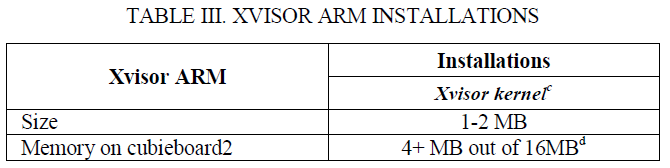
上图中:
- c) Xvisor内核在单个二进制文件中包含完整的虚拟化功能,并且随着更多新特性的增加从而增长到2~3M字节;
- d) Xvisor使用编译选项来限制自己的内存占用,ARM架构默认设置为16M字节。
9. 基准测试程序
我们实验中使用的基准测试程序专注于从CPU开销、内存带宽和锁同步机制方面比较Hypervisor。
9.1 Dhrystone
Dhrystone是一个用于测量处理器整形性能的简单基准测试([参考文献[26])。Dhrystone基准测试的每秒总迭代次数被称为每秒Dhrystones。进而,Dhrystone结果的另外一个表示是DMIPS(每秒百万条Dhrystone指令数),也就是每秒Dhrystones除以1757。DMIPS只不过是与VAX 11/780,,典型的1 MIPS机器([参考文献[27])进行比较的计算机系统的性能。
9.2 Cachebench
Cachebench来评估计算机系统内存体系的性能。它专注于把处理器内外的高速缓存的多个级别参数化。Cachebench进行不同缓冲区大小的测试:内存设置、内存复制、整数读取,整数写入和整数读取-修改-写入。对于我们的实验,我们将生成以兆字节每秒为单位的内存复制和整数读取-修改-写入测试的结果。
9.3 Stream
内存带宽已经被认为能够影响系统性能([参考文献[29])。STREAM是一个设计用来测量持续内存带宽(以兆字节每秒为单位)的简单复合基准测试程序。STREAM基准测试被明确的设计在任何系统的非常大的数据集合上工作,而不是可用的高速缓冲上。我们实验中使用的STREAM版本是v5.10,2000000数组大小(大约45.8M字节)
9.4 Hackbench
Hackbench通过确定调度给定数目任务花费的时间来测量系统调度器性能。Hackbench的主要工作是调度线程和进程。调度实体通过套接字或管道收发数据来通讯。运行测试程序时能够对数据大小和消息数目进行设置。
10. 实验
后面的实验目的在于评估近期提议的嵌入式Hypervisor - Xvisor相较KVM和Xen的效率。本文试图在Cubieboard2([参考文献[25])上的客户机Linux上运行4个基准测试程序。Cubieboard2是一块包含1GB RAM的ARM Cortex-A7双核1GHz单板。试验中使用了如下Hypervisor版本:
- KVM: 最新的Linux-3.16-rc3被用作主机KVM内核。客户机内核是Linux-3.16-rc3。
- Xen:2014年8月3日发布的最新的Xen-4.5-unstable内核被用作Hypervisor。Dom0内核和DomU均为Linux-3.16-rc3。
- Xvisor:2014年7月18日发布的最新的Xvisor-0.2.4+被用作Hypervisor。客户机内核是Linux-3.16-rc3。
实验结果通过两个测试向量获取。第一个运行在一个单核上,而另一个运行在一个双核上。测试系统(SUT,systems under test)如下:
- 没有任何Hypervisor的主机;
- Xvisor客户机;
- KVM客户机;
- HugeTLB模式KVM客户机;
- Xen客户机。
为了确保只有CPU开销,内存带宽和锁同步延迟被引入测试结果,两个测试向量都有一个具有2个vCPU的半虚拟化客户机。而且,所有Hypervisor都进行了如下优化:
- 没有来自于通用中断控制器的维护中断;
- Xen ARM超级页支持;
- WFE指令捕获-出让vCPU机制。
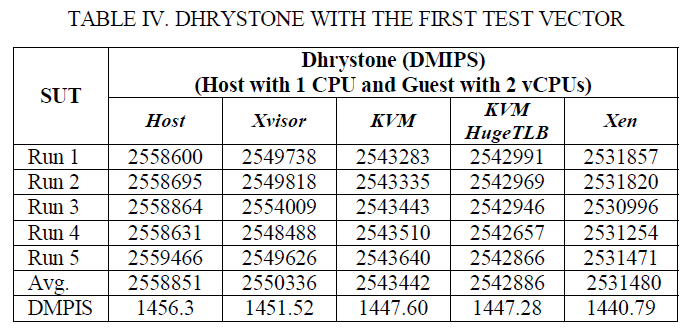
表IV和V显示以DMIPS为单位的Dhrystone结果。Xvisor客户机的DMIPS比KVM客户机高大约0.2%,比HugeTLB模式KVM客户机高0.19%,比Xen DomU高0.46%。Dhrystone基准测试很小,在运行时几乎可以放在高速缓存中,因此内存访问开销不会对其产生影响。尽管只有2个DMIPS的提升,这仍然提升了整个系统性能,因为1个DMIPS等于每秒1757次迭代。所以,使肌体上将是每秒数千次迭代(通常是几百万条机器指令)。



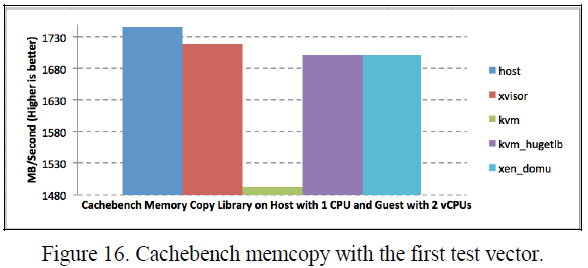
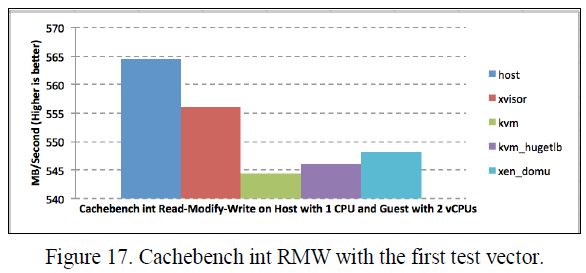
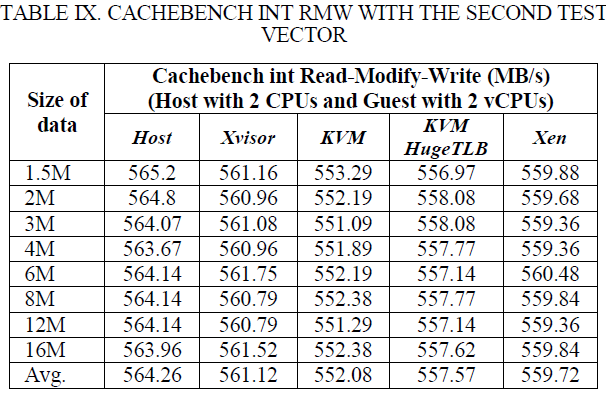
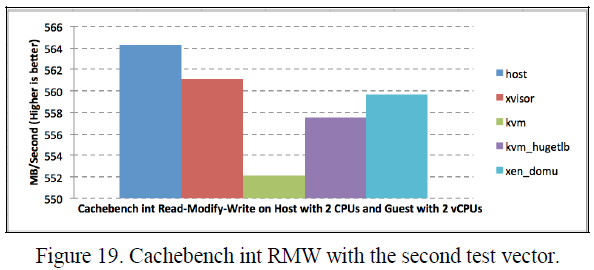
表VI, VII, VIII和IX显示内存复制和整数读取-修改-写入两种操作的Cachebench结果。Xvisor客户机的内存复制结果比KVM客户机高大约18%,比HugeTLB模式KVM客户机高1.2%,比Xen DomU高0.67%。Xvisor客户机的整数读取-修改-写入结果也比KVM客户机高大约1.14%,比HugeTLB模式KVM客户机高1.2%,比Xen DomU高1.64%。



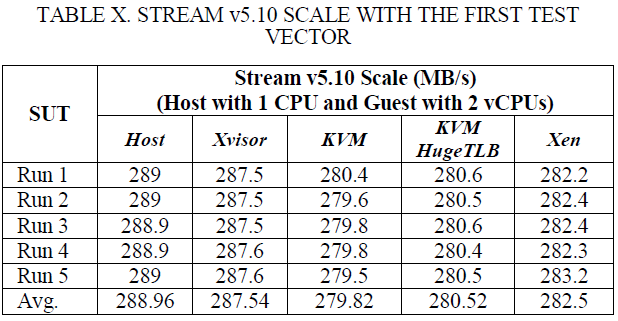
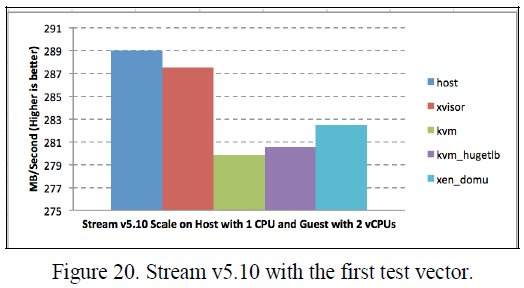
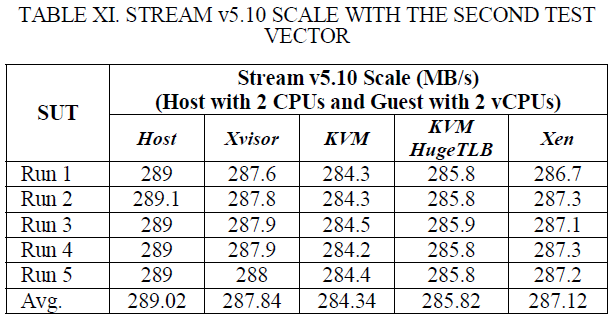
表X和XI显示Xvisor客户机的持续性内存带宽比KVM客户机高大约0.72%,比HugeTLB模式KVM客户机高1.57%,比Xen DomU高1.2%。

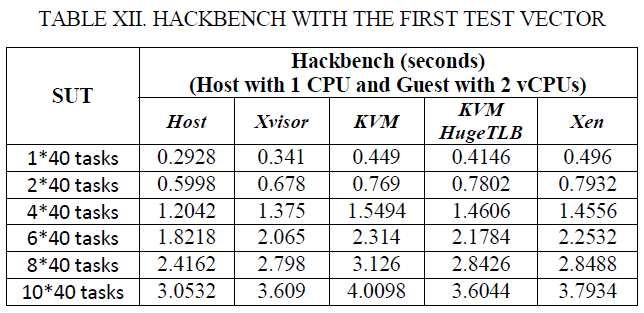
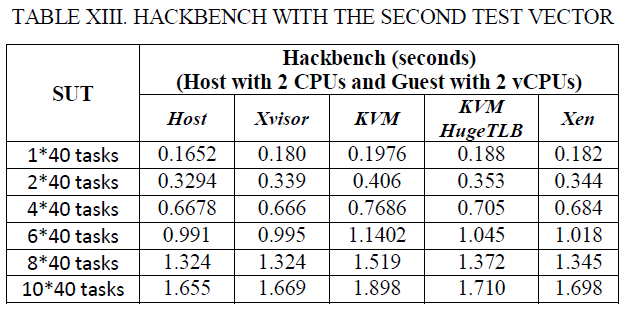
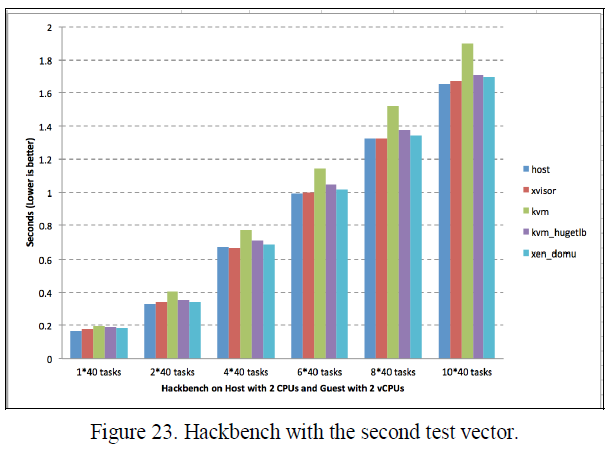
表XII和XIII中的Hackbench结果显示示Xvisor客户机的任务分发延迟比KVM客户机低大约12.5%,比HugeTLB模式KVM客户机低5.62%,比Xen DomU低6.39%。


11. 结论
这篇论文介绍了作为开源Hypervisor - Xen和KVM性能缺点解决方案的新嵌入式Hypervisor - Xvisor。Xvisor的实现优点体现在如下几个方面:
- 客户机IO模拟;
- 主机中断处理;
- 锁同步延迟;
- 内存占用;
- 内存管理。
而且,4种不同基础准测试的显示结果支撑了Xvisor的实现优势。
实验结果显示Dhrystone,Cachebench和Stream基准测试在Xvisor ARM客户机上具有更高的速率。这证明Xvisor ARM客户机具有相对于KVM ARM客户机和Xen ARM DomU更低的CPU开销和更高的内存带宽。进而,Hackbench在Xvisor ARM客户机上具有更少的执行时间。这说明Xvisor ARM客户机具有相对于KVM ARM客户机和Xen ARM DomU更低的锁同步延迟和虚拟定时器中断开销。这些结果意味着Xvisor ARM下的客户机相对于KVM ARM和Xen ARM更接近原生性能。最后, Xvisor ARM更小的内存占用允许它在嵌入式系统上更有效的利用有限的内存。
Xvisor允许额外的板级支持包(BSP)。更多的多核体验(不止是双核)也是可能的。而且,基于上述测量数据已经证明的性能提升,Xvisor将来在网络和存储虚拟化方面的实现也能具有更好的性能。
参考文献
- Motivation for running a Hypervisor on Embedded Systems
- R.Kaiser, "Complex embedded systems-A case for virtualization," in Intelligent solutions in Embedded Systems, 2009 Seventh Workshop on, pp. 135-140. IEEE, 2009.
- Heiser, Gernot. "The role of virtualization in embedded systems," in Proceedings of the 1st workshop on Isolation and integration in embedded systems, pp. 11-16. ACM, 2008.
- Heiser, Gernot. "The Motorola Evoke QA4-A Case Study in Mobile Virtualization." Open Kernel Labs (2009).
- “Case Study: The Use of Virtualization in Embedded Systems,” white paper,2013.
- G.Heiser, "Virtualizing embedded systems: why bother?," in Proceedings of the 48th Design Automation Conference, pp. 901-905. ACM, 2011.
- Dall, Christoffer, and Jason Nieh. "KVM/ARM: Experiences Building the Linux ARM Hypervisor." (2013).
- Rossier, Daniel. "EmbeddedXEN: A Revisited Architecture of the XEN hypervisor to support ARM-based embedded virtualization." White paper, Switzerland (2012).
- Soriga, Stefan Gabriel, and Mihai Barbulescu. "A comparison of the performance and scalability of Xen and KVM hypervisors." In Networking in Education and Research, 2013 RoEduNet International Conference 12th Edition, pp. 1-6. IEEE, 2013.
- [ARMv7-AR architecture reference manual](http://infocenter.arm.com/help/topic/com.arm.doc.ddi0406c/index.
html) - Xvisor open-source bare metal monolithic hypervisor
- The Architecture of VMware ESXi
- E. Bugnion, S. Devine, M. Rosenblum, J. Sugerman, and E. Y.Wang, “Bringing Virtualization to the x86 Architecture the Origiinal VMware Workstation,” ACM Transactions on Computer Systems, 30(4):12:1-12:51, Nov 2012.
- OKL4 Microvisor
- H. Fayyad-Kazan, L. Perneel and M. Timerman, “Benchmarking the Performance of Microsoft Hyper-V server, VMware ESXi, and Xen Hypervisors”, Journal of Emerging Trends in Computing and Information Sciences, Vol. 4, No. 12, Dec 2013.
- INTEGRITY Multivisor
- Full Virtualization
- Paravirtualization
- Xen Project Beginners Guide
- R. Russell. Virtio PCI Card Specification v0.9.5 DRAFT, May
- G.Likely, and J.Boyer, "A symphony of flavours: Using the device tree to describe embedded hardware," in Proceedings of the Linux Symposium, vol. 2, pp. 27-37. 2008.
- R.Ma, F.Zhou, E.Zhu, and H.GUAN, "Performance Tuning Towards a KVM-based Embedded Real-Time Virtualization System." Journal of Information Science and Engineering 29, no. 5 (2013): 1021-1035.
- X.Song, J.Shi, H.Chen, and B.Zang, "Schedule processes, not vcpus," in Proceedings of the 4th Asia-Pacific Workshop on Systems, p. 1. ACM, 2013.
- Memory Footprint
- Cubiboard
- RP.Weicker, "Dhrystone: a synthetic systems programming benchmark," Communications of the ACM 27, no. 10 (1984):1013-1030.
- Dhrystone
- PJ.Mucci, K.London, and J.Thurman. "The cachebench report."University of Tennessee, Knoxville, TN 19 (1998).
- Stream
- Hackbench Ubuntu Manuals