第一步去:spark.apache.org官网去选择适合自己的版本下载安装包
第二步:解压tgz文件,配置SPARK_HOME到环境变量中
tar zxvf 文件名.tgz
vi /etc/profile

第三步: 进入spark安装位置, 然后进入spark中的 bin 文件夹
运行: ./bin/spark-shell 运行scala

在启动后的结果页面上可以看到spark的webUI的控制台地址,可以在浏览器中访问的。
在yarn上运行spark
必须确保在spark中指定hadoop的集群配置文件所在的目录,如下英文所述

编辑$SPARK_HOME/conf/spark-env.sh文件
加入内容为:
HADOOP_CONF_DIR=/usr/hadoop/hadoop-2.6.0-cdh5.7.0/etc/hadoop
To launch a Spark application in cluster mode:(用cluster模式执行一个jar程序)
$ ./bin/spark-submit --class path.to.your.Class --master yarn --deploy-mode cluster [options]
例子:
For example:
${SPARK_HOME}/bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 4g \
--executor-memory 2g \
--executor-cores 1 \
--queue thequeue \
examples/jars/spark-examples*.jar \
10
以客户端client的模式在yarn上启动spark:
$ ./bin/spark-shell --master yarn --deploy-mode client
退出spark-shell
【注意】在Spark使用结束时,务必使用 :quit 退出。否则下次再启动,将导致端口被占用的错误。
用java语言编写测试样例
首先确保自己的jdk版本在1.8及其以上,并且调整项目的编译版本为1.8,因为1.8以下的版本不支持lambda 表达式
idea的工具中,file--》project-structure--》Language Level

这样spark样例的写法就可以正确解析了:如下

打包我们的本地程序上传到装有spark服务的服务器中:
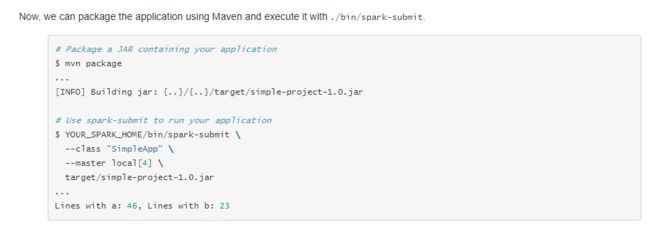
打包的时候就会发现,maven也要配置1.8的jdk才能打包成功:

执行自己编写的jar包
spark-submit --class "com.sc.spark.SparkApp" --master local[4] /usr/spark/spark-2.1.1-bin-hadoop2.6/examples/jars/bigdata-1.1.1-jar-with-dependencies.jar
在yarn上执行自己的jar
spark-submit --class com.sc.sparksql.RDD2DataFrame --master yarn --deploy-mode client /usr/spark-2.1.1-bin-hadoop2.6/examples/jars/bigdata-1.1.1-jar-with-dependencies.jar
spark-defaults.conf配置文件
配置spark的日志生成到hdfs上去
spark.eventLog.enabled=true
spark.eventLog.compress=true
#保存在本地#
spark.eventLog.dir=file:///usr/local/hadoop-2.7.6/logs/userlogs
#spark.history.fs.logDirectory=file:///usr/local/hadoop-2.7.6/logs/userlogs
#保存在hdfs上
spark.eventLog.dir=hdfs://spark-master:9000/tmp/logs/root/logs
spark.history.fs.logDirectory=hdfs://spark-master:9000/tmp/logs/root/logs
yarn-site.xml
启动
1.首先启动 hadoop的jobhistory
[root@spark-master hadoop-2.7.6]#
sbin/mr-jobhistory-daemon.sh start historyserver
2.启动spark的history-server
[root@spark-master spark-2.3.0]#
sbin/start-history-server.sh
spark-shell加载文件
从spark-shell所在机器目录读取文件:
scala> val acclog = sc.textFile("file:///usr/hadoop/testdata/access-kf0911.log")

从spark-shell所以来的hdfs上读取文件:
scala> val acclog = sc.textFile("/usr/hadoop/testdata/access-kf0911.log")
获取acclog的第一行数据:

查看数据结构化信息:
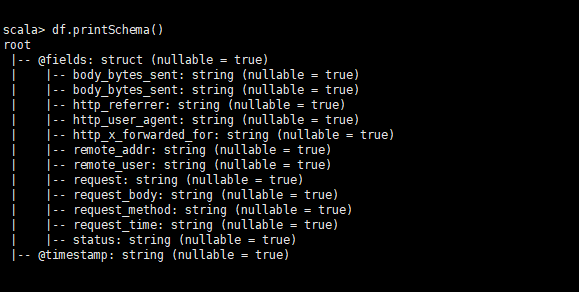
解析嵌套的json文件

如果想要全部展示省略的部分就在show方法里传入一个参数为false,例如:df.show(false)
加载外部数据源:
加载Parquet格式数据:
spark.read.format("parquet").load("file///usr/textdata/test.parquet");//加载本地文件
spark.read.format("parquet").load("hdfs://usr/textdata/test.parquet");//加载hdfs上的文件
DataFrame和RDD的区别
DataFrame(等同于关系性数据库的表格结构)=RDD+Schema(表的名字、字段、类型等)
DataFrame在底层是用Catalyst来优化的,并且比RDD多了Schema信息。
DataFrame可以处理的数据类型有:text,json,Parquet,外部数据源等。
我们操作数据不论用SQl方式还是用API的方式来处理,最后都转化成Catalyst optimized优化执行引擎来处理,效率都是一样的。
Schema特点
Schema信息分为两种包含方式,一种是隐式,一种是显式的包含。
显式的一般由json、Parquet格式的数据文件本来就有Schema信息。text数据就没有schema信息,必须指定Schema信息。指定Schema信息的步骤分为以下三个步骤
第一步:Create an RDD of Rows from the original RDD;
第二步:Create the schema represented by a StructType matching the structure of Rows in the RDD created in Step
第三步:Apply the schema to the RDD of Rows via createDataFrame method provided by SparkSession.

如何把我们计算后的数据存储起来?

df.select("name").write.format("parquet").mode("overwrite").save("hdfs:/路径");//存放到hdfs中
df.select("name").write.format("parquet").mode("overwrite").save("file:///路径");//存放到服务器本地
如何处理json数据
json数据是一种非常易读的数据格式,而且是一行一行的存储,并且它已经具备了schema信息了。
如果你想把json的数据进行抽离,通常我们用explode方法来操作
如果你想对内嵌的json数据进行访问,你可以用“.”的方式来访问
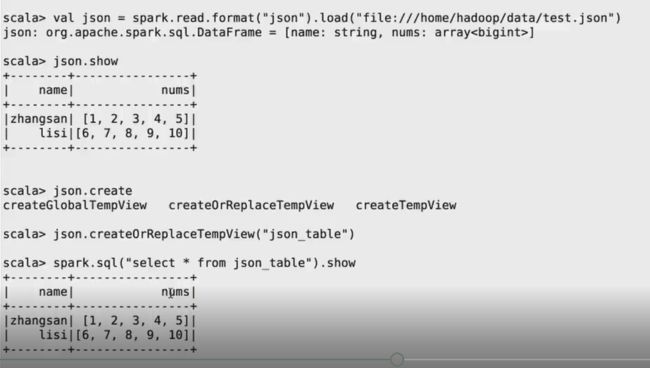

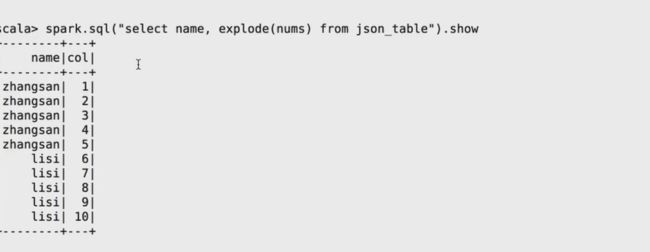
对嵌套性的数据处理



spark sql的覆盖率
spark2.0以上版本,已经完全支持sql 2003的sql特性、可以执行99%的TPC-DS测试查询、子查询也可以支持、支持向量化(每次可以读取1024行,降低读取次数,提升查询速度)
spark sql支持的外部数据源
1)关系型数据库的数据,需要导入jdbc jars
2)Parquet、Phoenix、csv、avro、etc
有一个spark支持所有的数据源的网站
https://spark-packages.org
常见问题
使用spark-submit命令执行自己的jar包时,报了如下错误,我一看原来是我的spark-defaults.conf文件中的给spark配置的日志存放路径给hadopps的用户路径冲突了,本来是想复用现成的userlogs目录来使用,结果人家不让,所以我就改了另外的目录。

常见问题2:
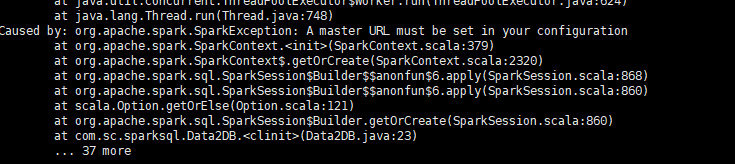
local 本地单线程在写spark程序的时候,许多人会遇到以下这个报错,包括我自己也遇到过,当时郁闷了很久
报错说在配置中必须设置一个master URL.但是我明明在提交应用的时候设置了–master呀,为什么说我没有,于是非常惊讶,怀疑是不是计算机自己疯掉了。
其实这是初学者很容易犯的错误,原因在于没有真正理解spark分布式或伪分布式的运行原理。出错的小伙伴往往把创建spark实例,或者sc.textFile读取数据等放在了main函数的外面。像下面这样写是错误的:
在伪分布式中,一个spark 应用对应了一个main函数,放在一个driver里,driver里有一个对应的实例(spark context).driver 负责向各个节点分发资源以及数据。那么如果你把创建实例放在了main函数的外面,driver就没法分发了。所以如果这样写在local模式下是可以成功的,在分布式就会报错。(好吧,解释地有点直白和不专业)
所以正确的写法应该是这样:
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("XXXX")
val sc = new SparkContext(sparkConf)
}
问题3:
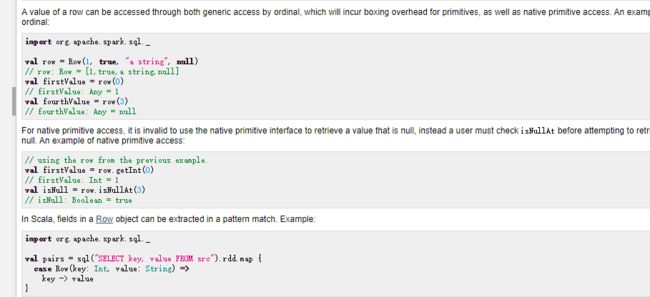
org.apache.spark.sql.Row对象中取值,如果使用get方法,索引是从0开始的
spark 的运行写入mysql库程序时,需要先把依赖的mysql的jdbc的驱动加入刀$SPARK_HOME/jars中。
如果害怕任务吃掉内存,导致服务崩溃,最好配置驱动内存和运行内存
spark-submit --class com.lppz.ReadToPvProvcity --master yarn --driver-memory 4g --executor-memory 2g --executor-cores 1 /home/hadoop/waimai/selfjars/execData-1.1-SNAPSHOT.jar ${DATE_DH}