1. 摘要
目标:挖掘竞争漏洞,如CVE-2016-8655, CVE-2017-2636, CVE-2017-17712。
问题:race漏洞受到系统不确定行为的影响,如线程调度与同步机制。
技术:静态分析定位可能引发竞争的代码;确定性的线程交错技术,控制线程调度,提供准确的并行执行信息,降低不确定性。
对比:Syzkaller[42],SKI[16]。
结果:发现30个竞争漏洞,16个已确认。
2. 问题与设计需求
(1)数据竞争定义
若两条指令满足以下条件则为数据竞争:
a.访问的内存地址相同
b.至少其中一条指令是对内存的写
c.两条指令可以并发执行
(2)标记

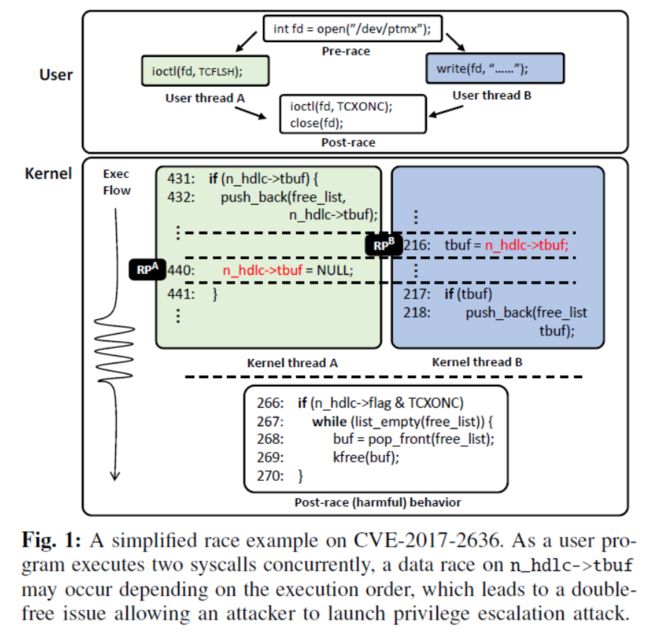
(3)竞争案例—CVE-2017-2636
两个线程分别调用ioctl(fd,TCFLSH)和write(fd,…),对变量n_hdlc->tbuf的并发读写导致竞争(n_hdlc->tbuf = NULL;与tbuf = n_hdlc->tbuf;),该内存地址在free_list中保存了两次,最后ioctl(fd,TCXONC)将导致double free。
(4)设计要求
R1——找到执行RacePair_cand的输入程序。即找到一个多线程的用户态程序,每个线程能够在内核态分别执行到RacePair_cand的指令。需求1把问题做了简化,并不去考虑并行执行的问题,就不用考虑线程调度对分析的影响。
R2——根据R1输入程序,找到并发执行RacePair_cand的线程执行序列。需求2主要是去寻找一个交错执行的线程调度方案,使得RacePair_cand的指令能并行执行。
3. 设计
整体流程如图:
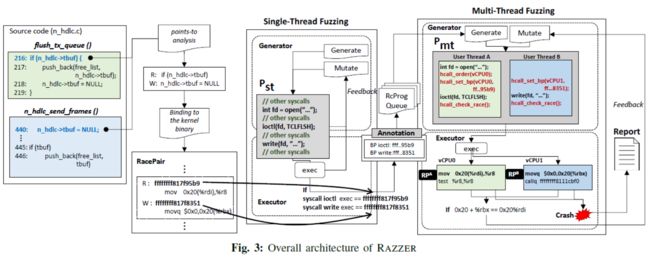
3.1静态分析—识别RacePair_cand
方法:指向分析(寻找内核中对同一个结构体的内存访问),但限制是准确率与性能,需要精确的CF/DF信息(运行时更准确)和并发信息(受到调度和同步原语的影响)。指向分析的时间开销是O(n^3)。
Razzer改进
(1)准确性
采用指向分析得到近似的RacePair_cand(上下文敏感、流敏感、区域敏感),后续通过动态分析来确认。去除不会引起竞争的指令,例如访问结构中不同变量。
(2)性能
分部分分析,减小分析的代码量。作者按目录结构划分模块,如kernel, mm, fs, drivers,但有些模块如fs和net/core会被每个模块调用。
缺点:未分析同步原语如read_lock(), br_read_lock(), spin_lock_irqsave(), up(),该分析可以排除不会引发竞争的内存对。
3.2 线程调度-hypervisor
方法:待Fuzz的内核运行在虚拟化的环境中,为了控制虚拟CPU的调度,作者修改了虚拟环境的Hypervisor,增加了三个功能。
(1)为每个虚拟CPU设置断点
超级调用接口:hcall_set_bp(vCPU_TD, guest_addr)。由虚拟机guest kernel调用,监管者收到后在guest_addr地址下硬件断点。
两点要求:
a.准确设置每个vCPU的断点:断点地址存入virtualized debug register,每个vCPU有一个VDR,就能保证只有相关vCPU执行时才会触发断点;设置Intel VT-x中Virtual Machine Control Structure (VMCS)的中断表的相应位(硬件断点中断),就能保证VMEXIT事件首先交给监管器而非guest kernel。
b.确定断点是否被指定内核线程触发:有可能是其他无关线程触发,利用virtual machine introspection(VMI)获取内核线程上下文,找到线程号,也即通过thread_info -> task_struct -> 内核线程号,确定是否被指定内核线程触发。
(2)控制线程执行顺序
Hcall_set_order(vCPU_ID),恢复指定线程执行,不同的执行顺序决定是否触发错误。
(3)检测竞争结果
检查竞争指令访问地址是否相同,相同则为RacePair_true。
3.3 多线程fuzz
(1)单线程fuzzing
目的:生成单线程程序,执行RacePair_cand。
generator:生成单线程用户程序P_st—随机syscall序列。
两种策略:一是generation,使用syzkaller[42]定义的syscall语法(含参数值范围),生成随机调用序列,传递调用参数;二是mutation,对已有的P_st进行drop/insert/change。
executor:执行P_st。
a.用KCov[3]收集执行覆盖路径,看是否有2个syscall执行RacePair_cand指令;
b.记录这2个syscall+RacePair_cand在syscall中地址+P_st,发送给多线程fuzzing。
反馈:若某个P_st产生新的路径覆盖,则作为反馈加入到变异种子队列。
(2)多线程fuzzing
目的:生成多线程程序,触发竞争。
generator:P_st→P_mt,转化为一个多线程版本P_mt。在转换过程中还会进行一些插桩,与Hypervisor协作控制程序的调度。输入P_st,i(syscall下标),j,RP_i,RP_j(竞争指令地址)。
executor:运行P_mt,检测RacePair_cand是否触发竞争。
判断条件:a.捕捉到2个断点RacePair_cand;b. RacePair_cand指令访问地址相同。
razzer竞争检查:使用lockdep[29],KASAN[2],或手动插入assertion。
反馈:导致竞争的P_mt用于进一步变异,以触发崩溃。
4.实现
4.1 静态分析
基于LLVM+SVF[39]。
改进SVF—指向分析:处理内核内存分配/释放;处理堆/全局结构中的非指针变量。
输出:RacePair_cand(含源文件名+行号),编译利用GCC的调试信息将之转化为二进制地址。
4.2 hypervisor
基于QEMU+KVM(kernel-based Virtual Machine)硬件加速;
Capstone[1]反汇编来检查RacePair_cand;
fuzzer基于Syzkaller[42]。
4.3 代码量
SVF静态分析—638 LoC C++;
QEMU实现hypervisor 652 LoC c;
Syzkaller实现fuzzer 6403 LoC Go和286 LoC。
5.评价
(1)发现的竞争漏洞,竞争漏洞列表见Fig6。
能发现很老的洞,2007,见Fig8。
Report对于漏洞修复帮助很大
(2)静态分析有效性
分部分分析效率很高见Fig9,整体分析耗时7天。
RacePair_cand有效性,有效引导到低于0.1%的可疑竞争点。
(3)hypervisor性能开销
hypercall开销很小,见Fig12。
(4)与syzkaller/SKI工具进行比较
找单线程输入程序:执行速度慢于syzkaller,但找有害竞争快于syzkaller。
找多线程交错程序:由于SKI不开源,所以根据SKI随机线程交错特性实现SKI_Emu—修改Razzer的多线程fuzzing部分(不使用hypercall),效率明显高于SKI。
6. 未来工作
(1)优化静态分析
本文假设不同内核模块之间很少有竞争,分部分分析导致错过很多RacePair_cand;提高静态分析的准确性,以识别不会竞争的指令对,可分析同步原语[14,41](如read_lock(), br_read_lock(), spin_lock_irqsave(), up(),该分析可以排除不会引发竞争的内存对)。
(2)扩展性
移植到别的OS,如Windows/MacOSX/FreeBSD。
扩展到用户程序分析,用户程序不需要其他变异策略,因为用户程序竞争和内核不一样,只要发生竞争都算作漏洞。