1.新建IntelliJ下空的的maven项目
直接next即可。
2.配置依赖
编辑pom.xml文件,添加apache源和hadoop依赖
基础依赖hadoop-core和hadoop-common;
读写HDFS,需要依赖hadoop-hdfs和hadoop-client;
如果需要读写HBase,则还需要依赖hbase-client
UTF-8
hadoop
http://maven.apache.org
org.apache.hadoop
hadoop-common
2.8.1
org.apache.hadoop
hadoop-hdfs
2.8.1
org.apache.hadoop
hadoop-client
2.8.1
3.添加core-site.xml到resources文件
将虚拟机上的hadoop下/etc/hadoop/core-site.xml文件拷贝到此项目下resources文件夹下
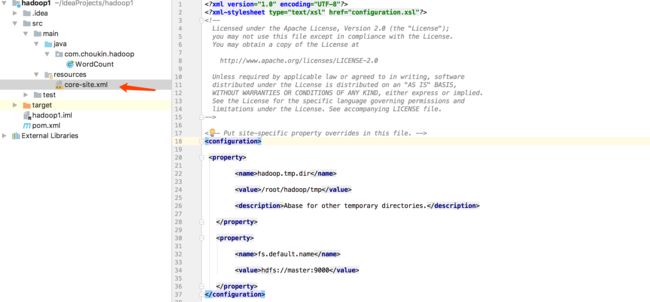
注意master是我虚拟机ip地址的映射,如果没有配置hosts文件那么这里应该填的是你虚拟机的IP地址。
4.编写一个WordCount类
WordCount.java
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapreduce.cluster.local.dir","/Users/CHOUKIN/hadoop/var");//在此处有一坑,本地需要添加一个缓存文件夹
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
注意:conf.set("mapreduce.cluster.local.dir","/Users/CHOUKIN/hadoop/var");//在此处有一坑,本地需要添加一个缓存文件夹
如果没有这个本地缓存文件夹,会报以下错误
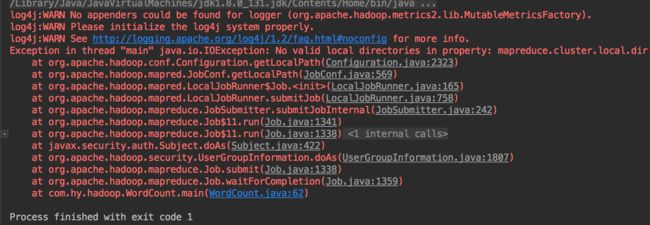
查询hadoop官网docs关于mapred-default.xml参数简介
mapreduce.cluster.local.dir :
The local directory where MapReduce stores intermediate data files. May be a comma-separated list of directories on different devices in order to spread disk i/o. Directories that do not exist are ignored.
这个参数是MapReduce 存储中间数据文件的本地目录。对不同的设备上的目录可以用逗号分隔,用以加快磁盘 i/o 。不存在的目录将被忽略。
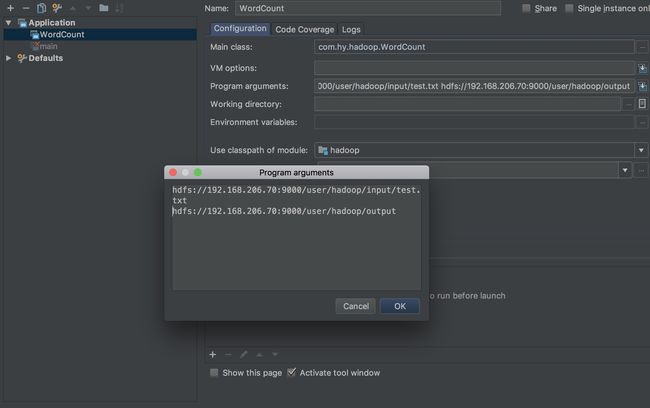
5.配置运行参数
在Intellij菜单栏中选择Run->Edit Configurations,在弹出来的对话框中点击+,新建一个Application配置。配置Main class为WordCount(可以点击右边的...选择),
为Program arguments添加输入路径以及输出路径,记得把ip地址改为自己虚拟机的ip地址
6.运行程序
拷贝了一篇满分英语作文在test.txt里,运行结果如下

每次运行时检查hdfs上是否有output文件夹,如果有,请删除output文件夹。
感谢我的基友月巴巴提供了莫大的帮助
参考:
hadoop文档关于mapred-default.xml参数详解
常用 Hadoop 集群参数(mapred-default.xml)