集群环境:
CenterOS 1台
Kafka:0.10.2.1版本。
今天在测试环境下,我们的Kafka集群工作不正常,具体现象为,使用confulentkafka向kafka集群生产消息失败,且并没有任何异常。
检查server配置、broker日志、程序异常日志等等都没有发现,网上搜索资料,并没有类似的现象出现,这就很令人绝望。
没办法,自己写测试程序,注册confluentkafka的producer error事件一点点打印日志。
发现一个有规律的现象:
- 发送每经过一段时间之后,producer的报告会打印Local:Mesasge Time out的异常,
经过简单分析,得出基本结论:该异常并不是引发消息发送不过去的诱因,而是结果。精力不能放到这个异常上面。
但是好歹也算是给我一个方向:producer在生产数据时,消息发送超时,并没有发送过去,超时了。
有了初步的方向,首先就要先确定
- producer-client与broker的网络连接健康状态,(这个不用多说,联系运维同事,各种测验,甚至内网ip都换了过,初步排除。)
- topic是否自动创建
- 发送消息时消息体有没有限制。
- 其他等
网络问题初步排除后,我们去检查auto.create.topics.enable的配置,默认为true,理论上来讲topic应该会自动创建。
且其他环境的topic都可以完美的自动创建。好吧,抱着试试看的态度,手动创建topic,然后发消息。不多说,上图
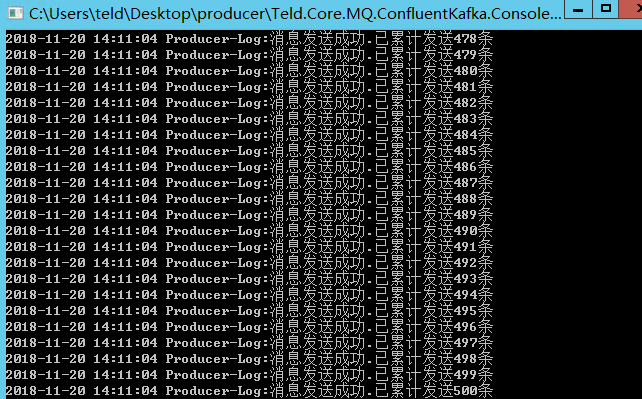
竟然发送过去了。
昨天各种测验各种排查甚至连神器windbg也没放过,都没找到问题,抱着试试看的态度一试,竟然找到了原因:因为Topic没有自动创建,导致消息发送失败。
好吧,接下来的问题就简单了,排查为啥Topic没有自动创建成功
继续注册日志事件跟进
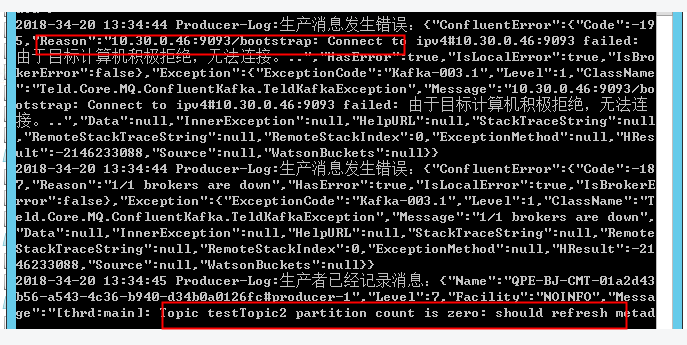
上边那个异常有误导我很长时间,暂且略过不表,跟他关系不大。
主要原因在下边:Topic Partition Count is Zero,should refresh metadata。
我们知道,metadata的信息是存在zookeeper中的,有可能是broker和zookeeper的信息同步不及时或者有问题导致topic创建问题失败。
去检查server.properties(又来检查了):zookeeper.connect的配置是内网的配置10.x.x.46:2181。
鉴于zookeeper和kafka都在同一台机器上,把zookeeper的地址改成127.0.0.1,做尝试,果不其然:

Topic可以自动创建,消息生成成功,问题解决。至此,这次kafka的排障就告一段路。
结论:生产发送失败时,主要从以下几个方向入手检查
1、要检查网络连通性
2、topic是否正常创建
3、kafka和zookeeper的连通性,重要的事情要重点标注。