题外话。。。这是一个Markdown知识点。。。在段首我都想输入空格,在markdown下打不出,遂求知乎我很喜欢这个回答:Markdown 奉行的是样式和内容分开的哲学。来自王成
//半角空格(英文)
//全角空格(中文)
步入正题
这个是我上手就想发布的,临近发布出现问题,so 一直拖到了现在。。。
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算.本教程将指导如何用苹果macOS系统安装Hadoop。
安装Homebrew
习惯使用ubuntu的同学,一定很喜欢ubuntu系统apt-get的软件安装方式。macOS上也有类似这样的包管理器,利用Homebrew即可。
Homebrew的官方网站
安装Homebrew的方法:
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
需要注意的是:
Homebrew安装的软件都集中在/usr/local/Cellar里面
想了解更多有关Homebrew的知识,访问macOS 安装Homebrew和常用命令
ssh登录本地
ssh-keygen -t rsa -P
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
Shell 命令
ssh-keygen -t rsa -P ""
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
这样就可以生成ssh公钥,接下来进行测试登录本地是否成功
ssh localhost
登录成功显示结果如下:
安装Hadoop
输入以下代码,自动安装hadoop
brew install hadoop
安装过程会提示重要的信息,如下:
Updating Homebrew...
==> Auto-updated Homebrew!
Updated 1 tap (homebrew/core).
==> New Formulae
stress-ng telnetd tnftp tnftpd
==> Updated Formulae
amazon-ecs-cli fmt libfabric
angular-cli frugal logstash
apm-server gmime lxc
arangodb gnupg metricbeat
argyll-cms gopass miniupnpc
cgrep grpc neko
conjure-up harfbuzz nomad
cromwell heartbeat packetbeat
dar jenkins snappy
dlib jsoncpp spdlog
elasticsearch kibana ttyrec
etcd libbitcoin-explorer weechat
fftw libbitcoin-node yle-dl
filebeat libbitcoin-server
fio libcouchbase
Warning: hadoop 2.8.2 is already installed
在这里显示我大Hadoop已经安装成功了
在macOS中,我们可以终端输入:
/usr/libexec/java_home来获取JAVA_HOME的路径
Hadoop的安装需要配置JAVA_HOME,用 brew安装,就已经帮我们配置好了。
测试Hadoop是否安装成功
Hadoop有三种安装模式:单机模式,伪分布式模式,分布式模式
分布式模式需要在多台电脑上面测试,这里只测试前面两种,即单机模式和伪分布式模式
测试单机模式
这里使用Hadoop附带的示例来检验单机模式是否运行正常。
通过Homebrew安装的Hadoop,附带的示例在路径/usr/local/Cellar/hadoop/2.8.2/libexec/share/hadoop/mapreduce
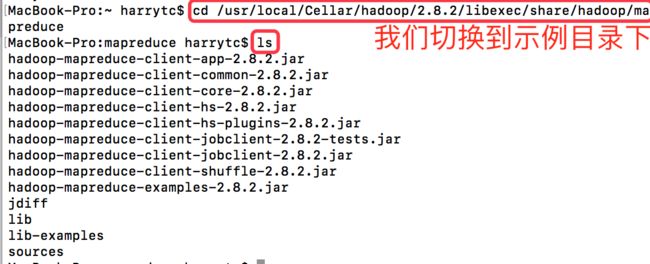
通过Homebrew默认会安装软件的最新stable版本,所以读者安装的Hadoop版本会大于或等于2.8.2版本
单词计数wordcount是最简单也是最能体现MapReduce思想的程序之一,可以称为MapReduce版”Hello World”,单词计数主要完成功能是:统计一系列文本文件中每个单词出现的次数.
- 创建input目录和output目录
input作为输入目录,output目录作为输出目录
cd /usr/local/Cellar/hadoop/2.8.2/
mkdir input
mkdir output

- 在input文件夹中创建两个测试文件file1.txt和file2.txt
cd input
echo 'hello world' > file1.txt
echo 'hello hadoop' > file2.txt

- 运行示例检测单机模式
hadoop jar /usr/local/Cellar/hadoop/2.8.2/libexec/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.2.jar wordcount /usr/local/Cellar/hadoop/2.8.2/input/ /usr/local/Cellar/hadoop/2.8.2/output/
- 查看结果
17/12/21 18:00:45 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/12/21 18:00:45 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
17/12/21 18:00:45 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory file:/usr/local/Cellar/hadoop/2.8.2/output already exists
at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:146)
at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs(JobSubmitter.java:268)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:141)
at org.apache.hadoop.mapreduce.Job$11.run(Job.java:1341)
at org.apache.hadoop.mapreduce.Job$11.run(Job.java:1338)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1836)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1338)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1359)
at org.apache.hadoop.examples.WordCount.main(WordCount.java:87)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:71)
at org.apache.hadoop.util.ProgramDriver.run(ProgramDriver.java:144)
at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:74)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:234)
at org.apache.hadoop.util.RunJar.main(RunJar.java:148)
more output/part-r-00000
显示结果如下:

测试伪分布式模式
这个可以参考官网的配置 官网☺:我在这
测试为分布模式前,需要修改相关的配置文件,把之前的单机模式修改成伪分布式模式
-
修改Core-site.xml
文件地址:/usr/local/Cellar/hadoop/2.8.2/libexec/etc/hadoop/core-site.xml
把原来的修改为
hadoop.tmp.dir /usr/local/Cellar/hadoop/hdfs/tmp A base for other temporary directories fs.default.name hdfs://localhost:9000 fs.default.name 保存了NameNode的位置,HDFS和MapReduce组件都需要用到它,这就是它出现在core-site.xml 文件中而不是 hdfs-site.xml文件中的原因
-
修改mapred-site.xml.template
文件地址:/usr/local/Cellar/hadoop/2.7.1/libexec/etc/hadoop/mapred-site.xml.template
把原来的修改为
mapred.job.tracker localhost:9010 变量mapred.job.tracker 保存了JobTracker的位置,因为只有MapReduce组件需要知道这个位置,所以它出现在mapred-site.xml文件中。
-
修改hdfs-site.xml
文件地址:/usr/local/Cellar/hadoop/2.7.1/libexec/etc/hadoop/hdfs-site.xml
把原来的修改为
dfs.replication 1 变量dfs.replication指定了每个HDFS数据库的复制次数。 通常为3, 由于我们只有一台主机和一个伪分布式模式的DataNode,将此值修改为1。
-
运行
hadoop namenode -format ./sbin/start-all.sh运行成功后,用浏览器访问:Hdfs的Web界面,可以查看相关的信息
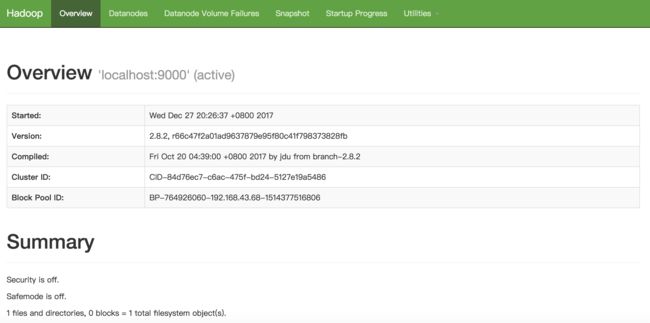
用示例测试
-
估计圆周率PI的值
hadoop jar ./libexec/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.2.jar pi 2 5运行结果如下:
Estimated value of Pi is 3.60000000000000000000 -
wordcount统计数据
把原来用于单机模式的测试input文件上传到hdfs中``` hadoop fs -put ./input input ``` 运行wordcount ``` hadoop jar ./libexec/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.2.jar wordcount input output ``` 查看output的结果文件 ``` hadoop fs -tail output/part-r-00000 ``` 得到的结果是: > * hadoop 1 > * hello 2 > * world 1 -
关闭伪分布式
./sbin/stop-all.sh

其间警告
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
一直存在,解决方法来自CSDN:
Hadoop自身的原因,需要自己编译Makefile里所需要的libhadooppipes.a和libhadooputils.a这两个静态库文件以适应自己系统的需求 (官网说预编译的是32位库,如果你是64位的才需要重新编译,可是我主机虽是64位但虚拟机系统是32位的,不知道为什么也不行需要重新编译)这个你可以去下载就行,下载对应的版本即可
文章修改自http://dblab.xmu.edu.cn/blog/820-2/