Android缓存浅析
By吴思博
1、引言
2、常见的几种缓存算法
3、Android缓存的机制
4、LruCache的使用(内存缓存)
5、云阅读书籍解析缓存实现(内存缓存实例,可跳过本节)
6、DiskLruCache的使用(磁盘缓存)
1、引言
我们都听过缓存,当问你什么是缓存的时候,相信你能马上给出一个完美的答案。 可是当问你缓存是怎么构建的,或者有一些怎样缓存算法和框架?android中的缓存机制 ?,你可能会心神恍惚。


2、Android缓存的机制
最近在开发书籍解析章节中遇到了一些问题,经过调试发现一部分是缓存的问题。云阅读老版本中,解析书籍正文后缓存使用的是SoftReference,很容易被回收。Android中的缓存分为内存缓存和文件缓存(磁盘缓存)。在早期常用的内存缓存方式是软引用(SoftReference)和弱引用(WeakReference),如大部分的使用方式:HashMap> imageCache;这种形式。从Android 2.3(Level 9)开始,垃圾回收器更倾向于回收SoftReference或WeakReference对象,这使得SoftReference和WeakReference变得不是那么实用有效。(到了Android 3.0(Level 11)之后,图片数据Bitmap被放置到了内存的堆区域,而堆区域的内存是由GC管理的,开发者不需要进行图片资源的释放工作,但这也使得图片数据的释放无法预知,增加了造成OOM的可能)。在Android3.1以后,Android推出了LruCache这个内存缓存类,LruCache中的对象是强引用的。
3、常见的几种缓存算法:
缓存算法有很多种,但是那种适合我们呢,下面来看看几种常见的缓存算法。
3.1:FIFO(先进先出)
先进先出,原则简单、且符合人们的惯性思维,具备公平性,并且实现起来简单,直接使用数据结构中的队列即可实现。如果一个数据最先进入缓存中,则应该最早淘汰掉。也就是说,当缓存满的时候,应当把最先进入缓存的数据给淘汰掉。实现方式:双向链表(LinkedList)保存数据,当来了新的数据之后便添加到链表末尾,如果Cache存满数据,则把链表头部数据删除,然后把新的数据添加到链表末尾。在访问数据的时候,如果在Cache中存在该数据的话,则返回对应的value值;否则返回-1。
3.2:LRU(最少使用缓存算法)
把最近最少使用的缓存对象给淘汰。LRU总是需要去了解在什么时候,用了哪个缓存对象。浏览器就是使用了LRU作为缓存算法。新的对象会被放在缓存的顶部,当缓存达到了容量极限,会把底部的对象淘汰。实现思路:把最新被访问的缓存对象,放到缓存池的顶部。当缓存达到了容量极限,会把底部的对象淘汰。所以,经常被读取的缓存对象就会一直呆在缓存池中。实现方式:使用array或者是linked list。LRU2和2Q,他们就是为了完善LRU而存在的。
Android 推荐:LruCache是Android 3.1所提供的一个缓存类,所以在Android中可以直接使用LruCache实现内存缓存。而DisLruCache目前在Android 还不是Android SDK的一部分,但Android官方文档推荐使用该算法来实现硬盘缓存。
3.3:LFU(最近使用频率最少算法)
最近使用频率最少算法;注意LFU和LRU算法的不同之处,LRU的淘汰规则是基于访问时间,而LFU是基于访问次数的。思想:当缓存满的时候,应当把访问频次最少的数据给淘汰掉。实现:利用一个数组存储数据项,用HashMap存储每个数据项在数组中对应的位置,然后为每个数据项设计一个访问频次,当数据项被命中时,访问频次自增,在淘汰的时候淘汰访问频次最少的数据。在插入数据(插到数组的尾端)和访问数据(数组随机访问)的时候都能达到O(1)的时间复杂度;淘汰数据的时候,通过选择算法得到应该淘汰的数据项在数组中的索引,并将该索引位置的内容替换为新来的数据内容即可,这样的话,淘汰数据的操作时间复杂度为O(n)。
下面几种算法都是上面的变种(可跳过):
3.4 LRU2(Least Recently Used 2):
Least Recently Used 2,又叫最近最少使用twice。LRU2把被两次访问过的对象放入缓存池,当缓存池满了之后,把有两次最少使用的缓存对象淘汰。因为需要跟踪对象2次,访问负载就会随着缓存池的增加而增加。如果把LRU2用在大容量的缓存池中,就会有问题。另外,LRU2还需要跟踪不在缓存的对象,因为他们还没有被第二次读取。LRU2比LRU好,且是adoptive to access模式。
3.5 2Q(Two Queues):
2Q把被访问的数据放到LRU的缓存中,如果这个对象再一次被访问,2Q就把他转移到第二个、更大的LRU缓存。2Q淘汰缓存对象是为了保持第一个缓存池是第二个缓存池的1/3。当缓存的访问负载是固定的时候,把LRU换成LRU2,就比增加缓存的容量更好。这种机制使得2Q比LRU2更好,2Q也是LRU家族中的一员,而且是adoptive to access模式。
3.6 ARC(Adaptive Replacement Cache):
ARC是介于LRU和LFU之间,为了提高效果,由2个LRU组成。第一个(L1)包含的条目是最近只被使用过一次的,而第二个LRU(L2)包含的是最近被使用过两次的条目。(因此,L1放的是新的对象,而L2放的是常用的对象。)所以,才会认为ARC是介于LRU和LFU之间的。
ARC被认为是性能最好的缓存算法之一,能够自调,并且是低负载的。保存着历史对象,这样就可以记住那些被移除的对象。
….. …..
4、LruCache的使用
LruCache是Android 3.1所提供的一个缓存类,所以在Android中可以直接使用LruCache实现内存缓存。而DisLruCache目前在Android还不是Android SDK的一部分,但Android官方文档推荐使用该算法来实现硬盘缓存。
LruCache的使用很简单:

或者:
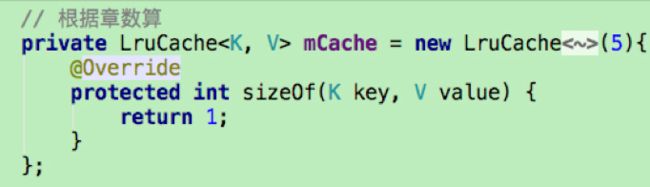
①设置LruCache缓存的大小,一般为当前进程可用容量的1/8。
②重写sizeOf方法,计算出要缓存的每张图片的大小。
注意:缓存的总容量和每个缓存对象的大小所用单位要一致。
通过下面构造函数来指定LinkedHashMap中双向链表的结构是访问顺序还是插入顺序。
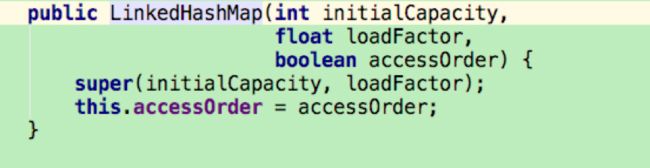
其中accessOrder设置为true则为访问顺序,为false,则为插入顺序。
当设置为true时

输出结果:
0:0 3:3 4:4 5:5 6:6 1:1 2:2
即最近访问的最后输出,那么这就正好满足的LRU缓存算法的思想。可见LruCache巧妙实现,就是利用了LinkedHashMap的这种数据结构。
下面我们在LruCache源码中具体看看,怎么应用LinkedHashMap来实现缓存的添加,获得和删除的。

从LruCache的构造函数中可以看到正是用了LinkedHashMap的访问顺序。
put()方法
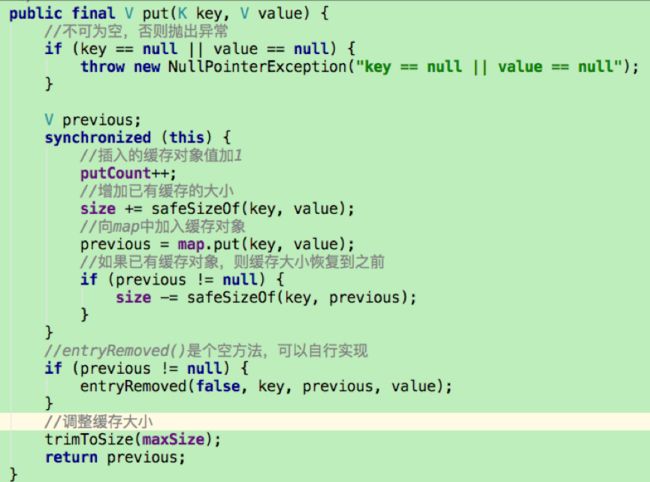
可以看到put()方法并没有什么难点,重要的就是在添加过缓存对象后,调用trimToSize()方法,来判断缓存是否已满,如果满了就要删除近期最少使用的算法。
trimToSize()方法
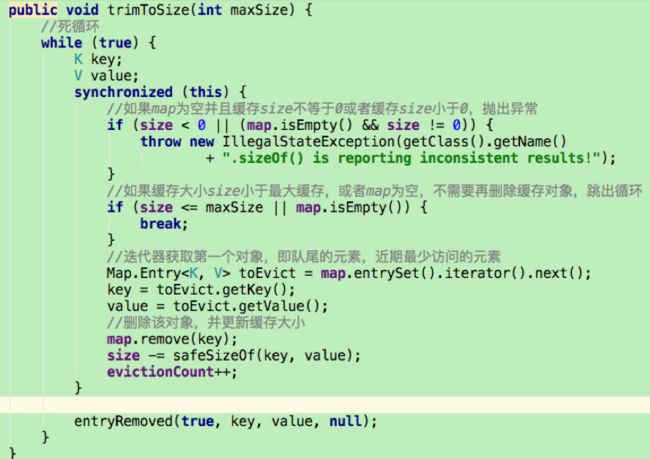
trimToSize()方法不断地删除LinkedHashMap中队尾的元素,即近期最少访问的,直到缓存大小小于最大值。
当调用LruCache的get()方法获取集合中的缓存对象时,就代表访问了一次该元素,将会更新队列,保持整个队列是按照访问顺序排序。这个更新过程就是在LinkedHashMap中的get()方法中完成的。
get()方法:
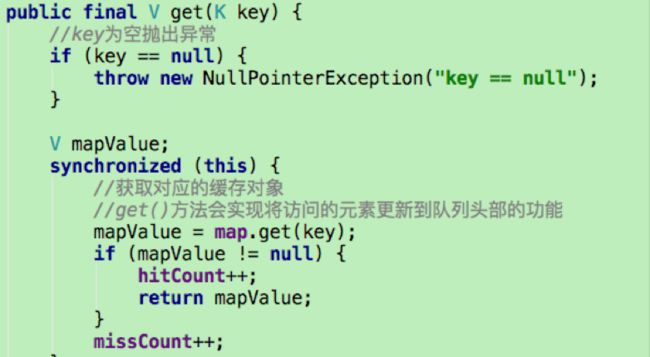
其中LinkedHashMap的get()方法如下:
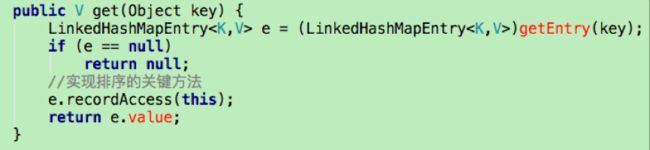
调用recordAccess()方法如下:

由此可见LruCache中维护了一个集合LinkedHashMap,该LinkedHashMap是以访问顺序排序的。当调用put()方法时,就会在结合中添加元素,并调用trimToSize()判断缓存是否已满,如果满了就用LinkedHashMap的迭代器删除队尾元素,即近期最少访问的元素。当调用get()方法访问缓存对象时,就会调用LinkedHashMap的get()方法获得对应集合元素,同时会更新该元素到队头。
5、云阅读书籍解析缓存(内存缓存实例,可跳过本节)
loadChapter()是章节解析函数,首先从缓存中获取章节解析,缓存中获取章节解析不为null,直接返回缓存数据,否则在mIGetChapterContentListener接口的onGetChapterContent()方法中获取章节内容,再进行异步解析。

mIGetChapterContentListener的onGetChapterContent()方法中使用AsyncTask对章节进行异步解析。

解析结束后,如果成功,并且当前页面为普通页或者标题页则加入缓存。
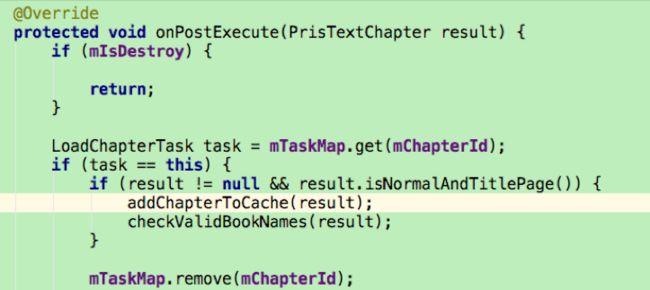
缓存函数:
、

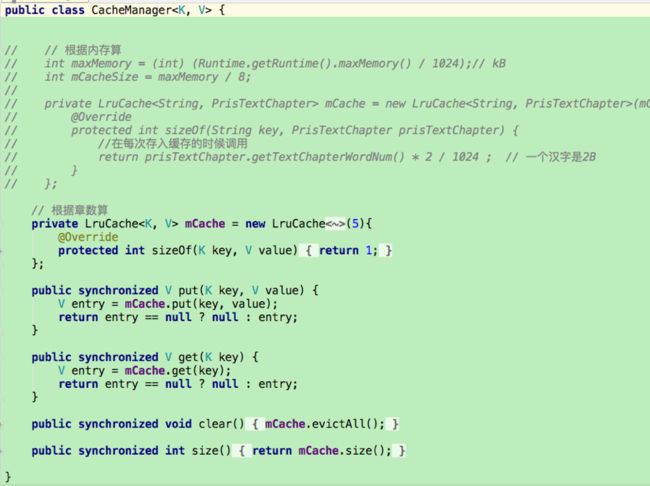
具体实现在CacheManager类中。(如果缓存算法改变,只需要修改CacheManager类)
当前CacheManager中使用LruCache算法实现。
6、DiskLruCache的使用
6.1创建

DISK_CACHE_SIZE缓存大小。
6.2添加
DishLruCache缓存添加的操作通过Eidtor完成,Editor为一个缓存对象的编辑对象。首先需要获取图片的url所对应的key,根据key利用edit()来获取Editor对象。若此时这个缓存正在被编辑,edit()会返回null。DiskLruCache不允许同时编辑同一个缓存对象。之所以把url转换成key,因为图片的url中可能存在特殊字符,会影响使用,一般将url的md5值作为key
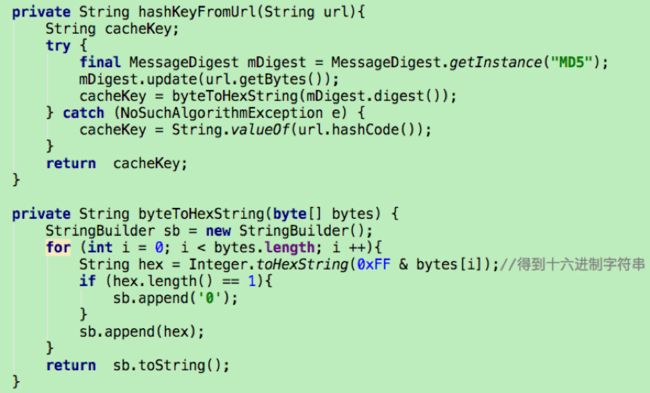
将url转成key,利用这key值获取Editor对象。若这个key的Editor对象不存在,edit()方法就创建一个新的出来。通过Editor对象可以获取一个输出流对象。DiskLruCache的open()方法中,一个节点只能有一个数据,edit.newOutputStream(DISK_CACHE_INDEX)参数设置为0

这个文件输出流,从网络加载一个图片后,通过这个OutputStream outputStream写入文件系统。

上面的代码并没有将图片写入文件系统,还需要通过Editor.commit()提交写入操作,若写入失败,调用abort()方法,进行回退整个操作。
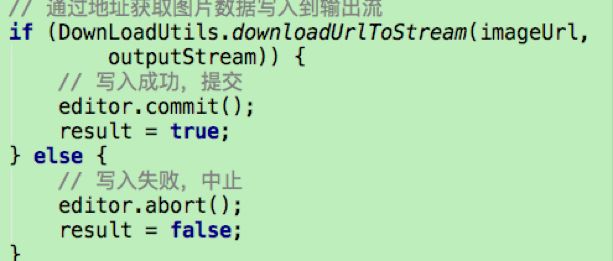
这时,图片已经正确写入文件系统,接下来的图片获取就不需要请求网络
6.3缓存查找
查找过程,也需要将url转换为key,然后通过DiskLruCache的get方法得到一个Snapshot对象,再通过Snapshot对象可得到缓存的文件输入流,有了输入流就可以得到Bitmap对象。为了避免oom,会使用ImageResizer进行缩放。若直接对FileInputStream进行操作,缩放会出现问题。FileInputStream是有序的文件流,两次decodeStream调用会影响文件流的位置属性。可以通过文件流得到其所对应的文件描述符,利用BitmapFactory.decodeFileDescriptor()方法进行缩放
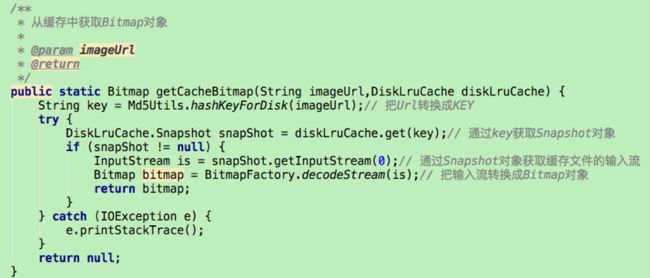
在查找得到Bitmap后,把key,bitmap添加到内存缓存中。