oracle中sqlplus执行sql脚本文件
SQL>@c:\aaa.sql ;
一.查看执行计划的几种方法
询语句在ORACLE中的执行过程或访问路径的描述。
1.使用oracle工具查看执行计划的方法
SQL developer中按F10
PLSQL Developer中的按F6
2使用sqlplus查看执行计划的方法
创建PLAN_TABLE 表
创建和授予Plustrace 角色权限
SQL> @$ORACLE_HOME/sqlplus/admin/plustrce.sql
SQL> grant plustrace to scott;
自动跟踪语法:
1> set autotrace on --(得到执行计划,并输出结果)
2> set autotrace traceonly --(得到执行计划,但不输出结果)
3> set autotrace traceonly explain --(得到执行计划,不输出统计信息和结果,仅展现执行计划部分)常用
4> set autotrace traceonly statistics --(不输出执行计划和结果,仅展现统计信息)
更多方法可以参考http://blog.itpub.net/31557103/viewspace-2617700/
3.一条语句开启执行计划
explain plan for select from test
select from test
查询这条执行计划的结果
SELECT PLAN_TABLE_OUTPUT FROM TABLE(DBMS_XPLAN.DISPLAY());
4.通过awr报告查看执行计划br/>Step1:@?/rdbms/admin/awrsqrpt.sql
Step2:选择你要的断点(begin snap 和end snap)
Step3:输入sql_id
1.如果某SQL执行非常长时间才会出结果,甚至慢到返回不了结果,这时候看执行计划就只能用方法explain plan for;
2.跟踪某条SQL最简单的方法是方法explain plan for ,其次就是方法autotrace;
3.如果想观察到某条SQL有多条执行计划的情况,只能用方法dbms_xplan.display_cursor(sql_id)和方法awrsqlrpt.sql;
4.如果SQL中含有多函数,函数中套有SQL等多层递归调用,想准确分析,只能使用方法10046 trace;
5.要想确保看到真实的执行计划,不能用方法plsql developer和方法explain plan for;
6.要想获取表被访问的次数,只能使用方法statistics_level(/+ gather_plan_statistics /);
二.sql语句和索引
Oracle中主要有两种字符串类型:CHAR和VARCHAR2
CHAR始终为定长的,如果设置的值长度小于CHAR列的串值,会自动填充空格。在比较CHAR串时,会为双方都补满空格后再进行比较。
VARCHAR2数据类型为变长的字符串(VARCHAR与VARCHAR2为同义词)。
这里借鉴一个图表名一下常用函数
介绍数据库中三个类型函数
1.数值类型
1.abs() --取绝对值
2.ceil() --向上取最小整数
3.floor() --向下取最小整数
4.mod(n1,n2) n1/n2 --取余数
5.power(n1,n2) n1的n2次方 --次幂
6.sign() --取数字n的记号,大于0返回1,小于0返回-1,等于0返回0
7.round(1.123,2) --保留两位小数,四舍五入
8.trunc(1.123,2) --保留两位小数,不四舍五入
2.日期函数
1.sysdate --查看当前日期select sysdate from dual;
注:日期:oracle的是sysdate,mysql的是now(),sqlserver是getdate()
2.last_day 最后一天
select last_day(sysdate)from dual;--倒数第一天
select last_day(sysdate)-1 from dual;--倒数第二天
3.add_months(sysdate,2) --加两个月显示,做备份时用着比较爽
4.trunc(date,hh/mm/dd) --截取日期,参数 hh(年月日 时 ),mm(当前月的1号),dd(当前日子)
5.to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') --把数字或者日期转换为字符串
6.to_date() --把字符串转换为日期
7.next_day --NEXT_DAY(date,'day')--查询下一个星期的日期
3.聚合函数
--max 最大值 --min 最小值--count计算总行数 sum汇总 avg平均数 distinct 去重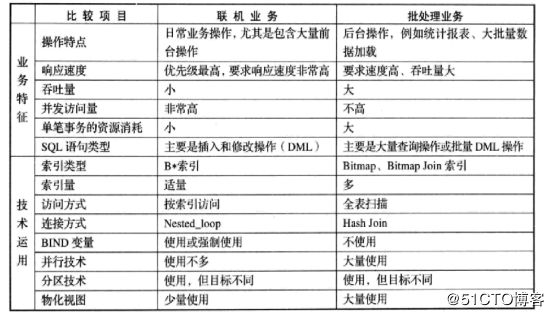
全表扫表的产生几个原因:
1.字段类型设计不合理,不应该对不定长的字符数据采用char定长类型,迫使应用软件大范围使用trim函数进行空格的截取,从而抑制了相关字段索引的使用,导致函数转换频繁。
2.本来使用日期类型,非要使用字符类型表示,导致在语句中大量使用转换函数。
3.查询条件中有null、like、多or、order by、多in等。右模糊查询可以使用索引。
4.查询时对索引字段进行计算、分割、等
5.count(*)和输入参数&、@等
小知识:in和exists的小区别,NOT EXISTS和NOT IN
select from A where id in(select id from B)
查询过程类似于以下过程
List resultSet=[]; Array A=(select from A); Array B=(select id from B);
for(int i=0;i
in()适合B表比A表数据小的情况
select a. from A a where exists(select 1 from B b where a.id=b.id)
List resultSet=[]; Array A=(select from A)
for(int i=0;i
exists()适合内表B表比外表A表数据大的情况。
注:in是把外表和内表作hash连接运算,而exists是对外表作loop循环,每次loop循环再对内表进行查询。
注:使用等值连接消除笛卡尔积,也是表表关联中最常用的,三张表时建议将两张表查询的结果在与第三表进行关联查询
即:表名.列名=表名.列名
select from test where exists (select empno from test);
select from test where empno in (select empno from test);
如果选取的数据不多的时候,可以使用表变量。
如果数据多,可以考虑建立一个带有index的临时表。
如果使用的<>和in等比较少时,可以考虑使用嵌套的with语句。
用in还是exists正式环境下跟前表和后表的数据量有关,还是建议用exists因为不用遍历整张表,可以提高查询的效率。
union 返回两个结果集,不显示重复项。
UNOIN ALL 返回两个结果集中的所有记录。
函数和存储过程的另类理解:
如果没有返回值就是函数,如果有返回值,就是存储过程。
创建存储过程:
CREATE OR REPLACE PROCEDURE 存储过程名
IS
begin
for i in 1..10
loop
insert into test1 (id,time) values (i,to_char(SYSDATE,'yyyymmddhh24miss'));
END LOOP;
commit;
END;
查看存储过程
SELECT * FROM user_source WHERE NAME = 'TEST2' ORDER BY line;--TEST2是存储过程名字
创建一个test2存储过程
CREATE OR REPLACE PROCEDURE test1
IS
--begin..end可以在PLSQL工具中直接执行,插入10条记录
begin
for i in 1..20
loop
insert into test1.TEST1 (id,create_date) values (i,to_char(SYSDATE-i));
END LOOP;
commit;
END;
SQL中使用命令调用存储过程 exec
SQL> exec test2
PL/SQL procedure successfully completed.
create or replace procedure test3
is
N number;
begin
select count(*) into N from test1;
dbms_output.put_line(N);
end;
begin
test3;
end;