Inception v1
Inception v1也叫GoogLeNet 。
这是Google的一篇论文,在当时无法网络深度上提升网络性能时,论文另辟蹊径,改用加大网络的宽度方法。使用多通道卷积进行构建更宽的网络,不仅提高模型在分类的效果,也提高了模型在目标检测的效果。主要构建一种 Inception module。如下所示:
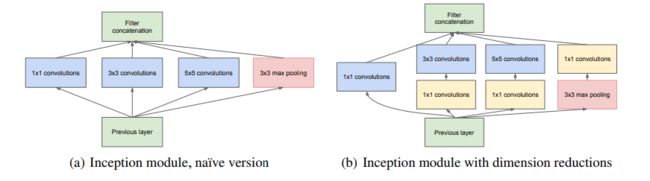
左图对输入做了4个分支,分别用不同尺寸的filter进行卷积或池化,最后再在特征维度上拼接到一起。这种全新的结构有什么好处呢?Szegedy从多个角度进行了解释:
在直观感觉上在多个尺度上同时进行卷积,能提取到不同尺度的特征。特征更为丰富也意味着最后分类判断时更加准确。
四个分支同步进行会导致计算爆炸,所在会在进行计算之前使用1x1卷积进行通道的尺度缩放。
下面就是Inception v1的全整个网络图。
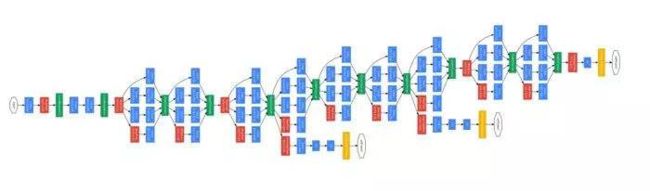
上图中,在网络的中间层还有两个中间的loss,在中间进行权重的调整调整。
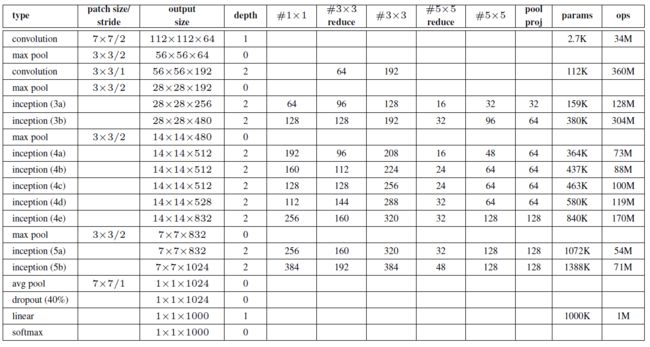
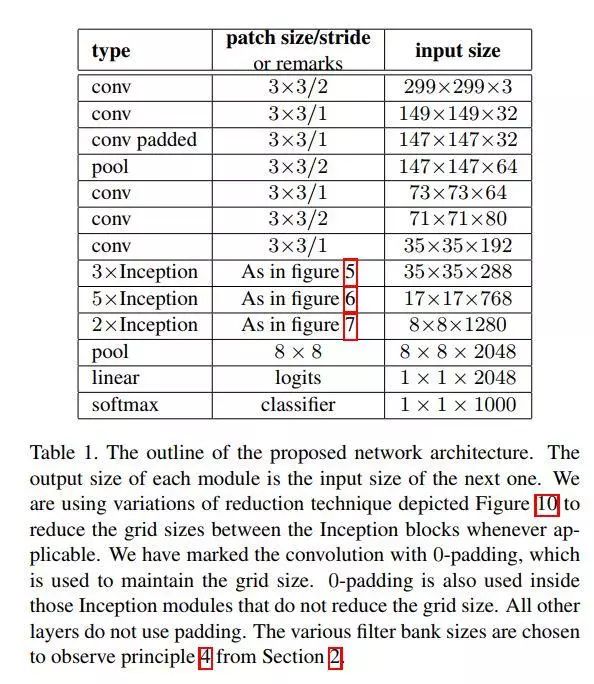
各层的卷积尺度。作者提到输入尺寸是224x224.所以这里的7x7 / 2卷积输入是224x224x3的图片,输出就是112x112x3.
VGG
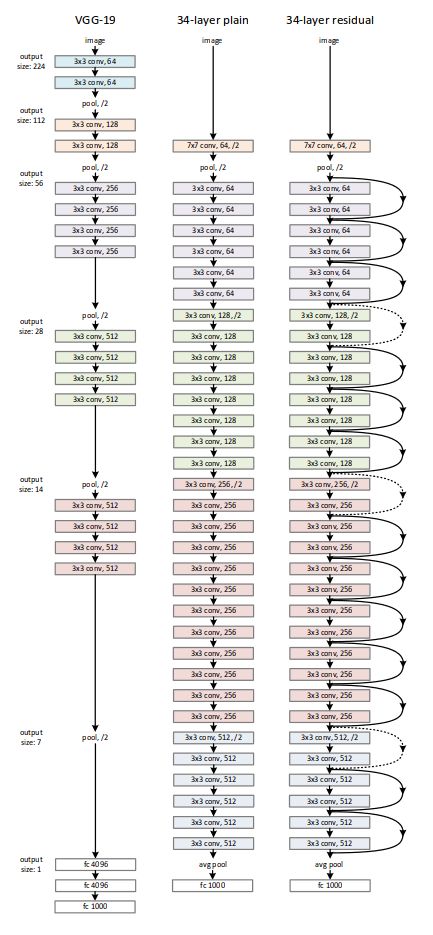
VGG和GoogLeNet 是同一时期的论文,VGG沿用了Alex框架,使用了dropout等手段加深了网络深度,并使用堆叠3x3卷积核代替7x7的网络。论文探讨了很多的调参技巧是再进行实验的时候比较有用的。
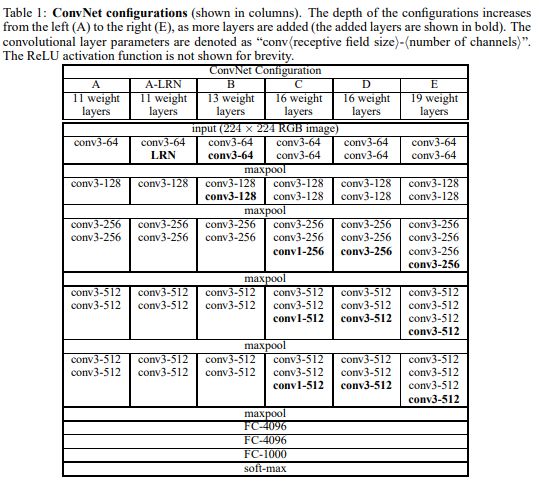
vgg一共进行了6次实验,其中D和E表现最佳。D就是VGG16网络,E是VGG19网络,所有的网络都是使用3x3卷积核。
Inception v2 + v3
这两个模型出现在同一篇论文中,主要探讨三个原则:
- 将 5×5 的卷积分解为两个 3×3 的卷积运算以提升计算速度
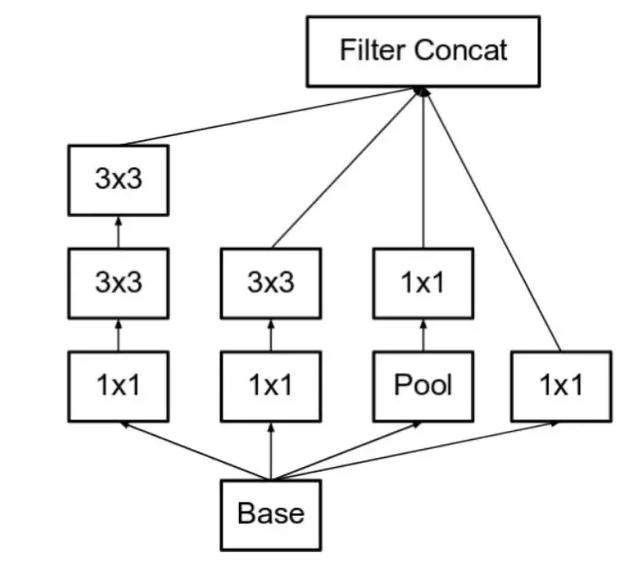
-
作者将 n*n 的卷积核尺寸分解为 1×n 和 n×1 两个卷积。例如,一个 3×3 的卷积等价于首先执行一个 1×3 的卷积再执行一个 3×1 的卷积。
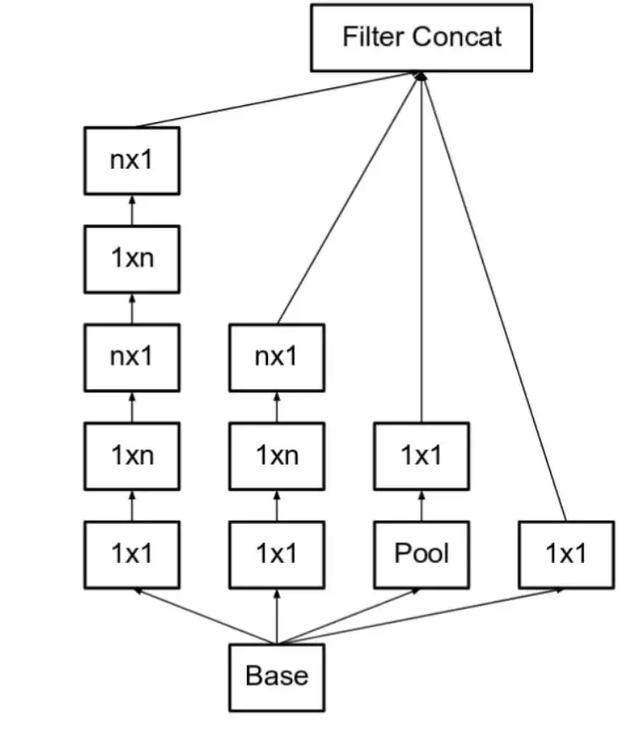
对于前面的串联改为并联

- inception v2的模型结构
其中v2/v3模型结构上的差别只有一点即在inception v3中使用的Aug loss里面使用了BN进行regularization。
ResNet
残差神经网络是一个卷积神经网络模型的大突破,直接解决了无法训练更深层的网络问题。
运用如下公式:
- 使用残差块对已经训练的的网络进行连接:
这里x使上层的网络,相当于已经拟合90%的模型,二F(x)就是残差块,这就是真实网络和x的一个残差(误差)。F(x) + x就像可以更加精确的拟合网络了。公式1中的x和F(x)的尺度不变。
若x和F(x)的尺度不一样,就需要使用公式2:
完整模型如下:
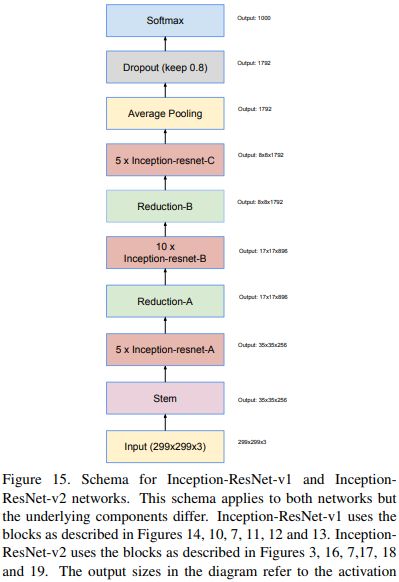
inception v4和 Inception-ResNet-v1,Inception-ResNet-v2
这三个个模型同时出现在一篇论文里面。论文中有大量的图和表,这是一篇实验性很强的论文,大部分在讨论模型的基础结构的功能,对比模型在分类和检测任务的性能。
Inception v4 引入了专用的「缩减块」(reduction block),它被用于改变网格的宽度和高度。早期的版本并没有明确使用缩减块,但也实现了其功能。
如下:

Inception-ResNet-v2和Inception-ResNet-v1结构类似如下:
受 ResNet 的优越性能启发,研究者提出了一种混合 inception 模块。Inception ResNet 有两个子版本:v1 和 v2。在分析其显著特征之前,先看看这两个子版本之间的微小差异。
- Inception-ResNet v1 的计算成本和 Inception v3 的接近。
- Inception-ResNetv2 的计算成本和 Inception v4 的接近。
- 它们有不同的 stem。两个子版本都有相同的模块 A、B、C 和缩减块结构。唯一的不同在于超参数设置。
参考:一文概览Inception家族的
ResNeXt
ResNeXt 结构可以在不增加参数复杂度的前提下提高准确率,同时还减少了超参数的数量。

文中提出网络 ResNeXt,同时采用 VGG 堆叠的思想和 Inception 的 split-transform-merge 思想,但是可扩展性比较强,可以认为是在增加准确率的同时基本不改变或降低模型的复杂度。这里提到一个名词cardinality,右边的 ResNeXt 中每个分支一模一样,分支的个数就是 cardinality。通过在大卷积核层两侧加入 1x1 的网络层,控制核个数,减少参数个数的方式。
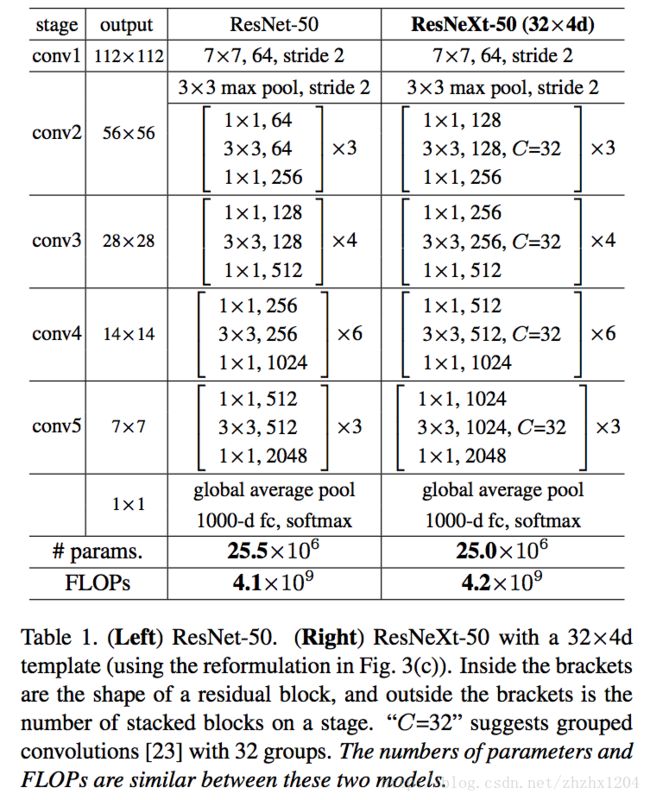
图中中括号内就是 split-transform-merge,通过 cardinality(C) 的值控制 repeat layer。
output 在上下相邻的格子不断减半,中括号内的逗号后面卷积核的个数不断翻倍。
参考:ResNeXt算法详解
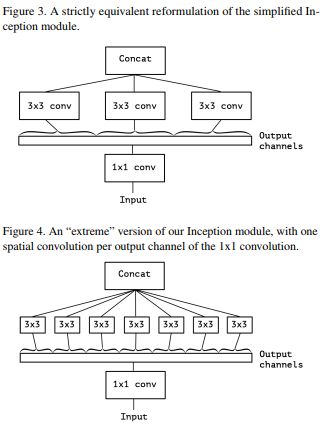
Xception
Xception网络结构,不仅借鉴了depthwise separable convolution的思想,也结合了ResNet的思想,最后作者也比较了ResNet在其中的作用
- 首先通过‘1x1’卷积,将输入数据拆分cross-channel相关性,拆分成3或者4组独立的空间
- 然后,通过‘3x3’或者‘5x5’卷积核映射到更小的空间上去
模型使用的残差块:
Xception模型结构:
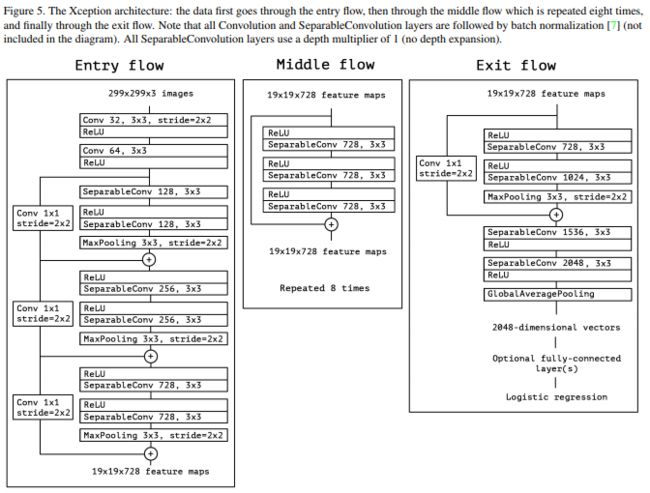
- 整个网络结构具有14个模块,36个卷积
- 残差连接
3.最后采用logistic regression
参考基础模型
DenseNet
DenseNet使RseNet上演变出来的又一个超级网络,网络设计了一种Dense Block模块。如下:

这里的Dense Block模块层数为5,即具有5个BN+Relu+Conv(3*3)这样的layer,网络增长率为k=4,简单的说就是每一个layer输出的feature map的维度为4。这里的网络增长率就是每层网络的的特征层输出数量。因为DenseNet的每层网络的输入是前面所有层的输出。所以这里要统一每层网络的输入层数k。
若k=32,第L 层网络的网络输入未 k0 + k(L-1).第L层的网络的输出为32.
- k0是网络的输入层的输出层数
- k是就是前面每层的网络输出。
网络结构:

这里有bottleneck layer和Translation layer。
- 这里bottleneck layer就是Dense Block的1x1结构,dense block的33卷积前面都包含了一个11的卷积操作,就是所谓的bottleneck layer,目的是减少输入的feature map数量,既能降维减少计算量,又能融合各个通道的特征,这里11卷积的channel是growth rate4
- 放在两个Dense Block中间,是因为每个Dense Block结束后的输出channel个数很多,需要用1*1的卷积核来降维。
参考1, 2, 3
SENet
Momenta 的胡杰一篇大作。
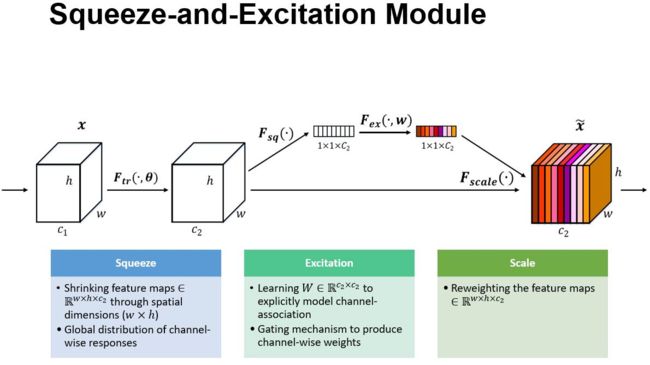
SE 模块的示意图。给定一个输入 x,其特征通道数为 c_1,通过一系列卷积等一般变换后得到一个特征通道数为 c_2 的特征。与传统的 CNN 不一样的是,接下来通过三个操作来重标定前面得到的特征。
首先是 Squeeze 操作,顺着空间维度来进行特征压缩,将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野,这一点在很多任务中都是非常有用的。
其次是 Excitation 操作,它是一个类似于循环神经网络中门的机制。通过参数 w 来为每个特征通道生成权重,其中参数 w 被学习用来显式地建模特征通道间的相关性。
最后是一个 Reweight 的操作,将 Excitation 的输出的权重看做是进过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。
在resnet和inception上的改动如下:

上左图是将 SE 模块嵌入到 Inception 结构的一个示例。方框旁边的维度信息代表该层的输出。
这里我们使用 global average pooling 作为 Squeeze 操作。紧接着两个 Fully Connected 层组成一个 Bottleneck 结构去建模通道间的相关性,并输出和输入特征同样数目的权重。我们首先将特征维度降低到输入的 1/16,然后经过 ReLu 激活后再通过一个 Fully Connected 层升回到原来的维度。这样做比直接用一个 Fully Connected 层的好处在于:1)具有更多的非线性,可以更好地拟合通道间复杂的相关性;2)极大地减少了参数量和计算量。然后通过一个 Sigmoid 的门获得 0~1 之间归一化的权重,最后通过一个 Scale 的操作来将归一化后的权重加权到每个通道的特征上。
除此之外,SE 模块还可以嵌入到含有 skip-connections 的模块中。上右图是将 SE 嵌入到 ResNet 模块中的一个例子,操作过程基本和 SE-Inception 一样,只不过是在 Addition 前对分支上 Residual 的特征进行了特征重标定。如果对 Addition 后主支上的特征进行重标定,由于在主干上存在 0~1 的 scale 操作,在网络较深 BP 优化时就会在靠近输入层容易出现梯度消散的情况,导致模型难以优化。
目前大多数的主流网络都是基于这两种类似的单元通过 repeat 方式叠加来构造的。由此可见,SE 模块可以嵌入到现在几乎所有的网络结构中。通过在原始网络结构的 building block 单元中嵌入 SE 模块,我们可以获得不同种类的 SENet。如 SE-BN-Inception、SE-ResNet、SE-ReNeXt、SE-Inception-ResNet-v2 等等。
参考1, 2
MobileNets
论文中的主要的思想是将一个标准卷积(standard convolution)分解成两个卷积,一个是深度卷积(depthwise convolution),这个卷积应用在每一个输入通道上;另一个是1×1的逐点卷积(pointwise convolution),这个卷积合并每一个深度卷积的输出
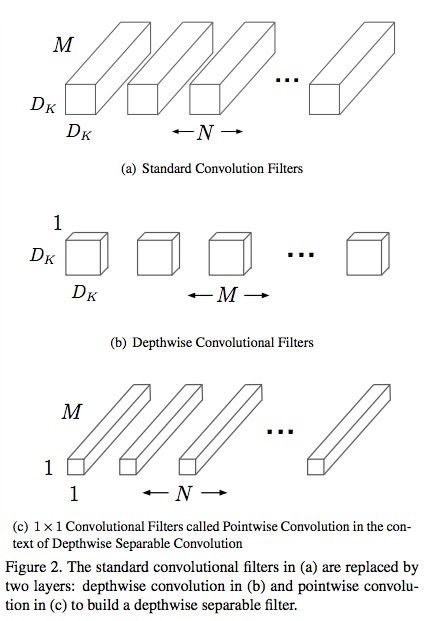
上图a就是标准的卷积核,它的大小就是DK×DK×M×N。它可以被分解为b和c这两个部分。
b的大小为M×(1×Dk×Dk)就是(depthwise convolution),c的大小为N×(M×1×1)就是(pointwise convolution).
既然卷积核分解了,那feature map也是要被分解的。
对一个DF×DF×M的特征图。需要分解为(M×DK×DK)×(DF×DF)这两个矩阵。
那怎么计算??
- feature map 先与depthwise convolution进行计算: M×(1×Dk×Dk) * (M×DK×DK)×(DF×DF) = M×(DF×DF)
- 再与pointwise convolution进行计算: N×(M×1×1) * (M×1×1)×(DF×DF) = N×(DF×DF)
如下:

左边标准卷积,右边是深度分离卷积。
总的结构:
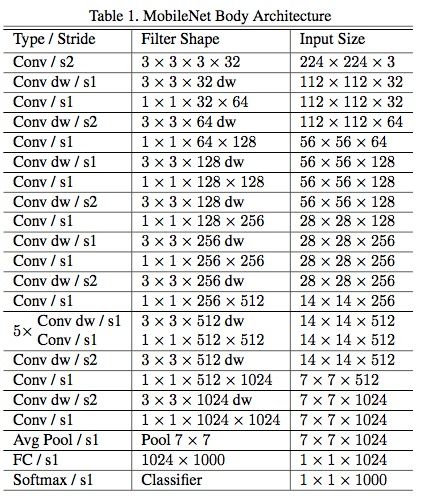
除了最后的全连接层,所有层后面跟了batchnorm和ReLU,最终输入到softmax进行分类。
- 为了构建更小和更少计算量的网络,作者引入了宽度乘数 ,作用是改变输入输出通道数,减少特征图数量,让网络变瘦。
- 分辨率乘数 ,分辨率乘数用来改变输入数据层的分辨率,同样也能减少参数。
参考:1, 2