[TOC]
系统信息
图数据库版本信息
| 图数据库 | 版本 | 备注 |
|---|---|---|
| Neo4J | 3.2 | |
| OrientDB | 2.2.x | |
| ArangoDB、 | 3.1.19 | 有密钥失效问题,导致无法下载成功server端 |
| Titan | 1.0.0 | 需要集群,暂不分析 |
OS&库信息
- OS:Ubuntu 16.04
- 虚拟机VM12
- python3驱动
- python-arango
- neo4j-driver
- PyOrient
- 绘图库:MatPlotLib+Numpy
- 性能监测库:psutil
测试信息
- 测试所得四张图分别为
- 数量时间图,斜率越小性能越好
- CPU平均占用率图
- RAM使用图
- 硬盘剩余空间图
图数据库分类
NoSQL数据库类别:
- 键值(Key-Value)数据库
- 面向文档(Document-Oriented)数据库
- 列存储(Wide Column Store/Column-Family)数据库
- 图(Graph-Oriented)数据库
单次写入速率分析
- 图数据库引擎全部打开,自动绘图
一万节点十万插入速度
插入一万顶点V
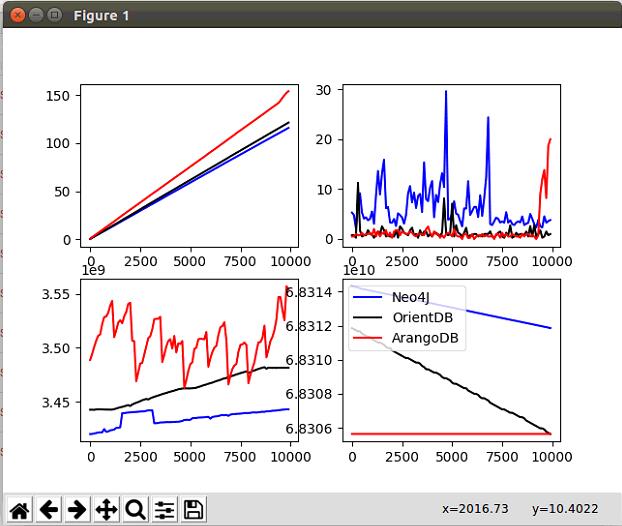
简单分析
- 三个图数据库所消耗插入节点时间相差无几,性能高低依次OrientDB>Neo4J>ArangoDB
- ArangoDB的节点hash可能随节点数量的提高而降低插入节点的性能
- CPU使用情况为Neo4J使用率高于OrentDB,ArangoDB在最后有个提升,且结合第一张图ArangoDB在最后斜率升高推测ArangoDB可能插入节点斜率随着节点数的增多而降低。这是因为ArangoDB在存储节点时候会计算
_key的Hash而产生的性能降低,但是节点插入的速度的Y轴与后面计算的Y轴不在同一数量级上,ArangoDB牺牲插入节点的性能提高后续的性能是很值得。 - 对RAM使用情况,ArangoDB>OrientDB>Neo4J
- 硬盘使用情况,OrientDB>Neo4J>ArangoDB
结论
在插入节点这步骤:
- ArangoDB建立Hash索引,所以插入节点时候的性能会稍微有点低,RAM占用最大,所消耗的存储空间最小。
- Neo4J进行了CPU的密集计算,对RAM和硬盘的占用率不高。
- OrientDB插入耗时最短,CPU,RAM也占用较低,建立BS树索引的优势,但是磁盘消耗大,其以文档形式直接存储数据而不进行前期的预处理,结合后面的数据可以看出,OrientDB和ArangoDB虽然都支持文档数据库和图数据,但OrientDB更加偏重于文档数据的存储,而不是图数据的分析。
插入十万边E
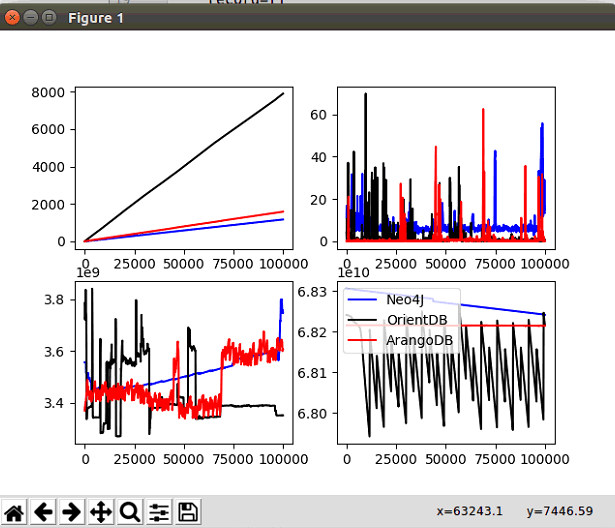
简单分析
- 插入边中,耗时长短依次:OrientDB>ArangoDB>Neo4J,从这可以看出,没有在节点环节作出合适预处理的OrientDB在插入关系的时候的性能远远落后于ArangoDB和Neo4J。
- CPU占用上,Neo4J>OrientDB>ArangoDB
- 磁盘使用情况:Neo4J>OrientDB>ArangoDB
结论
- 在插入边的情况下,ArangDB性能依旧稍稍落后于Neo4J,但其在CPU、RAM和磁盘占用上都不如ArangoDB
- OrientDB则是性能落后很多,且插入边时候磁盘的剩余空间波动巨大,可能是其中产生了缓存文件之类。
- OrientDB在插入E时性能差距太大
遍历邻节点
- 邻节点深度为1
- 采用了三个图数据库内置的广度优先算法
一万节点遍历
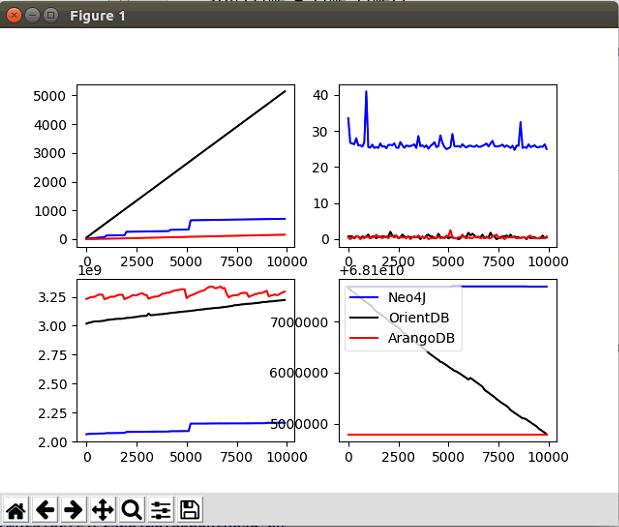
分析
- ArangoDB在存储节点时候所消耗的性能在做图计算时候带来了巨大的性能优势,便利和最短路径都因此受益,便利时间依次:OrientDB>Neo4J>ArangoDB
- Neo4J的图为折线,这意味着如果没有相邻节点Neo4J可以快速发现,而OrientDB和ArangoDB则会逼近直线。
- Neo4J节点存在大量关系其运行时间消耗大,关系越多耗时越久,不适合大关系的图。
- Neo4J和ArangoDB是图遍历中性能较好的两种,Neo4J依赖于CPU的计算力去遍历图,ArangoDB则依赖内存
- Neo4J和ArangoDB皆不会因为遍历而消耗磁盘空间,OrientDB会。
- OrientDB在遍历时候消耗的磁盘空间可能就是为了优化后面图算法所做的准备,这可以在最短路径的图算法结论中看出。
- 以磁盘空间来优化算法速度。
- OrientDB遍历性能太低
最短路径
- 采用了三个图数据库内置的Dijkstra算法
一万节点相互最短路径
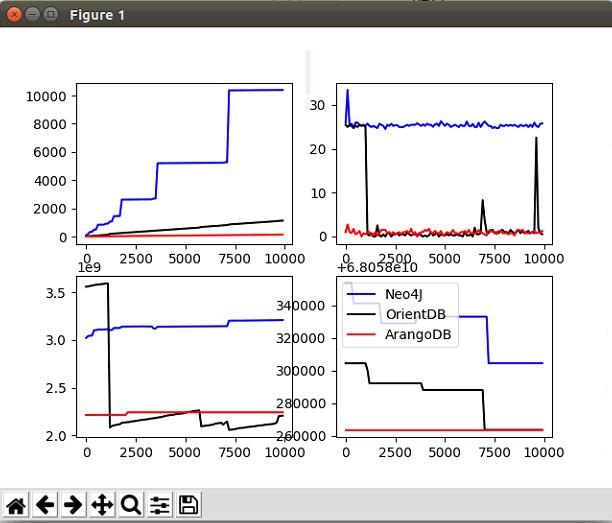
分析
- 在查找两节点最短路径时候,所消耗时间:Neo4J>OrientDB>ArangoDB
- Neo4J依旧是折线,综合两个图算法,Neo4J有办法快速找到没有关系的孤立节点。因为index-free adjacency的关系。
- OrientDB在做最短路径时候性能相比Neo4J高很多。
- 对CPU的利用:Neo4J>OrientDB>ArangoDB,且OrientDB很稳定
- 在做最短路径时候,除了ArangoDB,其他两个都会消耗磁盘空间。
综合分析
Neo4J、OrientDB、ArangoDB在插入数据时候都会默认的建立索引,性能的差距有部分就是因为自身索引的选择导致的,各自理念不同;
- Neo4J:index-free adjacency,擅长遍历图,以及计算不存在大量关系的节点的图
- OrientDB:侧重文档数据库,主要还是SB树索引导致,空间浪费比较大;插入节点与另外两个数据库相差无几,但是在插入关系中另外两个数据库都做了优化,OrientDB无优化,就挂了;在图论计算力上性能优异,但是在遍历中还是优化不够,被甩开。
- ArangoDB:对于V和E文档都建立了索引,
_key、_from、_to,保证了内部自身查找文档数据的快速
What “Graph First” Means for Native Graph Technology
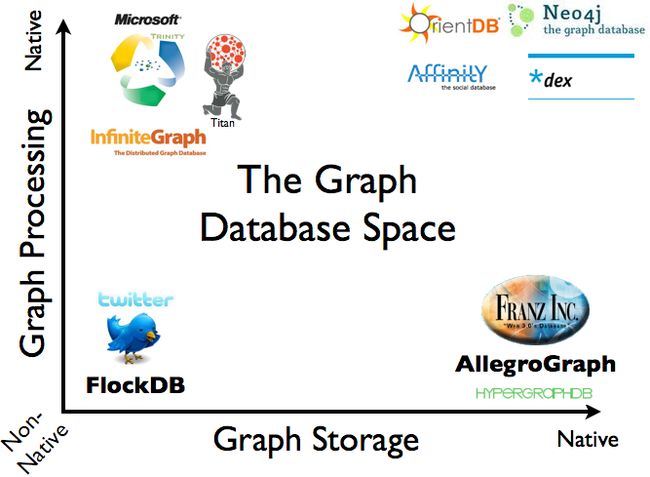
[Oreilly Graph Databases](../Neo4J/docs/Oreilly Graph Databases.pdf) Figure 1.3
There are two main elements that distinguish native graph technology: storage and processing. ——native-vs-non-native-graph-technology
具体就是阐述了Native比Non-Native好之类的。
简要阐述
| Name | ArangoDB | OrientDB | Neo4J |
|---|---|---|---|
| 数据库类型 | multi-model DBMS | multi-model DBMS | graph database |
| 数据模型 | Document store、Graph DBMS、Key-value store | Document store、Graph DBMS、Key-value store | Graph DBMS |
| 适合的操作系统 | Linux、OS X、Raspbian、Solaris、Windows | All OS with a Java JDK (>= JDK 6) | Linux、OS X、Solaris、Windows |
| 事物支持 | ACID | ACID | ACID |
| 外键 | No | Yes | Yes |
- ArangoDB与OrientDB都是文档和图数据库的综合体,V和E都是分别存储在不同的文档的中,然后通过文档去构建图,不同之处:
- ArangoDB以文档数据库模式存储图,以特殊字段标识(
_from,_to)文档类型成为V和E文档,作为图数据库基础。 - OrientDB采用了OOP的继承的方式去实现了V和E两个类;
- ArangoDB以文档数据库模式存储图,以特殊字段标识(
- ArangoDB优化了
_key字段,可以很简单hash,且本身也被优化了; - Neo4J的存储方式是分别存储了V和E作为两个文件;
ArangoDB企业版存在一个smartGraph的功能,未尝试。
图数据库存储数据类型——复杂度与灵活性关系:

ArangoDB
优点:ArangoDB FAQ、
- 存储空间占用下:采用了元数据模式存储数据;Wiki元数据
- 可通过内存提速,CPU占用率低
- 支持主从集群
- Multi-collection transactions
- 扩展性好:JavaScript;
- 用JavaScript和ArangoDB构建应用,Foxx微服务运行在DB内部,可快速访问数据。
- AQL功能很强大,配置编程远方便与灵活于Neo4J、OrientDB
- Neo4J的Cypher也比较强大,清晰,但是不利于调整,灵活性不够
- OrientDB,类SQL,查询繁琐,调整不便利,内置SQL函数接口也不方便。
缺点:
- 插入性能稍低
- ArangoDB doesn’t compete with massively distributed systems like Cassandra with thousands of nodes and many terabytes of data.ArangoDB FAQ
Cassandra :用于储存收件箱等简单格式数据——Wiki
The Apache Cassandra database is the right choice when you need scalability and high availability without compromising performance. Linear scalability and proven fault-tolerance on commodity hardware or cloud infrastructure make it the perfect platform for mission-critical data.Cassandra's support for replicating across multiple datacenters is best-in-class, providing lower latency for your users and the peace of mind of knowing that you can survive regional outages.
——Apache Cassandra
索引
- 自动索引
_key属性,_from和_to属性;保证V和E的查找的速度。ArangoDB默认索引
Neo4J
优点
- 可集群,使用读/写负载平衡器将请求直接到一个集群;[Oreilly Graph Databases](../Neo4J/docs/Oreilly Graph Databases.pdf),Figure 4.9
- 支持事物、锁、页面缓存;[Oreilly Graph Databases](../Neo4J/docs/Oreilly Graph Databases.pdf),Figure 6.3
- 遍历下:建立索引通常成本O(log(n)),但Neo4J的遍历一个关系的复杂度趋向于O(1);[Oreilly Graph Databases](../Neo4J/docs/Oreilly Graph Databases.pdf) Page:151
- index-free adjacency:提供high-performance traversals, queries, and writes
- Neo4j uses relationships, not indexes, for fast traversals;O(1)
- ArangoDB写了篇文章:Index Free Adjacency or Hybrid Indexes for Graph Databases,讲述了这个技术被自己干掉;
- 存储节点时使用了”index-free adjacency”,即每个节点都有指向其邻居节点的指针,可以让我们在O(1)的时间内找到邻居节点。
- 图形关系的最佳存储模式,嵌入式、高性能、轻量级
- Cypher语法友好
缺点
- Neo4j没法存储巨大的一张关系图 ,因为他不支持分片
- Neo4j 3.1支持因果集群并改进了安全,主写副读
- 可集群,使用读/写负载平衡器将请求直接到一个集群;[Oreilly Graph Databases](../Neo4J/docs/Oreilly Graph Databases.pdf),Figure 4.9
- 因为index-free adjacency,遍历快但是计算随机两个节点最短路径性能不佳
分片(sharding)是MongoDB 用来将大型集合分割到不同服务器(或者说一个集群)上所采用的方法。尽管分片起源于关系型数据库分区,但它(像MongoDB 的大部分方面一样)完全是另一回事。
——什么是分片
文件存储
- 存储关系 record 数组数据:
- relationships are stored in the relationship store file,
neostore.relationshipstore.db. - 存储关系ID:
neostore.relationshipstore.db.id
- relationships are stored in the relationship store file,
- 存储关系组数据及其序列Id:
-
neostore.relationshipgroupstore.db存储关系 group数组数据 neostore.relationshipgroupstore.db.id
-
- 存储关系类型及其序列Id:
-
neostore.relationshiptypestore.db存储关系类型数组数据 neostore.relationshiptypestore.db.id
-
- 存储关系类型的名称及其序列Id:
-
neostore.relationshiptypestore.db.names存储关系类型 token 数组数据 neostore.relationshiptypestore.db.names.id
-
OrientDB
优点
- 安装简单,功能丰富
- OrientDB是兼具文挡数据库的灵活性和图形数据库管理链接能力的可深层次扩展的文档-图形数据库管理系统(NoSQL数据库)。
- 可选无模式、全模式或混合模式下。支持许多高级特性,诸如ACID事务、快速索引,原生和SQL查询功能。
- 可以JSON格式导入、导出文档。
- 若不执行昂贵的JOIN操作的话,如同关系数据库可在几毫秒内可检索数以百记的链接文档图。
缺点
- 坑很多:Tackling a 1 Billion Member Social Network – Fast Search on a Large Graph
- 性能和可扩展性不好
存储原理
OrientDB本地存储原则:使用包含由固定大小部分(页面)分割的磁盘数据并写入日志记录方法的磁盘缓存(当页面中的更改首先记录在所谓的持久存储器中时),我们可以实现以下特性:OrientDB 2.2.x——PLocal Engine
- Operations on single page are atomic.
- Changes applied to the page can be restored after server crash even if they were not flushed to the disk.
保护数据
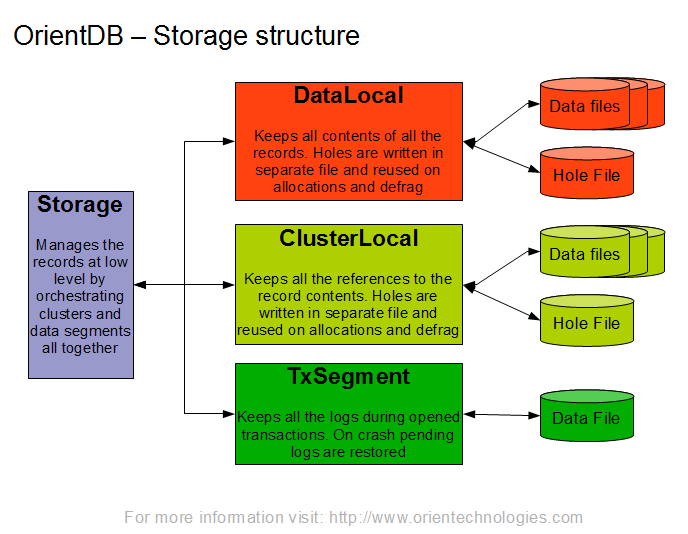
默认索引
SB索引,基于B-树。SB树
- 磁盘消耗大不难理解。
- 其节点唯一标志@RID就是SB索引树的父节点标识吧,推测。
- 插入关系先获得节点,在SB树索引与Neo4J和ArangoDB的实现对比下会慢。
参考资料
- Neo4j 底层存储结构分析
- System Properties Comparison ArangoDB vs. Neo4j vs. OrientDB
- Benchmark: PostgreSQL, MongoDB, Neo4j, OrientDB and ArangoDB,ArangoDB社区
- 大数据分析技术研究报告(四)
- NoSQL数据库的四大家族
- ArangoDB介绍——未知架构和底层原理
- ArangoDB FAQ
- bachelor-thesis,原文:https://lucas.dohmen.io/assets/pdfs/bachelor-thesis.pdf
- Neo4j 底层存储结构分析
- [Oreilly Graph Databases](../Neo4J/docs/Oreilly Graph Databases.pdf)
- ArangoDB_Manual_3.1.19
- Neo4j 3.1支持因果集群并改进了安全,Neo4j 3.1 Supports Causal Clustering and Security Enhancements
- native-vs-non-native-graph-technology
- Index Free Adjacency or Hybrid Indexes for Graph Databases,ArangoDB社区,讲述了Neo4J的index-free adjacency技术怎么被不看好并且被它KO的故事。
- ArangoDB 3.1 索引技术
- OrientDB 2.2x 索引技术
- Tackling a 1 Billion Member Social Network – Fast Search on a Large Graph;Neo4J是如何干掉OrientDB、Titan的。2016-4-20
- 图数据库:存储半结构化大数据的解决方案
- 在选择数据库的路上,我们遇到过哪些坑?(1)
- OrientDB 2.2.x——PLocal Engine