- MongoDB 常见查询语法与命令详解
夜影风
大数据(BigData)mongodb数据库
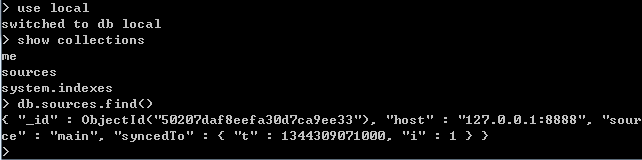
MongoDB作为文档型数据库,其查询语言基于BSON(二进制JSON)格式,与传统关系型数据库的SQL语法有较大差异。一、基本查询命令1.find():查询文档语法:db.collection.find(查询条件,投影)示例://查询users集合中所有文档db.users.find()//查询年龄大于25岁的用户,只返回姓名和年龄db.users.find({age:{$gt:25}},{na
- 【MongoDB】基础知识全面解析:从入门到核心概念
韩悸桉
数据库mongodb数据库
一、MongoDB是什么?MongoDB是一种开源文档型NoSQL数据库,以灵活的JSON格式(BSON)存储数据,无需固定表结构,适合处理半结构化和非结构化数据。与传统关系型数据库(如MySQL)相比,它具有以下特点:灵活的数据模型:文档结构可动态调整,适应业务需求变化。水平扩展性:支持分片集群,轻松应对海量数据存储。高性能读写:通过索引优化和内存缓存提升查询效率。二、核心概念与术语对比Mong
- 配置MySQL主从复制(一主一从)
cici15874
mysql
MySQL主从复制简介MySQL主从复制的目的是实现数据库冗余备份,将master数据库的数据定时同步到slave库中,一旦master数据库宕机,可以将Web应用数据库配置快速切换到slave数据库,确保Web应用有较高的可用性。MySQL主从同步是一个异步复制的过程,要实现复制,首先需要在master上开启bin-log日志功能,bin-log日志用于记录在master库执行的增删改更新操作的
- mongodb 基本概念
重生之我是一名程序员
mongodb
mongodb基本概念基于mongo:4.4.2databasedatabase数据库tablecollection数据库表/集合rowdocument数据记录行/文档columnfield数据字段/域indexindex索引tablejoins表连接,MongoDB不支持primarykeyprimarykey主键,MongoDB自动将_id字段设置为主键MongoDB数据类型数据类型描述Str
- Redis哨兵模式(Sentinel、1主2从3哨兵6台服务器配置实战、客户端调用、日志解析、主观下线、客观下线、仲裁、脑裂问题、哨兵长与从节点投票选举过程与原理)
小松聊PHP进阶
Redisredis服务器运维nosql后端架构数据库
哨兵模式官方文档:https://redis.io/docs/latest/operate/oss_and_stack/management/sentinel关联博客:Redis主从复制(下文能用到)极简概括:自动监控Redis主节点是否故障的一种方案,若主节点故障,则Redis会根据投票数自动将从库切换为主库(这个过程,叫仲裁)。解决问题:在主从复制的架构模式下,Redis主节点挂掉后,从节点无
- Studio 3T 2025.12 发布,新增功能简介
mongodb
Studio3T2025.12发布,新增功能简介Studio3T2025.12(macOS,Linux,Windows)-MongoDB的终极GUI、IDE和客户端TheUltimateGUI,IDEandclientforMongoDB请访问原文链接:https://sysin.org/blog/studio-3t/查看最新版。原创作品,转载请保留出处。作者主页:sysin.orgStudio3
- 【redis】介绍和安装
火龙谷
redisredis数据库缓存
介绍Redis是一款高性能的开源内存数据库,核心采用键值对(Key-Value)存储模型。其最大优势在于数据完全基于内存操作,读写速度远超传统磁盘数据库(内存访问速度可达磁盘的数千倍,固态硬盘仍有显著差距)。支持丰富的数据结构(字符串、哈希、列表、集合等),并非简单存储单一值。提供持久化机制(RDB快照/AOF日志),确保重启后数据可恢复。具备主从复制、哨兵高可用、集群分片等分布式能力,扩展性强。
- Java操作MongoDB数据库(连接,增删改查)
Java失业转安卓
数据库javamongodb
连接背景:需使用第三方类库:mongo-java-driver-3.4.2.jar不同的MongoDB需要使用的版本jar不同,根据需要可以自己在官网下载适合自己的版本gson-2.8.8.jar:某些方法需要传入MongoDB所需的Bson对象,可通过Gson,fastjson等方式创建,此处用的Gson1.连接MongoDB数据库:返回值:一个数据库连接对象参数:参数一:String类型的ip
- 计算机专业毕业设计选题指南(2025创新版)
程序员小天00
课程设计毕业设计小程序pythoneclipsejava
计算机专业毕业设计选题指南(2025创新版)一、选题方向全景图(按技术维度划分)智能服务系统开发技术架构:SpringBoot+Vue3+MySQL/MongoDB典型场景:●智慧校园:实验室预约系统、学术成果可视化平台●医疗健康:电子病历智能分析系统、慢性病管理助手●城市治理:垃圾分类智能识别系统、交通拥堵预测模型创新点:融合OCR识别/NLP技术,实现无感化服务跨平台应用开发技术选型:Unia
- 低代码平台架构设计
LINGYI_WEN
低代码前端开发语言
1.整体架构概述1.1技术栈选择前端:React+Redux/Vue+Vuex后端:Node.js+Express/SpringBoot数据库:MySQL/PostgreSQL/MongoDB云服务:AWS/Azure/GoogleCloud容器化:Docker+Kubernetes1.2模块划分前端模块:可视化编辑器:用于拖拽和配置组件预览器:实时预览页面效果发布器:将设计好的页面发布到生产环境
- docker 搭建mysql 连接不上_docker搭建MySQL主从集群
Grayce
docker搭建mysql连接不上
关于MySQL主从模式,如果我们直接在本机上搭建的话,是没法搭建的,只能借助于虚拟机,但有的时候我们又需要搭建一个主从集群,以便于进行一些功能性的测试。这个时候我们就可以尝试使用docker,借助于docker的容器化技术,我们只需要创建两个MySQL容器,并且占用主机的两个端口即可,对主机没有其他额外的影响。这种方式非常的轻量,而且也容易复制。本文则主要讲解如何通过docker来搭建MySQL集
- 通过docker快速搭建mysql主从集群(一主两从)
NazzzzMini
dockerdockermysql运维
通过docker快速搭建mysql主从集群(一主两从):首先请确保你的服务器已安装了docker⁄(⁄⁄•⁄ω⁄•⁄⁄)⁄,那么接下来,我们进入正题~1.镜像拉取#latest目前版本为8.0.13;dockerpullmysql:latest2.启动主库镜像dockerrun\--restart=always\-p3306:3306--namemysql\-v/opt/mysql/log:/va
- 04_MySQL 通过 Docker 在同一个服务器上搭建主从集群(一主一从)
耀耀_很无聊
【实施】实施日记mysqldocker服务器
04_MySQL通过Docker在同一个服务器上搭建主从集群(一主一从)准备工作1.拉取MySQL镜像bash复制编辑dockerpullmysql:8.0.262.创建主从配置目录bash复制编辑mkdir-p/root/mysql/master/confmkdir-p/root/mysql/master/datamkdir-p/root/mysql/master/mysql-filesmkdi
- Squirrel: 通用SQL、NoSQL客户端
antui1957
安装配置数据库配置驱动配置连接如果你的工作中,需要使用到多个数据库,又不想在多种客户端之间切换来切换去。那么就需要找一款支持多数据库的客户端工具了。如果你要连接多个关系型数据库,你就可以使用NavicatPremium。但是如果你有使用到NOSQL(譬如HBase、MongoDB等),还是建议使用SquirrelSQLClient。1、安装下载地址:http://squirrel-sql.sour
- Ubuntu 安装Mongodb
追道人
curl远程连接服务器配置mongodbubuntulinux
卸载Mongodb#停止mongodb服务sudoservicemongodstop#删除包sudoapt-getpurgemongodb-org*#删除数据文件及日志文件sudorm-r/var/log/mongodbsudorm-r/var/lib/mongodbMongodb命令sudoservicemongodstop#停止服务sudoservicemongodstart#启动服务sudo
- python读mongodb很慢_Python3.5+Mongodb+Flask Web实战坑点小结【Dog Plus】
weixin_39604685
我不是程序员,也不是设计师,我只是碰巧有一些想法和一台电脑。Iamnotadesignernoracoder.I'mjustaguywithapoint-of-viewandacomputer.写在前言前:第一个WEB部署完毕,觉得有必要做一个小结:开发平台及工具:Win10+Pycharm+Py3.5+Flask+Mongodb回头看看,一旦选择这样的套装就注定要有很多坑来填。建议后来者能用Li
- MongoDB 常用配置详解
panbuhei
MongoDBmongodb
官方参考文档:https://docs.mongodb.com/v3.2/reference/configuration-options/从2.6版本开始,MongoDB配置文件支持YAML的格式;原来的配置文件格式还保持向后兼容性。systemLog模块示例:systemLog:verbosity:0quiet:falsedestination:filelogAppend:truepath:/u
- mysql主从表配置文件_mysql主从复制配置
代土
mysql主从表配置文件
#以下是mysql5.6及5.7版本的,其他版本不知是否一致目的:1.为了冗余备份,主库挂了,切换到从库使用2.为了实现读写分离,主从复制是实现读写分离的前提主从复制的原理图:配置步骤:1.修改配置文件vim/etc/my.cnf#不同mysql的server-id需要不同主库添加配置信息:[mysqld]server-id=1log-bin=z-mysql-bin从库添加配置信息:[mysqld
- MySQL的主从和分库分表
snow_7
MySQL
主从分离:多读少些的场景MySQL1)主从复制使用的是binlog异步的方式MySQL的主从复制是依赖于binlog的,也就是记录MySQL上的所有变化并以二进制形式保存在磁盘上二进制日志文件。主从复制就是将binlog中的数据从主库传输到从库上,一般这个过程是异步的,即主库上的操作不会等待binlog同步的完成。主从复制的过程是这样的:首先从库在连接到主节点时会创建一个IO线程,用以请求主库更新
- MySql表设计经验记录
拄杖忙学轻声码
MySQLOraclePostgreSQLmysql
业务表关系设计:一、缓存、表设计(多对多关系表、最新一条数据Id冗余设计法)二、一对多数据表,在实际业务场景中,主表数据只有一个,从表数据经常会不定时新增数据,每次新增从表数据时可以把这条最新的数据(Id或编号)更新到主表中(用来标识获取从表最新的一条数据)三、主从表字段同步标识设计法1、主表增加特殊标识,需要控制从表数据对主表数据的可见度或其他业务等2、此时可以采用主从表特殊标识属性同步法,也就
- 安装MySql服务集群,主从复制模式,MySql 8.x为例
拄杖忙学轻声码
Linux部署与安装MySQLOraclePostgreSQLmysql
说明:在高并发的应用中,mysql数据库经常成为系统的瓶颈之一。为了解决这一问题,使用主从复制(Master-SlaveReplication)可以有效地分担数据库的读压力。主从复制是一种异步复制模式,允许将一个主数据库的数据复制到一个或多个从数据库,所有的写操作都在主数据库上执行,而从数据库主要用于读操作一、准备假设我们有两台服务器:1、主服务器(Master):192.168.0.12、从服务
- 数据库搭建集群之主从复制
gardenia_a
初级程序猿
数据库搭建集群之主从复制安装数据库去官网https://www.mysql.com/在linux系统下修改配置my.conf(windows是my.ini)主服务加上server_id=1一台从服务器是server_id=2,一台从服务器server_id=3重启数据库linux命令servicemysqldstart在进行数据库配置主数据执行:让从库来找到GRANTREPLICATIONSLAV
- 点赞功能真的有必要上 Redis 吗?(Mongo、MySQL、Redis、MQ 实测性能对比)
陈亦康
Redis深入学习经验分享面试总结redis数据库缓存
免费查看本文章可前往我的网站:PiQiu目录一、你会怎么设计一个点赞功能?1.1、点赞实现思路1.2、点赞功能设计1.2.1、MySQL单表1.2.2、单表+MySQL关联表1.2.3、MySQL关联表+mq1.2.4、redis+mq1.2.5、mongodb关联文档二、性能测试2.1、前置说明2.2、10万数据准备三、基于Mongo的几种点赞功能设计思路3.1、前置说明:点赞功能设计到的业务3
- MongoDB06 - MongoDB 地理空间
是小崔啊
#mongoDBmongodb网络数据库
MongoDB06-MongoDB地理空间文章目录MongoDB06-MongoDB地理空间一:地理空间数据基础1:地理数据表示方式1.1:GeoJSON格式1.2:传统坐标对2:地理空间索引2.1:2dsphere索引2.2:2d索引2.3:混合索引二:地理空间查询和聚合1:完全包含于几何图形2:与指定几何图形相交3:找附近点并按距离排序4:地理空间的聚合操作5:地理空间计算函数三:实际应用示例
- MySQL5.7评估数据库层binlog过滤写入
颖妍--唯爱
数据库mysql
binlog-do-db参数的影响本次测试均为binlog_format=row格式,因为binlog_format=statement格式在复制场景下,对函数和存储过程使用不友好,很容易导致主从数据不一致,生产环境很少有使用statement格式。使用use指定库在test库进行ddl操作和dml操作[root@localhost]15:17:10[test]>flushbinarylogs;Q
- EM储能网关&ZWS智慧储能云应用(11) — 一级架构&主从架构
ZLG 致远电子
能源
ZWS智慧储能云针对储能场景下不同的架构体系进行了兼容,可以适配用户面临的复杂现场环境,满足更深层次的管理和维护需求。 简介储能系统包含PCS、BMS、EMS等多个组件,不同储能架构管理和决策方式也有不同。为了适配用户面临的复杂现场环境,满足更深层次的管理和维护需求,ZWS智慧储能云平台支持两种架构:一级架构和主从架构。 一级架构&主从架构支持1.架构图
- Redis 集群架构
妖怪兮诺
数据库redis架构数据库
Redis集群是什么Redis集群是一种通过将多个Redis节点连接在一起以实现高可用性、数据分片和负载均衡的技术。它允许Redis在不同节点上同时提供服务,提高整体性能和可靠性。根据搭建的方式和集群的特点,Redis集群主要有三种模式:主从复制模式(Master-Slave)、哨兵模式(Sentinel)和Cluster模式Redis集群的作用和优势高可用性负载均衡容灾恢复数据分片易于拓展Mas
- 实战|StarRocks 通过 JDBC Catalog 访问 MongoDB 的数据
方案介绍本文档介绍如何通过StarRocks的JDBCCatalog功能,结合MongoDBBIConnector,将MongoDB数据便捷接入StarRocks,实现数据打通和SQL查询分析,以下是整体流程图。前提条件StarRocks环境:版本≥3.0,支持JDBCCatalog功能。MongoDBBIConnector:已安装并运行,版本需与MongoDB兼容(参考MongoDB官方文档)。
- FTTR(Fiber to the Room)一主一从
FTTR(FibertotheRoom)一主一从是家庭或企业光纤组网中的一种设备配置方式,具体含义如下:1.基本概念FTTR:指光纤直接延伸到每个房间(替代传统网线),实现全屋千兆/万兆覆盖。一主一从:由一台主光猫(主网关)和一台从光猫(从网关)组成的网络架构,通过光纤连接,形成主从协作的网络系统。2.主设备和从设备的作用主光猫(主网关)直接连接运营商的光纤入户线路,负责拨号、路由、Wi-Fi覆盖
- 什么是 MongoDB?它的主要特点有哪些?
真IT布道者
android
一、MongoDB概述MongoDB是一个开源的、面向文档的NoSQL数据库系统,由MongoDBInc.公司开发并维护。它采用BSON(BinaryJSON)格式存储数据,属于分布式文档数据库的类别。关键结论:MongoDB通过灵活的文档模型、水平扩展能力和丰富的查询功能,成为现代应用开发中最流行的NoSQL数据库之一。二、核心架构特点1.文档数据模型MongoDB使用文档(Document)作
- 矩阵求逆(JAVA)初等行变换
qiuwanchi
矩阵求逆(JAVA)
package gaodai.matrix;
import gaodai.determinant.DeterminantCalculation;
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
/**
* 矩阵求逆(初等行变换)
* @author 邱万迟
*
- JDK timer
antlove
javajdkschedulecodetimer
1.java.util.Timer.schedule(TimerTask task, long delay):多长时间(毫秒)后执行任务
2.java.util.Timer.schedule(TimerTask task, Date time):设定某个时间执行任务
3.java.util.Timer.schedule(TimerTask task, long delay,longperiod
- JVM调优总结 -Xms -Xmx -Xmn -Xss
coder_xpf
jvm应用服务器
堆大小设置JVM 中最大堆大小有三方面限制:相关操作系统的数据模型(32-bt还是64-bit)限制;系统的可用虚拟内存限制;系统的可用物理内存限制。32位系统下,一般限制在1.5G~2G;64为操作系统对内存无限制。我在Windows Server 2003 系统,3.5G物理内存,JDK5.0下测试,最大可设置为1478m。
典型设置:
java -Xmx
- JDBC连接数据库
Array_06
jdbc
package Util;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class JDBCUtil {
//完
- Unsupported major.minor version 51.0(jdk版本错误)
oloz
java
java.lang.UnsupportedClassVersionError: cn/support/cache/CacheType : Unsupported major.minor version 51.0 (unable to load class cn.support.cache.CacheType)
at org.apache.catalina.loader.WebappClassL
- 用多个线程处理1个List集合
362217990
多线程threadlist集合
昨天发了一个提问,启动5个线程将一个List中的内容,然后将5个线程的内容拼接起来,由于时间比较急迫,自己就写了一个Demo,希望对菜鸟有参考意义。。
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.CountDownLatch;
public c
- JSP简单访问数据库
香水浓
sqlmysqljsp
学习使用javaBean,代码很烂,仅为留个脚印
public class DBHelper {
private String driverName;
private String url;
private String user;
private String password;
private Connection connection;
privat
- Flex4中使用组件添加柱状图、饼状图等图表
AdyZhang
Flex
1.添加一个最简单的柱状图
? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
<?xml version=
"1.0"&n
- Android 5.0 - ProgressBar 进度条无法展示到按钮的前面
aijuans
android
在低于SDK < 21 的版本中,ProgressBar 可以展示到按钮前面,并且为之在按钮的中间,但是切换到android 5.0后进度条ProgressBar 展示顺序变化了,按钮再前面,ProgressBar 在后面了我的xml配置文件如下:
[html]
view plain
copy
<RelativeLa
- 查询汇总的sql
baalwolf
sql
select list.listname, list.createtime,listcount from dream_list as list , (select listid,count(listid) as listcount from dream_list_user group by listid order by count(
- Linux du命令和df命令区别
BigBird2012
linux
1,两者区别
du,disk usage,是通过搜索文件来计算每个文件的大小然后累加,du能看到的文件只是一些当前存在的,没有被删除的。他计算的大小就是当前他认为存在的所有文件大小的累加和。
- AngularJS中的$apply,用还是不用?
bijian1013
JavaScriptAngularJS$apply
在AngularJS开发中,何时应该调用$scope.$apply(),何时不应该调用。下面我们透彻地解释这个问题。
但是首先,让我们把$apply转换成一种简化的形式。
scope.$apply就像一个懒惰的工人。它需要按照命
- [Zookeeper学习笔记十]Zookeeper源代码分析之ClientCnxn数据序列化和反序列化
bit1129
zookeeper
ClientCnxn是Zookeeper客户端和Zookeeper服务器端进行通信和事件通知处理的主要类,它内部包含两个类,1. SendThread 2. EventThread, SendThread负责客户端和服务器端的数据通信,也包括事件信息的传输,EventThread主要在客户端回调注册的Watchers进行通知处理
ClientCnxn构造方法
&
- 【Java命令一】jmap
bit1129
Java命令
jmap命令的用法:
[hadoop@hadoop sbin]$ jmap
Usage:
jmap [option] <pid>
(to connect to running process)
jmap [option] <executable <core>
(to connect to a
- Apache 服务器安全防护及实战
ronin47
此文转自IBM.
Apache 服务简介
Web 服务器也称为 WWW 服务器或 HTTP 服务器 (HTTP Server),它是 Internet 上最常见也是使用最频繁的服务器之一,Web 服务器能够为用户提供网页浏览、论坛访问等等服务。
由于用户在通过 Web 浏览器访问信息资源的过程中,无须再关心一些技术性的细节,而且界面非常友好,因而 Web 在 Internet 上一推出就得到
- unity 3d实例化位置出现布置?
brotherlamp
unity教程unityunity资料unity视频unity自学
问:unity 3d实例化位置出现布置?
答:实例化的同时就可以指定被实例化的物体的位置,即 position
Instantiate (original : Object, position : Vector3, rotation : Quaternion) : Object
这样你不需要再用Transform.Position了,
如果你省略了第二个参数(
- 《重构,改善现有代码的设计》第八章 Duplicate Observed Data
bylijinnan
java重构
import java.awt.Color;
import java.awt.Container;
import java.awt.FlowLayout;
import java.awt.Label;
import java.awt.TextField;
import java.awt.event.FocusAdapter;
import java.awt.event.FocusE
- struts2更改struts.xml配置目录
chiangfai
struts.xml
struts2默认是读取classes目录下的配置文件,要更改配置文件目录,比如放在WEB-INF下,路径应该写成../struts.xml(非/WEB-INF/struts.xml)
web.xml文件修改如下:
<filter>
<filter-name>struts2</filter-name>
<filter-class&g
- redis做缓存时的一点优化
chenchao051
redishadooppipeline
最近集群上有个job,其中需要短时间内频繁访问缓存,大概7亿多次。我这边的缓存是使用redis来做的,问题就来了。
首先,redis中存的是普通kv,没有考虑使用hash等解结构,那么以为着这个job需要访问7亿多次redis,导致效率低,且出现很多redi
- mysql导出数据不输出标题行
daizj
mysql数据导出去掉第一行去掉标题
当想使用数据库中的某些数据,想将其导入到文件中,而想去掉第一行的标题是可以加上-N参数
如通过下面命令导出数据:
mysql -uuserName -ppasswd -hhost -Pport -Ddatabase -e " select * from tableName" > exportResult.txt
结果为:
studentid
- phpexcel导出excel表简单入门示例
dcj3sjt126com
PHPExcelphpexcel
先下载PHPEXCEL类文件,放在class目录下面,然后新建一个index.php文件,内容如下
<?php
error_reporting(E_ALL);
ini_set('display_errors', TRUE);
ini_set('display_startup_errors', TRUE);
if (PHP_SAPI == 'cli')
die('
- 爱情格言
dcj3sjt126com
格言
1) I love you not because of who you are, but because of who I am when I am with you. 我爱你,不是因为你是一个怎样的人,而是因为我喜欢与你在一起时的感觉。 2) No man or woman is worth your tears, and the one who is, won‘t
- 转 Activity 详解——Activity文档翻译
e200702084
androidUIsqlite配置管理网络应用
activity 展现在用户面前的经常是全屏窗口,你也可以将 activity 作为浮动窗口来使用(使用设置了 windowIsFloating 的主题),或者嵌入到其他的 activity (使用 ActivityGroup )中。 当用户离开 activity 时你可以在 onPause() 进行相应的操作 。更重要的是,用户做的任何改变都应该在该点上提交 ( 经常提交到 ContentPro
- win7安装MongoDB服务
geeksun
mongodb
1. 下载MongoDB的windows版本:mongodb-win32-x86_64-2008plus-ssl-3.0.4.zip,Linux版本也在这里下载,下载地址: http://www.mongodb.org/downloads
2. 解压MongoDB在D:\server\mongodb, 在D:\server\mongodb下创建d
- Javascript魔法方法:__defineGetter__,__defineSetter__
hongtoushizi
js
转载自: http://www.blackglory.me/javascript-magic-method-definegetter-definesetter/
在javascript的类中,可以用defineGetter和defineSetter_控制成员变量的Get和Set行为
例如,在一个图书类中,我们自动为Book加上书名符号:
function Book(name){
- 错误的日期格式可能导致走nginx proxy cache时不能进行304响应
jinnianshilongnian
cache
昨天在整合某些系统的nginx配置时,出现了当使用nginx cache时无法返回304响应的情况,出问题的响应头: Content-Type:text/html; charset=gb2312 Date:Mon, 05 Jan 2015 01:58:05 GMT Expires:Mon , 05 Jan 15 02:03:00 GMT Last-Modified:Mon, 05
- 数据源架构模式之行数据入口
home198979
PHP架构行数据入口
注:看不懂的请勿踩,此文章非针对java,java爱好者可直接略过。
一、概念
行数据入口(Row Data Gateway):充当数据源中单条记录入口的对象,每行一个实例。
二、简单实现行数据入口
为了方便理解,还是先简单实现:
<?php
/**
* 行数据入口类
*/
class OrderGateway {
/*定义元数
- Linux各个目录的作用及内容
pda158
linux脚本
1)根目录“/” 根目录位于目录结构的最顶层,用斜线(/)表示,类似于
Windows
操作系统的“C:\“,包含Fedora操作系统中所有的目录和文件。 2)/bin /bin 目录又称为二进制目录,包含了那些供系统管理员和普通用户使用的重要
linux命令的二进制映像。该目录存放的内容包括各种可执行文件,还有某些可执行文件的符号连接。常用的命令有:cp、d
- ubuntu12.04上编译openjdk7
ol_beta
HotSpotjvmjdkOpenJDK
获取源码
从openjdk代码仓库获取(比较慢)
安装mercurial Mercurial是一个版本管理工具。 sudo apt-get install mercurial
将以下内容添加到$HOME/.hgrc文件中,如果没有则自己创建一个: [extensions] forest=/home/lichengwu/hgforest-crew/forest.py fe
- 将数据库字段转换成设计文档所需的字段
vipbooks
设计模式工作正则表达式
哈哈,出差这么久终于回来了,回家的感觉真好!
PowerDesigner的物理数据库一出来,设计文档中要改的字段就多得不计其数,如果要把PowerDesigner中的字段一个个Copy到设计文档中,那将会是一件非常痛苦的事情。