Prometheus K8S中部署Alertmanager
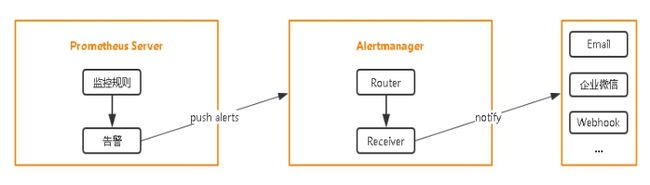
设置告警和通知的主要步骤如下:
一、部署Alertmanager
二、配置Prometheus与Alertmanager通信
三、配置告警
1. prometheus指定rules目录
2. configmap存储告警规则
3. configmap挂载到容器rules目录
一、部署Alertmanager
配置文件
已经修改好的配置文件
- # 存储主配置文件
- alertmanager-configmap.yaml
-
 配置文件
配置文件apiVersion: v1 kind: ConfigMap metadata: # 配置文件名称 name: alertmanager-config namespace: kube-system labels: kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: EnsureExists data: alertmanager.yml: | global: resolve_timeout: 5m # 告警自定义邮件 smtp_smarthost: 'smtp.163.com:25' smtp_from: '[email protected]' smtp_auth_username: '[email protected]' smtp_auth_password: 'liang123' receivers: - name: default-receiver email_configs: - to: "[email protected]" route: group_interval: 1m group_wait: 10s receiver: default-receiver repeat_interval: 1m
- # 部署核心组件
- alertmanager-deployment.yaml
-
配置文件
apiVersion: apps/v1 kind: Deployment metadata: name: alertmanager namespace: kube-system labels: k8s-app: alertmanager kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile version: v0.14.0 spec: replicas: 1 selector: matchLabels: k8s-app: alertmanager version: v0.14.0 template: metadata: labels: k8s-app: alertmanager version: v0.14.0 annotations: scheduler.alpha.kubernetes.io/critical-pod: '' spec: priorityClassName: system-cluster-critical containers: - name: prometheus-alertmanager image: "prom/alertmanager:v0.14.0" imagePullPolicy: "IfNotPresent" args: - --config.file=/etc/config/alertmanager.yml - --storage.path=/data - --web.external-url=/ ports: - containerPort: 9093 readinessProbe: httpGet: path: /#/status port: 9093 initialDelaySeconds: 30 timeoutSeconds: 30 volumeMounts: - name: config-volume mountPath: /etc/config - name: storage-volume mountPath: "/data" subPath: "" resources: limits: cpu: 10m memory: 50Mi requests: cpu: 10m memory: 50Mi - name: prometheus-alertmanager-configmap-reload image: "jimmidyson/configmap-reload:v0.1" imagePullPolicy: "IfNotPresent" args: - --volume-dir=/etc/config - --webhook-url=http://localhost:9093/-/reload volumeMounts: - name: config-volume mountPath: /etc/config readOnly: true resources: limits: cpu: 10m memory: 10Mi requests: cpu: 10m memory: 10Mi volumes: - name: config-volume configMap: name: alertmanager-config - name: storage-volume persistentVolumeClaim: claimName: alertmanager
- # 使用的自动PV存储
- alertmanager-pvc.yaml
-
配置文件
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: alertmanager namespace: kube-system labels: kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: EnsureExists spec: # 使用自己的动态PV storageClassName: managed-nfs-storage accessModes: - ReadWriteOnce resources: requests: storage: "2Gi"
- # 暴露Prot端口
- alertmanager-service.yaml
-
配置文件
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: alertmanager namespace: kube-system labels: kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: EnsureExists spec: # 使用自己的动态PV storageClassName: managed-nfs-storage accessModes: - ReadWriteOnce resources: requests: storage: "2Gi" [root@Master1 ~]# cat alertmanager-service.yaml apiVersion: v1 kind: Service metadata: name: alertmanager namespace: kube-system labels: kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/name: "Alertmanager" spec: ports: - name: http port: 80 protocol: TCP targetPort: 9093 selector: k8s-app: alertmanager type: "ClusterIP"
部署
1、创建pvc、configmap、deployment、service
kubectl apply -f alertmanager-pvc.yaml kubectl create -f alertmanager-configmap.yaml kubectl apply -f alertmanager-deployment.yaml kubectl apply -f alertmanager-service.yaml
2、查看Pod状态
kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
alertmanager-5bb796cb48-fwztv 2/2 Running 0 2m29s
3、查看service状态
kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE alertmanager ClusterIP 10.0.0.12680/TCP
二、配置Prometheus与Alertmanager通信
1、编辑 prometheus-configmap.yaml 配置文件添加绑定信息
# Prometheus configuration format https://prometheus.io/docs/prometheus/latest/configuration/configuration/ apiVersion: v1 kind: ConfigMap metadata: name: prometheus-config namespace: kube-system labels: kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: EnsureExists data: # 存放prometheus配置文件 prometheus.yml: | # 配置采集目标 scrape_configs: - job_name: prometheus static_configs: - targets: # 采集自身 - localhost:9090 prometheus.yml: | # 配置采集目标 scrape_configs: - job_name: kubernetes-nodes static_configs: - targets: # 采集自身 - 192.168.1.110:9100 - 192.168.1.111:9100 # 采集:Apiserver 生存指标 # 创建的job name 名称为 kubernetes-apiservers - job_name: kubernetes-apiservers # 基于k8s的服务发现 kubernetes_sd_configs: - role: endpoints # 使用通信标记标签 relabel_configs: # 保留正则匹配标签 - action: keep # 已经包含 regex: default;kubernetes;https source_labels: - __meta_kubernetes_namespace - __meta_kubernetes_service_name - __meta_kubernetes_endpoint_port_name # 使用方法为https、默认http scheme: https tls_config: # promethus访问Apiserver使用认证 ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt # 跳过https认证 insecure_skip_verify: true # promethus访问Apiserver使用认证 bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token # 采集:Kubelet 生存指标 - job_name: kubernetes-nodes-kubelet kubernetes_sd_configs: # 发现集群中所有的Node - role: node relabel_configs: # 通过regex获取关键信息 - action: labelmap regex: __meta_kubernetes_node_label_(.+) scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt insecure_skip_verify: true bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token # 采集:nodes-cadvisor 信息 - job_name: kubernetes-nodes-cadvisor kubernetes_sd_configs: - role: node relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) # 重命名标签 - target_label: __metrics_path__ replacement: /metrics/cadvisor scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt insecure_skip_verify: true bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token # 采集:service-endpoints 信息 - job_name: kubernetes-service-endpoints # 选定指标 kubernetes_sd_configs: - role: endpoints relabel_configs: - action: keep regex: true # 指定源标签 source_labels: - __meta_kubernetes_service_annotation_prometheus_io_scrape - action: replace regex: (https?) source_labels: - __meta_kubernetes_service_annotation_prometheus_io_scheme # 重命名标签采集 target_label: __scheme__ - action: replace regex: (.+) source_labels: - __meta_kubernetes_service_annotation_prometheus_io_path target_label: __metrics_path__ - action: replace regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 source_labels: - __address__ - __meta_kubernetes_service_annotation_prometheus_io_port target_label: __address__ - action: labelmap regex: __meta_kubernetes_service_label_(.+) - action: replace source_labels: - __meta_kubernetes_namespace target_label: kubernetes_namespace - action: replace source_labels: - __meta_kubernetes_service_name target_label: kubernetes_name # 采集:kubernetes-services 服务指标 - job_name: kubernetes-services kubernetes_sd_configs: - role: service # 黑盒探测,探测IP与端口是否可用 metrics_path: /probe params: module: - http_2xx relabel_configs: - action: keep regex: true source_labels: - __meta_kubernetes_service_annotation_prometheus_io_probe - source_labels: - __address__ target_label: __param_target # 使用 blackbox进行黑盒探测 - replacement: blackbox target_label: __address__ - source_labels: - __param_target target_label: instance - action: labelmap regex: __meta_kubernetes_service_label_(.+) - source_labels: - __meta_kubernetes_namespace target_label: kubernetes_namespace - source_labels: - __meta_kubernetes_service_name target_label: kubernetes_name # 采集: kubernetes-pods 信息 - job_name: kubernetes-pods kubernetes_sd_configs: - role: pod relabel_configs: - action: keep regex: true source_labels: # 只保留采集的信息 - __meta_kubernetes_pod_annotation_prometheus_io_scrape - action: replace regex: (.+) source_labels: - __meta_kubernetes_pod_annotation_prometheus_io_path target_label: __metrics_path__ - action: replace regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 source_labels: # 采集地址 - __address__ # 采集端口 - __meta_kubernetes_pod_annotation_prometheus_io_port target_label: __address__ - action: labelmap regex: __meta_kubernetes_pod_label_(.+) - action: replace source_labels: - __meta_kubernetes_namespace target_label: kubernetes_namespace - action: replace source_labels: - __meta_kubernetes_pod_name target_label: kubernetes_pod_name alerting: # 告警配置文件 alertmanagers: # 修改:使用静态绑定 - static_configs: # 修改:targets、指定地址与端口 - targets: ["alertmanager:80"]
2、应用加载配置文件
kubectl apply -f prometheus-configmap.yaml
3、web控制台查看配置是否生效
http://192.168.1.110:42575/config
三、配置告警
1. prometheus指定rules目录
1、编辑 prometheus-configmap.yaml 添加报警信息
apiVersion: v1 kind: ConfigMap metadata: name: prometheus-config namespace: kube-system labels: kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: EnsureExists data: prometheus.yml: | # 添加:指定读取rules配置 rules_files: - /etc/config/rules/*.rules ......
2、生效配置文件
kubectl apply -f prometheus-configmap.yaml
2. configmap存储告警规则
1、创建yaml文件同过configmap存储告警规则
vim prometheus-rules.yaml
apiVersion: v1 kind: ConfigMap metadata: name: prometheus-rules namespace: kube-system data: # 通用角色 general.rules: | groups: - name: general.rules rules: - alert: InstanceDown expr: up == 0 for: 1m labels: severity: error annotations: summary: "Instance {{ $labels.instance }} 停止工作" description: "{{ $labels.instance }} job {{ $labels.job }} 已经停止5分钟以上." # Node对所有资源的监控 node.rules: | groups: - name: node.rules rules: - alert: NodeFilesystemUsage expr: 100 - (node_filesystem_free_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100) > 80 for: 1m labels: severity: warning annotations: summary: "Instance {{ $labels.instance }} : {{ $labels.mountpoint }} 分区使用率过高" description: "{{ $labels.instance }}: {{ $labels.mountpoint }} 分区使用大于80% (当前值: {{ $value }})" - alert: NodeMemoryUsage expr: 100 - (node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100 > 80 for: 1m labels: severity: warning annotations: summary: "Instance {{ $labels.instance }} 内存使用率过高" description: "{{ $labels.instance }}内存使用大于80% (当前值: {{ $value }})" - alert: NodeCPUUsage expr: 100 - (avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) * 100) > 60 for: 1m labels: severity: warning annotations: summary: "Instance {{ $labels.instance }} CPU使用率过高" description: "{{ $labels.instance }}CPU使用大于60% (当前值: {{ $value }})"
3. configmap挂载到容器rules目录
1、修改挂载点位置,使用之前部署的prometheus动态PV
vim prometheus-statefulset.yaml
apiVersion: apps/v1 kind: StatefulSet metadata: name: prometheus # 部署命名空间 namespace: kube-system labels: k8s-app: prometheus kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile version: v2.2.1 spec: serviceName: "prometheus" replicas: 1 podManagementPolicy: "Parallel" updateStrategy: type: "RollingUpdate" selector: matchLabels: k8s-app: prometheus template: metadata: labels: k8s-app: prometheus annotations: scheduler.alpha.kubernetes.io/critical-pod: '' spec: priorityClassName: system-cluster-critical serviceAccountName: prometheus # 初始化容器 initContainers: - name: "init-chown-data" image: "busybox:latest" imagePullPolicy: "IfNotPresent" command: ["chown", "-R", "65534:65534", "/data"] volumeMounts: - name: prometheus-data mountPath: /data subPath: "" containers: - name: prometheus-server-configmap-reload image: "jimmidyson/configmap-reload:v0.1" imagePullPolicy: "IfNotPresent" args: - --volume-dir=/etc/config - --webhook-url=http://localhost:9090/-/reload volumeMounts: - name: config-volume mountPath: /etc/config readOnly: true resources: limits: cpu: 10m memory: 10Mi requests: cpu: 10m memory: 10Mi - name: prometheus-server # 主要使用镜像 image: "prom/prometheus:v2.2.1" imagePullPolicy: "IfNotPresent" args: - --config.file=/etc/config/prometheus.yml - --storage.tsdb.path=/data - --web.console.libraries=/etc/prometheus/console_libraries - --web.console.templates=/etc/prometheus/consoles - --web.enable-lifecycle ports: - containerPort: 9090 readinessProbe: # 健康检查 httpGet: path: /-/ready port: 9090 initialDelaySeconds: 30 timeoutSeconds: 30 livenessProbe: httpGet: path: /-/healthy port: 9090 initialDelaySeconds: 30 timeoutSeconds: 30 # based on 10 running nodes with 30 pods each resources: limits: cpu: 200m memory: 1000Mi requests: cpu: 200m memory: 1000Mi # 数据卷 volumeMounts: - name: config-volume mountPath: /etc/config - name: prometheus-data mountPath: /data # 添加:指定rules的configmap配置文件名称 - name: prometheus-rules mountPath: /etc/config/rules subPath: "" terminationGracePeriodSeconds: 300 volumes: - name: config-volume configMap: name: prometheus-config # 添加:name rules - name: prometheus-rules # 添加:配置文件 configMap: # 添加:定义文件名称 name: prometheus-rules volumeClaimTemplates: - metadata: name: prometheus-data spec: # 使用动态PV storageClassName: managed-nfs-storage accessModes: - ReadWriteOnce resources: requests: storage: "16Gi"
2、创建configmap并更新PV
kubectl apply -f prometheus-rules.yaml
kubectl apply -f prometheus-statefulset.yaml
3、查看Pod
kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
prometheus-0 1/2 Running 0 42s